Als Uptime wird die Zeitspanne bezeichnet, in der ein System, Dienst, Gerät, Anwendung, Netzwerk oder Plattform verfügbar und funktionsfähig ist. Einfach ausgedrückt zeigt sie Nutzern, wie lange ein technisches System ohne Unterbrechung arbeitet. Wenn eine Website erreichbar ist, ein Server läuft, eine Kommunikationsplattform online ist oder ein Netzwerkgerät normal funktioniert, zählt diese Betriebszeit zur Uptime.
Die Uptime ist einer der wichtigsten Indikatoren für Zuverlässigkeit in der IT, Netzwerktechnik, Telekommunikation, Cloud-Diensten, industriellen Systemen, Websites, Rechenzentren, Sicherheitsplattformen und der Geschäftskommunikation. Sie hilft Unternehmen zu erkennen, ob ihre Systeme zuverlässig genug für den täglichen Betrieb sind. Ein Dienst mit hoher Uptime ist fast durchgehend verfügbar, während ein Dienst mit niedriger Uptime häufig unter Ausfällen, Neustarts oder Ausfallzeiten leidet.
Im praktischen Betrieb ist die Uptime mehr als nur ein technischer Wert. Sie beeinflusst die Kundenerfahrung, die Geschäftskontinuität, den Ruf eines Dienstes, die Notfallreaktion, die Produktivität und das Vertrauen in die IT-Systeme. Wenn ein System genau dann nicht verfügbar ist, wenn Nutzer es benötigen, verliert selbst eine leistungsstarke Funktionsausstattung ihren praktischen Nutzen. Aus diesem Grund wird die Uptime immer zusammen mit Überwachung, Redundanz, Wartungsplanung, Service-Level-Agreements und Notfallwiederherstellung betrachtet.
Was ist Uptime?
Definition und Kernbedeutung
Uptime beschreibt den Zeitraum, in dem ein System oder Dienst funktionsfähig und nutzbar ist. Sie gilt für Server, Router, Switches, Websites, Anwendungen, Datenbanken, Cloud-Plattformen, IP-Telefonanlagen, Sicherheitssysteme, industrielle Steuerungen und alle angeschlossenen Geräte, auf die Nutzer angewiesen sind. Ein System gilt als betriebsbereit, wenn es erreichbar ist und wie vorgesehen funktioniert.
Der Kern der Uptime ist die dauerhafte Verfügbarkeit. Es reicht nicht aus, dass ein Gerät nur mit Strom versorgt wird. Ein Server kann eingeschaltet sein, aber keine Nutzeranfragen beantworten. Ein Netzwerkgerät kann laufen, aber Daten nicht korrekt weiterleiten. Eine Website kann teilweise laden, aber ihre Hauptfunktionen nicht erfüllen. Für eine sinnvolle Uptime-Messung muss das System den zugehörigen Dienst tatsächlich bereitstellen.
Daher muss die Uptime immer passend zum eigentlichen Zweck des Systems definiert werden. Bei einer Website prüft die Messung die Seitenantwort, bei einem Kommunikationsdienst die Anmeldung, Signalisierung und Verbindungsaufnahme, bei einer Datenbank die Abfrageantwort und bei einem Überwachungssystem die Datenerfassung und Alarmverfügbarkeit.
Bei der Uptime geht es nicht nur darum, ob ein Gerät eingeschaltet ist. Sondern darum, ob der benötigte Dienst genau dann verfügbar ist, wenn Nutzer ihn brauchen.
Uptime im Vergleich zur Verfügbarkeit
Uptime und Verfügbarkeit sind eng miteinander verbunden und im Alltag oft synonym verwendet. Dennoch ist die Verfügbarkeit eine umfassendere Kennzahl. Die Uptime beschreibt, wie lange ein System betriebsbereit ist, während die Verfügbarkeit zusätzlich prüft, ob das System unter realen Bedingungen die benötigte Funktion für Nutzer bereitstellt.
Beispielsweise kann ein Server-Prozess laufen, aber Nutzer können aufgrund eines Netzwerkproblems nicht darauf zugreifen – der Dienst ist dann nicht verfügbar. In diesem Fall hat der Server zwar Uptime, aber der nutzerseitige Dienst ist nicht vollständig verfügbar. Dieser Unterschied ist entscheidend in komplexen Systemen mit vielen zusammenwirkenden Komponenten.
In der praktischen Diensteverwaltung konzentrieren sich Unternehmen vor allem auf die nutzerperzipierte Verfügbarkeit. Der Dienst muss aus der Sicht des Nutzers funktionieren – nicht nur auf dem lokalen Statusbildschirm des Geräts.

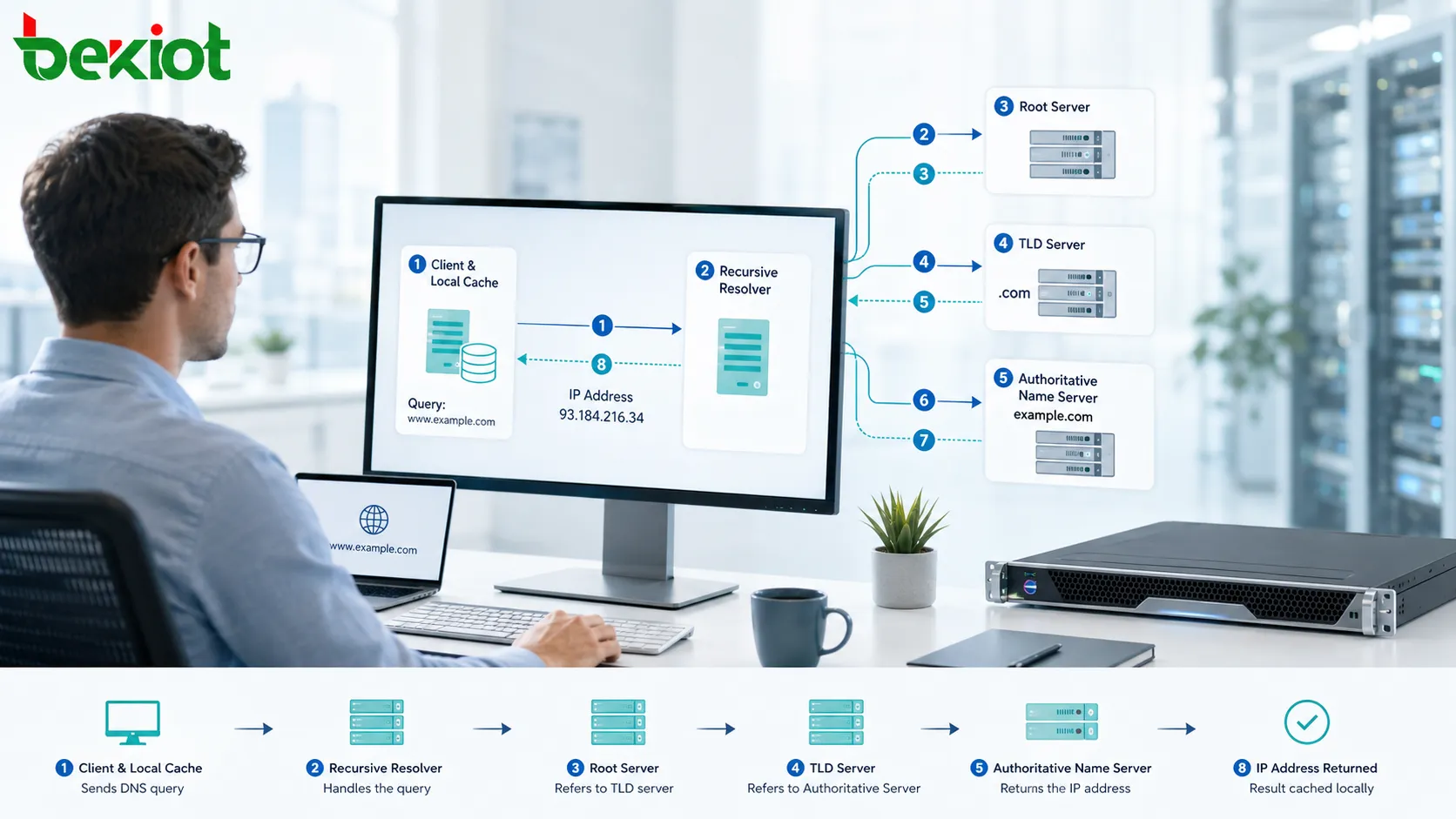
Wie funktioniert die Uptime?
Messung der Betriebszeit
Die Uptime wird ermittelt, indem die Dauer gemessen wird, in der ein System in einem funktionsfähigen und verfügbaren Zustand verbleibt. Die Messung kann ab dem Systemstart, dem Dienstbeginn, der Überwachungsantwort oder einem festgelegten Verfügbarkeitsfenster erfolgen. Die Methode hängt davon ab, was genau gemessen wird und was das Unternehmen als betriebsbereit definiert.
Bei einem einzelnen Gerät wird die Uptime oft als Zeit seit dem letzten Neustart angezeigt. Bei einer Website prüfen externe Sonden, ob die Seite korrekt antwortet. Bei einem Netzwerkdienst zählt, ob Nutzer sich verbinden, anmelden, Daten austauschen und Transaktionen durchführen können.
Die sinnvollste Uptime-Messung bezieht sich auf das Dienstverhalten. Ein System, das technisch läuft, aber seine Hauptfunktion nicht erfüllt, darf in einem ernsthaften Betriebsmodell nicht als vollständig verfügbar gezählt werden.
Erfassung von Ausfallzeiten und Verfügbarkeits-Prozentsatz
Die Uptime wird üblicherweise als Prozentsatz für einen festgelegten Zeitraum wie einen Monat oder ein Jahr angegeben. Die Grundformel vergleicht die verfügbare Zeit des Systems mit der gesamten Messzeit. Ein Dienst, der fast den gesamten Zeitraum verfügbar ist, hat einen hohen Uptime-Prozentsatz – bei langen Ausfällen sinkt dieser Wert.
Beispielsweise hat ein Dienst mit 99,9 % Uptime im Monat deutlich weniger Ausfallzeit als einer mit 99 %. Diese Prozentsätze scheinen nah beieinander zu liegen, aber der Unterschied in der tatsächlichen Ausfallzeit ist erheblich. Kleine prozentuale Unterschiede sind besonders wichtig für Systeme, die Geschäftsabläufe, Kundenzugänge oder kritische Kommunikation unterstützen.
Aus diesem Grund wird die Uptime häufig in Service-Level-Agreements festgeschrieben. Ein Anbieter verpflichtet sich zu einem bestimmten Prozentsatz, und Kunden nutzen diese Angabe, um die zu erwartende Zuverlässigkeit einzuschätzen.
Der Uptime-Prozentsatz wirkt einfach, aber kleine Unterschiede bedeuten sehr unterschiedliche tatsächliche Ausfallzeiten.
Übliche Uptime-Stufen und ihre Bedeutung
Verständnis von 99 %, 99,9 % und 99,99 % Uptime
Die Uptime wird oft anhand der Anzahl der Neunen beschrieben. Ein System mit 99 % Uptime ist meist verfügbar, erlaubt aber über ein Jahr hinweg erhebliche Ausfallzeiten. Ein System mit 99,9 % ist zuverlässiger und hat weit weniger Ausfälle. Ein System mit 99,99 % Uptime stellt höchste Anforderungen und benötigt eine stabilere Architektur, bessere Überwachung und strengere Betriebsdisziplin.
Je höher das Uptime-Ziel, desto schwieriger ist es zu erreichen. Der Sprung von 99 % auf 99,9 % erfordert bessere Überwachung und Wartung. Der Wechsel von 99,9 % auf 99,99 % braucht zusätzlich Redundanz, automatische Übernahme, Hochverfügbarkeitsarchitektur, verbessertes Änderungsmanagement und schnellere Störungsbehebung.
Bei der Planung sollten Unternehmen Uptime-Ziele nicht nur nach ihrem Eindruck auswählen, sondern an Geschäftsrisiken, Kosten, Nutzererwartungen und betrieblicher Bedeutung anpassen.
Warum höhere Uptime mehr kostet
Eine höhere Uptime erfordert fast immer mehr Investitionen. Ein einzelner Server ohne Redundanz ist einfach und kostengünstig einzusetzen, hat aber klare Ausfallpunkte. Ein hochverfügbares System braucht Ersatzserver, redundante Stromversorgung, mehrere Netzwerkpfade, Lastverteiler, ausfallsichere Datenbanken, Überwachungstools und qualifiziertes Betriebspersonal.
Die Kosten gehen über Hardware hinaus: Sie umfassen Planung, Tests, Wartungsverfahren, Mitarbeiterschulungen, Softwarearchitektur, Störungsreaktion und manchmal geografische Redundanz. Jede zusätzliche Schicht verbessert die Widerstandsfähigkeit, erhöht aber auch die Komplexität.
Daher sollte die Uptime als Konstruktionsanforderung gelten – nicht nur als Marketingaussage. Der benötigte Zuverlässigkeitsgrad muss durch echte Architektur und Betriebsprozesse gestützt werden.

Wichtige Faktoren, die die Uptime beeinflussen
Hardware-Zuverlässigkeit und Stromstabilität
Die Hardware-Zuverlässigkeit ist einer der grundlegendsten Faktoren für die Uptime. Server, Speichergeräte, Switches, Router, Netzteile, Lüfter, Festplatten und andere physische Komponenten können ausfallen. Fällt eine kritische Komponente ohne Ersatz aus, unterbricht das den Dienst.
Die Stromstabilität ist ebenso wichtig. Selbst leistungsstarke Systeme fallen bei Unterbrechungen oder instabilem Strom aus. Rechenzentren und kritische Anlagen nutzen unterbrechungsfreie Stromversorgungen, Backup-Generatoren, doppelte Stromspeisung und Stromüberwachung, um dieses Risiko zu mindern.
Selbst in kleineren Umgebungen verbessern einfache Maßnahmen wie zuverlässiger Stromschutz und gepflegte Geräte die Uptime deutlich.
Netzwerkkonnektivität und Routing-Stabilität
Die Netzwerkkonnektivität beeinflusst die Uptime stark, da viele Dienste auf die Erreichbarkeit über lokale Netze, Weitverkehrsnetze oder das Internet angewiesen sind. Ein Server kann einwandfrei laufen, aber bei einem Netzwerkausfall haben Nutzer trotzdem Ausfälle. Switch-Ausfälle, Routing-Fehler, DNS-Probleme, falsche Firewall-Konfigurationen und ISP-Ausfälle beeinträchtigen die Dienstverfügbarkeit.
Redundante Netzwerkverbindungen, mehrere Anbieter, durchdachtes Routing-Design, sauberes DNS-Management und kontinuierliche Überwachung verbessern die Uptime. In Geschäftskommunikationssystemen ist die Netzwerkstabilität besonders wichtig, da Sprache, Video, Nachrichten und Cloud-Anwendungen auf zuverlässige Verbindungen angewiesen sind.
Praktischerweise sollte die Uptime über den gesamten Dienstpfad gemessen werden – nicht nur am Hauptgerät.
Uptime und Systemarchitektur
Redundanz und automatische Übernahme (Failover)
Redundanz ist eine der häufigsten architektonischen Methoden zur Verbesserung der Uptime. Sie bedeutet, dass Ersatzkomponenten oder -pfade bereitstehen, wenn die Hauptkomponente ausfällt. Dazu gehören redundante Server, Netzteile, Festplatten, Switches, Netzwerkverbindungen, Datenbanken, Gateways oder Rechenzentren.
Failover ist der Vorgang, bei dem der Dienst von der ausgefallenen auf die Ersatzkomponente umgeschaltet wird. In einem gut konstruierten System geschieht dies automatisch mit kaum spürbarer Unterbrechung für Nutzer. Bei einfacheren Systemen ist eine manuelle Eingriff erforderlich.
Redundanz und Failover beseitigen nicht alle Risiken, senken aber die Wahrscheinlichkeit, dass ein einziger Fehler den gesamten Dienst stoppt. Sie sind unverzichtbar in Systemen, bei denen Ausfälle erhebliche Geschäfts- oder Sicherheitsauswirkungen haben.
Lastverteilung und Hochverfügbarkeits-Design
Die Lastverteilung unterstützt die Uptime, indem sie den Datenverkehr auf mehrere Server oder Dienstinstanzen verteilt. Wenn ein Server überlastet ist oder ausfällt, übernehmen andere Server die Anfragen. Bei korrekter Implementierung verbessert dies sowohl Leistung als auch Widerstandsfähigkeit.
Das Hochverfügbarkeits-Design kombiniert mehrere Techniken: Redundanz, Failover, Clusterbildung, Replikation, Funktionsprüfungen, automatische Wiederherstellung und Überwachung. Ziel ist es, den Dienst verfügbar zu halten, selbst wenn einzelne Komponenten ausfallen.
Ein hochverfügbares System muss sorgfältig getestet werden. Redundante Komponenten sind nur nützlich, wenn sie im Fehlerfall korrekt übernehmen.
Uptime entsteht durch Architektur, nicht durch Hoffnung. Ein zuverlässiges System braucht Ausfallwege, die vor einem Fehler geplant und getestet wurden.
Uptime-Überwachung
Interne und externe Überwachung
Die Uptime-Überwachung prüft, ob ein System oder Dienst verfügbar ist. Die interne Überwachung beobachtet Komponenten aus der Umgebung heraus: Server-CPU, Arbeitsspeicher, Festplattenzustand, Prozessstatus, Datenbankzustand und lokale Netzwerkkonnektivität. Die externe Überwachung prüft den Dienst von außen, aus der Nutzerperspektive.
Beide Methoden sind wertvoll. Die interne Überwachung erkennt frühe Fehlerzeichen, bevor Nutzer betroffen sind. Die externe Überwachung bestätigt, ob der Dienst von außen tatsächlich erreichbar ist. Ein System kann intern gesund wirken, aber durch DNS-, Routing-, Firewall- oder vorgelagerte Netzwerkprobleme unzugänglich sein.
Eine starke Überwachungsstrategie kombiniert interne und externe Prüfungen für ein vollständiges Bild der Uptime.
Funktionsprüfungen, Alarme und Störungsreaktion
Funktionsprüfungen sind automatisierte Tests, die bestätigen, ob ein System wie erwartet arbeitet. Eine einfache Prüfung überprüft die Server-Antwort, eine fortgeschrittene prüft Anmeldung, Datenbankantwort, Anrufregistrierung, Transaktionsabschluss oder API-Verhalten.
Alarme informieren Administratoren, wenn die Uptime gefährdet ist oder ein Ausfall eintritt. Alarme allein reichen aber nicht aus. Das Unternehmen braucht einen Störungsreaktionsprozess, der festlegt, wer Untersuchungen durchführt, wie Probleme eskaliert werden, wie Nutzer informiert werden und wie der Dienst wiederhergestellt wird.
Überwachung wird wertvoll, wenn sie Erkennung mit Handlung verbindet. Schnelles Wissen über einen Ausfall hilft nur, wenn das Team effektiv reagieren kann.
Uptime und SLA
Service-Level-Agreements (SLAs)
Ein Service-Level-Agreement (SLA) legt den Uptime-Prozentsatz fest, zu dem sich ein Dienstleister oder internes Team verpflichtet. Beispielsweise kann ein Anbieter 99,9 % Uptime für einen monatlichen Abrechnungszeitraum zusichern. Das SLA definiert zudem, was als Ausfall zählt, welche Wartungsfenster ausgeschlossen sind und welche Entschädigungen gelten, wenn das Ziel verfehlt wird.
Die Formulierung des SLA ist entscheidend, da die Uptime unterschiedlich interpretiert werden kann. Einige Vereinbarungen schließen geplante Wartung aus, andere zählen nur vollständige Dienstausfälle (keine teilweisen Leistungseinbußen) und messen die Verfügbarkeit aus dem Netz des Anbieters statt aus der Kundenposition.
Daher sollten Nutzer die SLA-Definitionen sorgfältig prüfen. Der angegebene Uptime-Prozentsatz ist wichtig – aber die Messregeln sind ebenso entscheidend.
Geplante Wartung vs. ungeplante Ausfallzeit
Geplante Wartung umfasst terminierte Arbeiten, die die Systemverfügbarkeit vorübergehend beeinträchtigen können: Firmware-Upgrades, Software-Updates, Hardware-Austausch, Datenbankwartung, Sicherheitspatches oder Infrastrukturänderungen. Viele Uptime-Berechnungen behandeln geplante Wartung anders als unerwartete Ausfälle.
Ungeplante Ausfallzeiten entstehen durch unerwartete Systemausfälle: Hardware-Fehler, Softwareabstürze, Netzwerkausfälle, Konfigurationsfehler, Cyberangriffe, Stromausfälle oder menschliche Fehler. Diese Art von Ausfall ist besonders schädlich, da Nutzer nicht darauf vorbereitet sind.
Ein gutes Uptime-Management reduziert ungeplante Ausfälle und kommuniziert geplante Wartung klar, damit Nutzer sich vorbereiten können.
Wartungstipps für bessere Uptime
Vorbeugende Wartung nutzen
Vorbeugende Wartung verbessert die Uptime, indem Probleme behoben werden, bevor sie zu Ausfällen führen. Dazu gehören Protokollprüfungen, Firmware-Updates, Sicherheitspatches, Austausch gealterter Hardware, Speicherkapazitätsüberwachung, Backup-Tests und Analyse von Systemleistungsentwicklungen.
Vorbeugende Wartung sollte geplant und dokumentiert werden. Zufällige Änderungen können neue Probleme verursachen, während kontrollierte Wartung Risiken mindert. Ziel ist es, Systeme gesund zu halten, ohne unnötige Unterbrechungen zu verursachen.
Viele Ausfälle sind vermeidbar, wenn Wartungsteams handeln, bevor Warnsignale zu Fehlern werden.
Änderungen sorgfältig kontrollieren
Konfigurationsänderungen sind eine häufige Ursache für Ausfälle. Eine Firewall-Regel, Routing-Änderung, Software-Aktualisierung, Zertifikatswechsel, Datenbankanpassung oder Zugriffsrichtlinienänderung kann den Dienst unbeabsichtigt unterbrechen, wenn sie nicht geprüft wird. Das Änderungsmanagement mindert dieses Risiko.
Gutes Änderungsmanagement umfasst Dokumentation, Genehmigung, Tests, Rücksetzplanung, Zeitwahl und Prüfung nach der Änderung. Bei kritischen Systemen sollten Änderungen in Zeiten geringer Belastung erfolgen und eng überwacht werden.
Die Uptime hängt oft ebenso von diszipliniertem Betrieb ab wie von starker Hardware.
Viele Uptime-Probleme beginnen nicht mit defekter Hardware. Sie entstehen durch unkontrollierte Änderungen, schlechte Wartungsgewohnheiten oder fehlende Überprüfungen.
Anwendungsbereiche der Uptime-Messung
Websites, Cloud-Dienste und Anwendungen
Websites, Cloud-Dienste und Anwendungen nutzen die Uptime-Messung, um zu prüfen, ob Nutzer auf digitale Dienste zugreifen können, wenn sie es brauchen. E-Commerce-Websites, SaaS-Plattformen, Online-Banking, Kundenportale, Streaming-Dienste und Geschäftsanwendungen sind auf hohe Verfügbarkeit angewiesen.
In diesen Umgebungen verursachen Ausfälle Umsatzverluste, Kundenunzufriedenheit, Rufschädigung und unterbrochene interne Arbeitsabläufe. Die Uptime-Überwachung hilft Unternehmen, Probleme schnell zu erkennen und zu prüfen, ob die Dienstleistung den Nutzererwartungen entspricht.
Bei kundenorientierten Diensten ist die Uptime eines der sichtbarsten Zeichen für Zuverlässigkeit.
Netze, Kommunikationssysteme und Infrastruktur
Die Uptime ist auch in Netzen und Kommunikationssystemen kritisch. Router, Switches, Firewalls, IP-Telefonanlagen, SIP-Server, Gateways, Leitstellen, Sprechanlagen, Sicherheitssysteme und Überwachungsplattformen brauchen zuverlässigen Betrieb. Bei Ausfällen sind Sprachkommunikation, Datenzugriff, Alarme, Zugangskontrolle und operative Koordination beeinträchtigt.
Die Infrastruktur-Uptime ist besonders wichtig, da viele andere Dienste davon abhängen. Eine Cloud-Anwendung kann einwandfrei laufen, aber bei einem lokalen Netzwerkausfall können Nutzer nicht darauf zugreifen. Eine Kommunikationsplattform kann laufen, aber bei einem Gateway- oder Leitungsausfall schlagen Verbindungen fehl.
Daher wird die Infrastruktur-Uptime üblicherweise auf mehreren Ebenen überwacht – von physischen Geräten bis zu nutzerorientierten Diensten.
Häufige Ursachen für Ausfallzeiten
Technische Fehler
Technische Fehler umfassen Hardware-Funktionsstörungen, Softwareabstürze, Speicherlecks, Datenbankprobleme, Festplattenausfälle, Netzwerkgeräteausfälle, Stromunterbrechungen, Kühlungsprobleme und Ressourcenerschöpfung. Dies sind häufige Ausfallursachen in vielen Umgebungen.
Einige technische Fehler treten plötzlich auf, andere entwickeln sich langsam. Eine Festplatte gibt Warnungen vor dem Ausfall, ein Server verlangsamt sich vor dem Absturz, eine Netzwerkverbindung zeigt Paketverluste vor dem totalen Ausfall. Die Überwachung erkennt diese frühen Zeichen, damit Teams schneller handeln können.
Redundanz, Alarme, Kapazitätsplanung und vorbeugende Wartung mindern die Auswirkungen technischer Fehler.
Menschliche Fehler und Prozessschwächen
Menschliche Fehler sind eine weitere Hauptursache für Ausfälle. Falsche Befehle, versehentliches Löschen, falsch konfigurierte Firewall-Regeln, falsche Firmware-Dateien, abgelaufene Zertifikate oder schlecht getestete Updates können einen Dienst zum Stillstand bringen. Oft scheitert das System nicht an schwacher Hardware, sondern an mangelhaften Betriebsprozessen.
Prozesskontrollen mindern dieses Risiko: Dokumentation, Zugangskontrolle, Peer-Review, Änderungsgenehmigung, Backups, Testumgebungen und Rücksetzpläne machen menschliche Fehler weniger schädlich. Schulungen sind wichtig, da Administratoren sowohl das System als auch die Auswirkungen von Änderungen verstehen müssen.
Ein starkes Uptime-Management betrachtet Menschen, Prozesse und Technologie als ein einziges Zuverlässigkeitssystem.
Wie man die Uptime verbessert
Für Fehler konstruieren
Die Verbesserung der Uptime beginnt damit, Systeme für Fehlerfälle zu konstruieren. Jede Komponente kann irgendwann ausfallen. Ein zuverlässiges System geht von Fehlern aus und integriert Ersatzpfade, Überwachung, Wiederherstellungsverfahren und getestetes Failover-Verhalten.
Dieser Ansatz ändert die Konstruktionsdenkweise. Statt zu fragen, ob eine Komponente ausfällt, fragt das Team, was passiert, wenn sie ausfällt. Wenn die Antwort lautet, dass der gesamte Dienst stoppt, braucht das Konstrukt Verbesserungen. Wenn der Verkehr auf einen Ersatzpfad wechselt und Nutzer weiterarbeiten können, ist das System widerstandsfähiger.
Die Konstruktion für Fehler ist eines der Kernprinzipien für hohe Uptime.
Messen, was Nutzer tatsächlich erleben
Die Uptime-Verbesserung sollte sich auf die Nutzererfahrung konzentrieren – nicht nur auf interne Statuswerte. Ein Server-Dashboard kann anzeigen, dass ein Prozess läuft, aber Nutzer können sich trotzdem nicht anmelden, anrufen, Dateien öffnen oder Transaktionen durchführen. Daher sollte die Überwachung nach Möglichkeit Ende-zu-Ende-Prüfungen umfassen.
Nutzerorientierte Messungen enthüllen Probleme, die Komponentenprüfungen übersehen. Sie helfen Unternehmen zudem, die tatsächlichen Geschäftsauswirkungen von Ausfällen zu verstehen. Wenn Nutzer ihre Aufgabe nicht erledigen können, ist das System aus ihrer Sicht nicht wirklich verfügbar.
Die besten Uptime-Programme messen sowohl die technische Gesundheit als auch das nutzerorientierte Dienstverhalten.
Fazit
Die Uptime misst, wie lange ein System, Gerät, Dienst oder Plattform betriebsbereit und verfügbar ist. Sie ist ein Schlüsselindikator für Zuverlässigkeit bei Websites, Cloud-Plattformen, Netzen, Kommunikationssystemen, Rechenzentren, industrieller Infrastruktur und Geschäftsanwendungen. Hohe Uptime bedeutet, dass Nutzer sich auf den Dienst verlassen können, wenn sie ihn brauchen.
Die Uptime funktioniert, indem die verfügbare Dienstzeit erfasst und mit der gesamten Messzeit verglichen wird. Sie wird beeinflusst von Hardware-Zuverlässigkeit, Netzwerkkonnektivität, Stromstabilität, Softwarequalität, Systemarchitektur, Überwachung, Wartung und Betriebsdisziplin. Starke Uptime erfordert üblicherweise Redundanz, Failover, vorbeugende Wartung, kontrollierte Änderungen und realistische Dienstüberwachung.
Praktisch gesehen ist die Uptime mehr als nur ein Prozentsatz. Sie spiegelt wider, wie gut ein System konstruiert, betrieben, überwacht und gewartet wird, um echte Nutzer und geschäftliche Anforderungen zu unterstützen.
FAQ
Was bedeutet Uptime einfach erklärt?
Einfach ausgedrückt ist Uptime die Zeit, in der ein System oder Dienst funktioniert und nutzbar ist. Wenn eine Website, ein Server, ein Netzwerk oder Gerät ordnungsgemäß läuft, zählt diese Zeit zur Uptime.
Sie wird üblicherweise zur Messung der Zuverlässigkeit verwendet.
Wie wird die Uptime berechnet?
Die Uptime wird normalerweise berechnet, indem die verfügbare Zeit des Systems mit der gesamten Messzeit verglichen wird. Das Ergebnis wird oft als Prozentsatz angezeigt, beispielsweise 99,9 % Uptime.
Die genaue Berechnung hängt davon ab, wie Verfügbarkeit und Ausfallzeit definiert sind.
Warum ist Uptime wichtig?
Die Uptime ist wichtig, weil Nutzer und Unternehmen auf verfügbare Systeme angewiesen sind. Schlechte Uptime verursacht Produktivitätsverluste, fehlgeschlagene Kommunikation, Kundenunzufriedenheit, Dienstunterbrechungen und Umsatzverluste.
Hohe Uptime unterstützt Zuverlässigkeit, Kontinuität und Nutzervertrauen.