Hot Standby ist ein Hochverfügbarkeitsdesign, bei dem ein Ersatzgerät, Server, Controller, Gateway oder eine Plattform eingeschaltet, synchronisiert und bereit bleibt, die aktive Einheit bei einem Ausfall zu übernehmen. Statt auf manuelle Reparatur oder Kaltstart zu warten, kann die Standby-Seite durch automatisches Failover die Dienstverantwortung übernehmen, Ausfallzeit reduzieren und kritische Systeme weiter betreiben.
Diese Funktion wird in Kommunikationsplattformen, Rechenzentren, industrieller Steuerung, Sicherheitssystemen, Energieinfrastruktur, Verkehr, Cloud-Diensten, Telekom-Gateways, Notfallsystemen und Unternehmensanwendungen eingesetzt. Der Kernwert liegt nicht nur in einer Ersatzmaschine; die Standby-Einheit muss verbunden, überwacht, synchronisiert und getestet sein, damit sie beim Ausfall des Produktionsknotens aktiv werden kann.
Vom Ersatzgerät zum Entwurf für Servicekontinuität
Ein klassisches Backup kann ungenutzt bleiben, bis ein Fehler eintritt. Hot Standby ist anders, weil das Ersatzelement bereits Teil der laufenden Architektur ist. Es überwacht Heartbeat-Signale, erhält Konfigurationsänderungen, verfolgt den Dienstzustand und bereitet die Übernahme mit möglichst geringer Unterbrechung vor.
Für Benutzer ist das Ziel einfach: Anrufe laufen weiter, Sitzungen werden wiederhergestellt, Alarme bleiben sichtbar, Steuerungssysteme bleiben verfügbar und Bediener müssen den Dienst nicht manuell neu aufbauen. Hinter dieser einfachen Erfahrung müssen Datensynchronisation, IP-Übernahme, Dienstzustand, Routing-Updates, Fehlererkennung und Wiederherstellungsreihenfolge gelöst werden.
In Geschäfts- und Industrieumgebungen ist Hochverfügbarkeit oft wichtiger als maximale Leistung. Ein etwas langsameres, aber dauerhaft verfügbares System kann wertvoller sein als ein leistungsstarkes System, das ohne Schutz vollständig ausfällt.
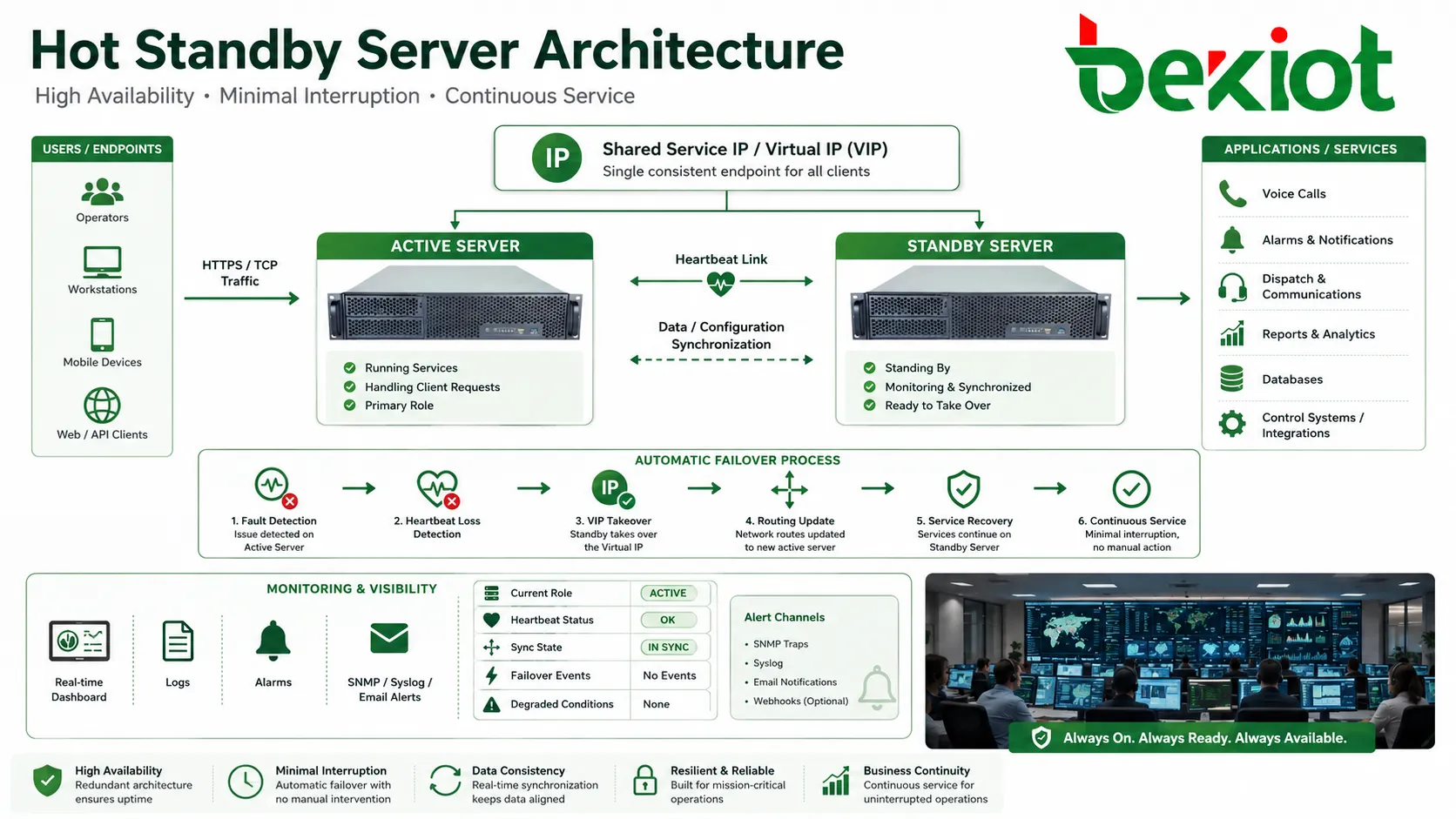
Wie der Übernahmeprozess funktioniert
Heartbeat-Erkennung
Aktive und Standby-Knoten tauschen normalerweise Heartbeat-Signale aus. Diese Signale bestätigen, dass beide Seiten leben und der Primärknoten weiter für den Dienst verantwortlich ist. Der Heartbeat-Verkehr kann über ein dediziertes Kabel, ein Managementnetz, ein privates VLAN oder einen redundanten Netzwerkpfad laufen.
Wenn der Standby-Knoten innerhalb eines definierten Zeitfensters keine gültigen Heartbeat-Nachrichten mehr empfängt, kann er einen Ausfall des aktiven Knotens vermuten. Dann beginnt die Failover-Logik. Sie muss sorgfältig entworfen sein, weil eine zu schnelle Reaktion auf kurzzeitige Netzverzögerungen falsche Umschaltungen auslösen kann.
Zustandssynchronisierung
Für einen reibungslosen Übergang benötigt die Standby-Seite aktuelle Informationen. Dazu gehören Konfigurationsdateien, Benutzerdaten, Routingtabellen, Sitzungsdaten, Anrufzustände, Alarmstatus, Datenbankeinträge, Lizenzzustand, Geräteregistrierungen oder Steuerungslogik.
Manche Systeme synchronisieren nur Konfiguration, andere auch den Echtzeit-Dienstzustand. Je tiefer die Synchronisierung, desto glatter kann das Failover sein. Gleichzeitig erhöhen Echtzeitsynchronisierung und Statusabgleich die Komplexität und die Abhängigkeit vom Netzwerk.
Fehlerentscheidung
Nach Erkennung eines möglichen Fehlers muss das System entscheiden, ob der aktive Knoten wirklich nicht verfügbar ist. Dazu können Heartbeat-Verlust, Prozesszustand, Festplatte, Schnittstellen, Datenbankantwort, CPU-Last, Stromalarme oder externe Überwachungssignale geprüft werden.
Ein gutes Design vermeidet Entscheidungen auf Basis einer einzigen Bedingung. Der Verlust eines Heartbeat-Links sollte beispielsweise keine automatische Übernahme auslösen, wenn ein anderer Managementpfad weiterhin bestätigt, dass der aktive Knoten gesund ist.
Rollenwechsel
Wenn Failover bestätigt ist, ändert der Standby-Knoten seine Rolle und wird aktiv. Er kann eine virtuelle IP übernehmen, Dienste starten, Routen ankündigen, sich bei Partnersystemen registrieren, Trunks aktivieren, Datenbank-Master werden oder Anrufe und Alarme verarbeiten.
Der frühere aktive Knoten kann isoliert, neu gestartet, repariert oder später als Standby-Knoten zurückgeführt werden. Das Wiederbeitreten muss kontrolliert werden, damit kein Dienstkonflikt entsteht.
Wichtige Architekturmodelle
Aktiv-Standby-Paar
Das häufigste Modell nutzt einen aktiven und einen Standby-Knoten. Die aktive Seite trägt den Produktionsdienst, während die Standby-Seite wartet und synchronisiert. Fällt die aktive Seite aus, übernimmt die Standby-Seite.
Dieses Modell ist leicht verständlich und wird in PBX-Systemen, Firewalls, Routern, Controllern, Datenbanken, Speichergeräten und Industrieplattformen verbreitet eingesetzt. Der Nachteil ist, dass die Standby-Ressource im Normalbetrieb oft wenig genutzt wird.
Dual Active mit Standby-Logik
Einige Umgebungen nutzen beide Knoten aktiv und bieten trotzdem Failover zwischen ihnen. Jeder Knoten trägt im Normalzustand einen Teil der Last, und eine Seite kann mehr Verkehr aufnehmen, wenn die andere ausfällt.
Dieses Design verbessert die Ressourcennutzung, verlangt jedoch sorgfältiges Load Balancing, Synchronisierung, Sitzungsbehandlung und Kapazitätsplanung. Wenn beide Knoten nahe der Volllast laufen, fehlt im Fehlerfall möglicherweise Reservekapazität.
Clusterbasierte Redundanz
Große Systeme können statt eines einfachen Zweierpaares einen Cluster verwenden. Mehrere Knoten teilen Dienste, überwachen einander und verteilen Arbeitslasten neu, wenn ein Mitglied ausfällt.
Clusterdesigns bieten bessere Skalierbarkeit und Resilienz, sind aber komplexer in Bereitstellung und Betrieb. Sie benötigen starke Koordination, Quorum-Kontrolle, Health Checks und konsistentes Konfigurationsmanagement.
Geografisch getrennte Absicherung
Einige kritische Systeme platzieren Standby-Ressourcen in einem anderen Gebäude, Campus, Rechenzentrum oder einer anderen Region. So schützen sie sich gegen lokalen Stromausfall, Feuer, Überschwemmung, Ausfall des Technikraums oder Störungen auf Standortebene.
Geografischer Schutz verbessert die Notfallwiederherstellung, bringt aber Latenz, Datenkonsistenz, Netzwerkrouting und operative Koordination als Herausforderungen mit sich. Nicht jeder Dienst kann über große Entfernung sauber umschalten.
| Modell | Beste Eignung | Wichtigster Entwurfsaspekt |
|---|---|---|
| Aktiv-Standby | Einfache Hochverfügbarkeitspaare für Server, Gateways, PBX-Plattformen und Controller. | Nutzung der Standby-Ressource und Failover-Zeitpunkt. |
| Dual Active | Systeme, die Lastverteilung und Redundanz gleichzeitig benötigen. | Kapazitätsreserve, Sitzungsverteilung und Failback-Steuerung. |
| Cluster | Große Plattformen mit mehreren Dienstknoten und skalierbaren Lasten. | Quorum, Synchronisierung, Split-Brain-Schutz und betriebliche Komplexität. |
| Remote-Site-Schutz | Disaster Recovery und Standortresilienz. | Latenz, Datenkonsistenz, Netzwerkrouting und Wiederherstellungsverfahren. |
Netzwerkelemente, die Zuverlässigkeit bestimmen
Heartbeat-Pfad
Der Heartbeat-Link sollte zuverlässig und möglichst redundant sein. Nutzt Heartbeat denselben instabilen Pfad wie normaler Dienstverkehr, kann der Standby-Knoten bei Überlast oder Switchausfall den Zustand falsch beurteilen.
Für kritische Installationen verwenden Planer oft zwei Heartbeat-Pfade, getrennte physische Links oder unterschiedliche Switchwege. Dadurch sinkt die Wahrscheinlichkeit, dass ein einzelner Netzfehler eine falsche Übernahme verursacht.
Virtuelle Serviceadresse
Viele Systeme nutzen eine virtuelle IP-Adresse oder eine schwebende Serviceadresse. Benutzer und Partnersysteme verbinden sich mit dieser stabilen Adresse statt mit der physischen Adresse eines Knotens. Beim Failover wandert die Adresse zur Standby-Seite.
Diese Methode vereinfacht Clientkonfigurationen, aber Netzwerkgeräte müssen ARP, Routing, DNS oder Sitzungstabellen schnell genug aktualisieren. Langsame Adressaktualisierung kann Failover verzögert erscheinen lassen, obwohl der Standby-Knoten bereits aktiv ist.
Gemeinsame oder replizierte Daten
Einige Systeme verwenden gemeinsamen Speicher, andere replizieren Daten zwischen Knoten. Gemeinsamer Speicher erleichtert Konsistenz, kann ohne Schutz aber ein Single Point of Failure werden. Replikation verbessert Unabhängigkeit, muss jedoch Verzögerung, Konflikte und unvollständige Schreibvorgänge behandeln.
Die richtige Methode hängt davon ab, ob Konfigurationskontinuität, Transaktionskonsistenz, Aufzeichnungsintegrität, Sitzungserhalt oder nur ein einfacher Dienstneustart benötigt wird.
Routing- und Trunk-Verhalten
Kommunikationssysteme können mit SIP-Trunks, Funk-Gateways, PSTN-Gateways, Dispatch-Konsolen, externen APIs, Überwachungsplattformen und entfernten Endpunkten verbunden sein. Diese externen Systeme müssen nach dem Failover wissen, wohin der Verkehr zu senden ist.
Wird der Standby-Knoten aktiv, aber Trunks, Routen oder Peer-Registrierungen werden nicht aktualisiert, erleben Benutzer weiterhin Unterbrechungen. Failover-Tests müssen deshalb Upstream- und Downstream-Systeme einschließen, nicht nur die zwei lokalen Knoten.
Management- und Überwachungsschicht
Hochverfügbarkeit muss für Administratoren sichtbar sein. Dashboards, Logs, Alarme, SNMP-Traps, Syslog, E-Mail-Warnungen oder Monitoringplattformen sollten aktuelle Rolle, Heartbeat-Zustand, Synchronisierung, Failover-Ereignisse und degradierte Zustände anzeigen.
Ohne Überwachung kann ein System wochenlang unbemerkt auf der Standby-Seite laufen. Tritt danach ein weiterer Fehler auf, bleibt möglicherweise kein Schutz mehr übrig.
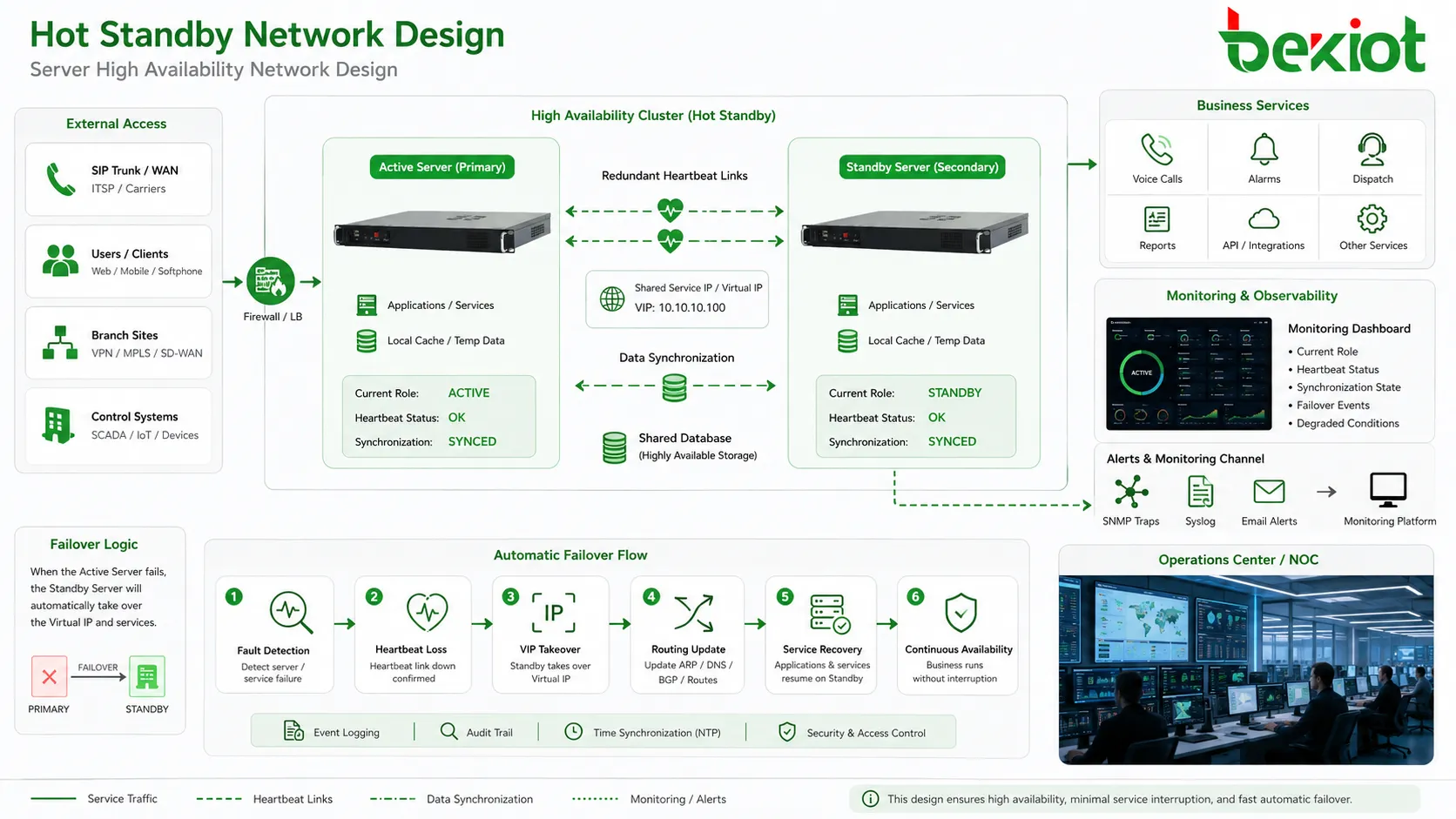
Wichtige technische Funktionen
Automatisches Failover
Automatisches Failover erlaubt der Standby-Seite, ohne manuelles Eingreifen aktiv zu werden. Das ist wesentlich, wenn das System Echtzeitkommunikation, Sicherheitsalarme, Steuerungsabläufe oder kundennahe Dienste unterstützt.
Der Failover-Schwellenwert muss sorgfältig eingestellt werden. Ist er zu empfindlich, entstehen falsche Failover; ist er zu träge, erleben Benutzer unnötige Ausfallzeit.
Manuelle Umschaltung
Manuelle Umschaltung erlaubt Administratoren, den Dienst während Wartung, Upgrades, Tests oder geplanter Reparaturen von einem Knoten auf den anderen zu verlegen. Sie hilft beim Hardwaretausch, Patchen oder bei der Prüfung der Standby-Bereitschaft.
Eine kontrollierte Umschaltung ist sicherer als das Warten auf einen ungeplanten Fehler, weil Teams die Maßnahme planen, das Ergebnis überwachen und bei Bedarf zurückrollen können.
Failback-Steuerung
Nach Reparatur des ursprünglichen aktiven Knotens muss das System entscheiden, ob der Dienst automatisch zurückkehrt oder bis zu einem geplanten Fenster auf dem aktuellen Knoten bleibt. Automatisches Failback kann die ursprüngliche Struktur schnell wiederherstellen, aber auch eine weitere Unterbrechung verursachen.
Viele kritische Systeme bevorzugen manuelles Failback, damit Bediener Gesundheit, Synchronisierung und Verkehr prüfen können, bevor der Dienst erneut verschoben wird.
Split-Brain-Vermeidung
Split-Brain entsteht, wenn beide Knoten gleichzeitig glauben, aktiv zu sein. Das kann doppelte Dienste, Datenbankkonflikte, fehlerhaftes Call Routing, IP-Adresskonflikte oder Datenkorruption verursachen.
Vorbeugende Maßnahmen sind Quorum-Mechanismen, Witness-Knoten, Fencing, Prioritätsregeln, redundante Heartbeat-Links und strenge Rollenkontrolle. Split-Brain-Schutz gehört zu den wichtigsten Teilen jedes Hochverfügbarkeitsdesigns.
Schutz der Datenintegrität
Während des Failovers muss das System Konfigurations- und Betriebsdaten schützen, etwa Datenbanktransaktionen, Anrufdatensätze, Alarmlogs, Registrierungszustände von Geräten, Aufzeichnungen und Ereignisverlauf.
Datenintegrität ist besonders wichtig, wenn das System Compliance, Abrechnung, Notfallnachweise, Dispatch-Logs oder Audit-Trails unterstützt.
Wo diese Architektur eingesetzt wird
Unternehmenskommunikationsplattformen
PBX-Server, SIP-Plattformen, Voicemail, Aufzeichnungsserver, Contact-Center-Systeme und Unified-Communications-Plattformen können Standby-Schutz nutzen, um Geschäftstelefonie aufrechtzuerhalten. Fällt der aktive Server aus, kann die Ersatzseite Registrierungen, Anrufe, Routingregeln und Dienstlogik weiterverarbeiten.
In kritischen Kommunikationsprojekten wendet Becke Telcom Hochverfügbarkeitsdenken bei der Planung von Kommunikationssystemen an und hilft Kunden, Serverredundanz, Gateway-Kontinuität, Dispatch-Verfügbarkeit und Failover-Pfade als Teil der Gesamtlösung zu betrachten.
Industriesteuerung und SCADA
Industriesysteme nutzen häufig Standby-Controller, redundante SCADA-Server, doppelte Kommunikations-Gateways und Ersatz-Bedienplätze. Diese Systeme unterstützen Produktion, Sicherheit, Energie, Versorgungsanlagen und Prozessüberwachung.
Failover sollte unter realen Prozessbedingungen getestet werden. Ein Steuerungssystem, das im Labor korrekt umschaltet, kann sich anders verhalten, wenn es mit Feldgeräten, PLCs, Historian-Systemen, Alarmen und Bedienkonsolen verbunden ist.
Sicherheits- und Überwachungssysteme
Videomanagementserver, Zutrittskontrollplattformen, Alarmserver, Speicherknoten und Leitstellensysteme können Standby-Schutz benötigen, um Blindstellen oder verzögerte Sicherheitsreaktionen zu vermeiden.
In solchen Umgebungen muss das Failover-Design Live-Video, Aufzeichnungskontinuität, Türsteuerung, Alarmquittierung, Ereignislogs und Bedienerrechte berücksichtigen.
Rechenzentren und Cloud-Dienste
Server, Datenbanken, Firewalls, Load Balancer, Speicherarrays, Router und Anwendungsplattformen nutzen häufig Hochverfügbarkeitsarchitektur. Standby-Schutz kann auf Hardware-, Virtualisierungs-, Container-, Datenbank- oder Anwendungsebene existieren.
Je mehr Ebenen beteiligt sind, desto wichtiger ist es festzulegen, welche Ebene für Failover verantwortlich ist. Mehrere unabhängige Failover-Mechanismen können ohne sorgfältige Planung miteinander kollidieren.

Öffentliche Sicherheit und Verkehr
Notrufzentren, Bahnsysteme, Tunnelkontrollräume, Flughafenbetriebe, Hafenleitstellen und Verkehrsmanagementplattformen brauchen hohe Dienstverfügbarkeit. Kommunikationsausfall kann Reaktion verzögern, Lagebewusstsein reduzieren oder Koordination unterbrechen.
Für diese Systeme muss Redundanz nicht nur Server, sondern auch Stromversorgung, Switches, Trunks, Endpunkte, Bedienplätze und externe Schnittstellen umfassen.
Bereitstellungsvorteile über weniger Ausfallzeit hinaus
Der offensichtlichste Vorteil ist Dienstkontinuität. Wenn der Primärknoten ausfällt, können Benutzer mit weniger Unterbrechung weiterarbeiten; das ist wichtig für Sprachkommunikation, Alarme, Monitoring, Datenzugriff und Steuerungsfunktionen.
Ein weiterer Vorteil ist Flexibilität bei geplanter Wartung. Administratoren können den Dienst auf die Standby-Seite verlegen, den ursprünglichen Knoten warten und nach Prüfung wieder in die normale Rolle bringen, wodurch lange Servicefenster reduziert werden.
Standby-Design erhöht auch das Vertrauen in Systemupgrades. Wenn ein Update auf einer Seite Probleme verursacht, kann die Organisation einen kontrollierten Weg zur Wiederherstellung haben, sofern Architektur und Rollback-Plan korrekt gestaltet sind.
Für Managementteams unterstützt Hochverfügbarkeit die Risikokontrolle. Ein einzelner Geräteausfall wird von einem Totalausfall zu einem verwaltbaren Ereignis, das mit geringerer Geschäftsunterbrechung untersucht und behoben werden kann.
Praktische Fehlerszenarien
Hardwarefehler
Ein Server, Netzteil, Datenträger, Interfacekarte, Gateway oder Controller kann ausfallen. Der Standby-Knoten sollte erkennen, dass der aktive Dienst nicht mehr gesund ist, und gemäß Richtlinie übernehmen.
Hardwareausfall ist oft das am einfachsten zu verstehende Szenario, aber nicht immer die häufigste Ursache für Dienstunterbrechung.
Absturz eines Anwendungsprozesses
Die Maschine kann eingeschaltet bleiben, während die Dienstanwendung nicht mehr reagiert. Ein guter Health Check muss nicht nur erkennen, ob der Server lebt, sondern auch ob der Dienst selbst funktioniert.
Nur Ping-Antworten zu prüfen reicht meist nicht aus. Das System kann Ping beantworten, während Call Engine, Datenbank, Alarmprozess oder Webdienst bereits ausgefallen sind.
Netzwerkisolation
Ein Knoten kann von Benutzern isoliert sein und sich trotzdem für gesund halten. Das ist gefährlich, weil das System dann möglicherweise nicht weiß, welche Seite aktiv sein soll.
Redundante Netzwerkpfade und Quorum-Logik helfen, falsche Entscheidungen bei Isolationsereignissen zu vermeiden.
Datenbankbeschädigung
Wenn Daten auf der aktiven Seite beschädigt und sofort zur Standby-Seite repliziert werden, löst Redundanz allein das Problem nicht. Backup und versionierte Wiederherstellung bleiben nötig.
Hochverfügbarkeit ist nicht dasselbe wie Backup. Ein Standby-Knoten schützt Dienstkontinuität, während Backup historische Wiederherstellung schützt.
Bedienfehler
Falsche Konfiguration, versehentliches Löschen, fehlerhaftes Routing oder ein misslungenes Upgrade können beide Knoten betreffen, wenn die Konfiguration automatisch synchronisiert wird.
Change Control, Genehmigungsabläufe, Konfigurationsexport und Rollback-Pläne sind entscheidend, um Auswirkungen menschlicher Fehler zu reduzieren.
Hochverfügbarkeit verringert Ausfallzeit durch Komponentenfehler, ersetzt aber nicht Backup, Cybersicherheit, Change Control, Monitoring oder disziplinierte Wartung.
Test- und Abnahmestrategie
Failover sollte vor der Produktionsübergabe getestet werden. Ein Test muss bestätigen, dass die Standby-Seite Fehler erkennt, den Dienst übernimmt, Netzwerkpfade aktualisiert, externe Verbindungen wiederherstellt, erforderliche Daten bewahrt und geeignete Alarme erzeugt.
Tests sollten geplante Umschaltung, Abschaltung des aktiven Knotens, Dienstprozessfehler, Linkausfall, sicheren Stromausfall und Wiederherstellung nach Reparatur umfassen. Jeder Test muss erwartetes Verhalten und maximal zulässige Unterbrechung definieren.
Abnahmeprotokolle sollten Failover-Zeit, Ergebnis der Datenkonsistenz, Dienstverfügbarkeit, Alarmaufzeichnungen, Lognachweise, Bedienerbestätigung und offene Punkte enthalten. Ohne Nachweise kann ein System redundant wirken, ohne bewiesen zu sein.
Betriebs- und Wartungsrichtlinien
Der Standby-Zustand muss kontinuierlich überwacht werden. Ein eingeschalteter, aber nicht synchroner Standby-Knoten ist nicht bereit. Administratoren sollten Heartbeat, Replikationsverzug, Ressourcen, Dienststatus, Lizenzgültigkeit, Speicherkapazität und Versionsgleichheit beobachten.
Beide Seiten müssen vorsichtig aktualisiert werden. Versionsunterschiede können Failover verhindern oder unerwartetes Verhalten verursachen; Updates sollten gestaffelt und getestet werden, damit ein fehlerhaftes Upgrade nicht beide Knoten gleichzeitig beschädigt.
Regelmäßige Umschaltübungen sind erforderlich. Ein System, das nie kontrolliert getestet wurde, funktioniert möglicherweise bei einem echten Fehler nicht; Übungen helfen auch Bedienern, Ablauf und Reaktionszeit zu verstehen.
Nach jedem Failover sollten Logs geprüft werden. Auch wenn der Dienst normal erscheint, muss die Ursache untersucht werden; wiederholte Ereignisse können auf Netzinstabilität, Überlast, Hardwareverschleiß oder schlechte Health-Check-Schwellen hinweisen.
FAQ
Ist Hot Standby dasselbe wie Backup?
Nein. Ein Standby-Knoten dient der Dienstkontinuität, ein Backup der Datenwiederherstellung. Meist benötigt ein System beides, weil Failover keine alten Versionen beschädigter oder gelöschter Daten zurückholt.
Wie schnell sollte Failover erfolgen?
Die akzeptable Zeit hängt von der Anwendung ab. Sprach-, Steuerungs-, Alarm- und Public-Safety-Systeme benötigen meist schnellere Wiederherstellung als normale Reporting- oder Archivsysteme.
Schützt ein Standby-System vor Softwarefehlern?
Nur manchmal. Wenn derselbe Fehler auf beiden Knoten vorhanden ist, löst Failover das Problem nicht. Versionskontrolle, Tests, Rollback und Backup bleiben wichtig.
Was verursacht Split-Brain?
Split-Brain wird häufig durch Heartbeat-Verlust, Netzwerkisolation, schwaches Quorum-Design oder falsche Failover-Regeln verursacht. Es tritt auf, wenn mehr als ein Knoten glaubt, aktiv sein zu müssen.
Was ist nach einem Failover zu prüfen?
Nach einem Failover sollten aktive Rolle, Standby-Gesundheit, Synchronisierung, Dienstlogs, Benutzerauswirkung, Datenintegrität, externe Trunks oder Schnittstellen, Alarmaufzeichnungen und die Ursache geprüft werden.