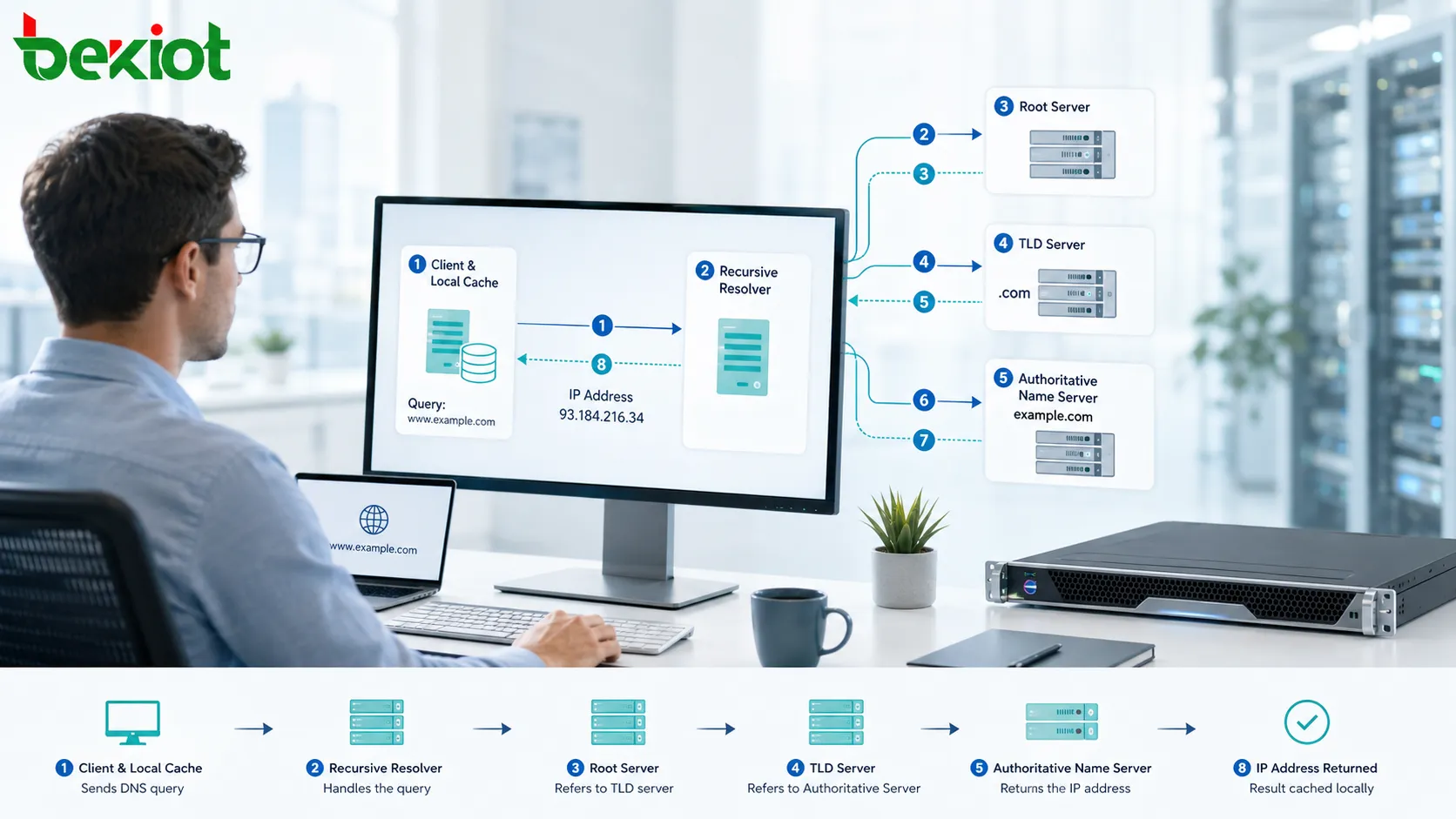
Ein Unternehmen mit nur einem Büro kann Netzwerkprobleme oft durch einen zusätzlichen Switch, ein Router-Upgrade oder eine angepasste Firewall-Regel lösen. Ein Unternehmen mit vielen Standorten steht vor einer anderen Aufgabe: Jede Filiale, Anlage, jedes Lager, jeder Campus, jedes Rechenzentrum, jede Cloud-Region und jeder Remote-Zugangspunkt wird Teil eines gemeinsamen Betriebssystems. Werden diese Standorte ohne Planung verbunden, entstehen fragmentierter Zugriff, doppelte Ressourcen, uneinheitliche Sicherheit, langsame Fehlersuche und instabile Zusammenarbeit.
Branchenblick:der Wert eines verteilten Netzwerks beschränkt sich nicht mehr auf einfache Konnektivität. Moderne Organisationen nutzen es für Cloud-Zugriff, Unified Communications, Fernüberwachung, Videoüberwachung, IoT-Plattformen, zentrale Verwaltung, Notfallwiederherstellung, Zero-Trust-Zugriff und Echtzeitanwendungen. Entscheidend ist nicht nur, verschiedene Orte zu verbinden, sondern diese Verbindungen in eine steuerbare und intelligente Servicegrundlage zu verwandeln.
Die vollständige Nutzung dieser Architektur bedeutet, sie als strategische digitale Plattform zu behandeln. Jeder Standort darf nicht als isolierte Insel arbeiten. Er sollte die richtigen Ressourcen teilen, passende Sicherheitsregeln befolgen, die richtigen Daten austauschen und widerstandsfähig bleiben, wenn Links, Geräte oder Dienste ausfallen.
Von Filialkonnektivität zu operativer Integration
Der ursprüngliche Zweck der Verbindung mehrerer Standorte war meist einfach: Benutzer in Filialen sollten auf Systeme der Zentrale zugreifen können. Dieses Modell nutzte häufig Mietleitungen, VPN-Tunnel, private WAN-Links oder Punkt-zu-Punkt-Verbindungen. Es löste Zugriffsprobleme, schuf aber nicht immer flexible digitale Abläufe.
Heute ist die Betriebsumgebung komplexer. Anwendungen laufen in Public Cloud, Private Cloud, Edge-Servern, lokalen Rechenzentren oder SaaS-Plattformen. Benutzer arbeiten aus Büros, Fahrzeugen, Homeoffice, Außeneinsatzorten und von mobilen Geräten. Bedrohungen können aus dem Internet, kompromittierten Endgeräten, falsch konfigurierten Cloud-Diensten oder interner lateraler Bewegung kommen.
Deshalb muss eine verteilte Architektur mehr leisten als Verkehrstransport. Sie muss Anwendungsleistung, identitätsbasierten Zugriff, zentrale Richtlinien, Segmentierung, Überwachung, Automatisierung und Resilienz über alle verbundenen Standorte unterstützen.

Die Rolle jedes Standorts definieren
Nicht jeder Standort hat dieselbe Funktion. Die Zentrale kann Kernsysteme, Führungsteams, Datenräume und zentrale Sicherheitsgeräte beherbergen. Eine Fabrik priorisiert vielleicht Operational Technology, Produktionsüberwachung, industrielle Terminals und lokale Steuerungen. Ein Lager konzentriert sich auf Barcodesysteme, Logistikplattformen, Kameras, WLAN-Abdeckung und Handhelds. Ein kleines Büro benötigt möglicherweise nur sicheren Zugriff auf Cloud-Anwendungen und gemeinsame Sprachdienste.
Vor der Optimierung sollte jeder Standort nach Geschäftsrolle, Anwendungsabhängigkeiten, Benutzerzahl, Verkehrstyp, Verfügbarkeitsanforderung und Sicherheitssensitivität klassifiziert werden. Diese Einordnung hilft bei Bandbreite, Routing, Redundanz, Segmentierung, Geräteauswahl, Überwachungstiefe und Supportmodell.
Ohne diesen Schritt werden kleine Standorte leicht überbaut und kritische Standorte zu schwach geschützt. Ein gutes Design passt das Netzwerkniveau an die geschäftliche Bedeutung des jeweiligen Standorts an.
Ein klares Konnektivitätsmodell aufbauen
Eine verteilte Umgebung kann MPLS, Breitbandinternet, 4G/5G, private Glasfaser, Richtfunk, Satellit, VPN, SD-WAN oder hybride Konnektivität nutzen. Jede Option unterscheidet sich in Leistung, Kosten, Zuverlässigkeit und Verwaltung.
Traditionelle private WAN-Links liefern kontrollierbare Leistung, sind aber teuer und langsam bereitzustellen. Internet-VPN ist flexibel und kostengünstig, die Leistung kann jedoch schwanken. SD-WAN kombiniert mehrere Links, steuert Verkehr nach Anwendungsrichtlinien und bietet zentrale Orchestrierung. Mobilfunklinks eignen sich für schnelle Bereitstellung oder Backup. Satellit versorgt entfernte Standorte ohne terrestrische Anbindung.
Das beste Modell ist oft hybrid. Kritische Standorte nutzen doppelte Links. Kleine Filialen verwenden Breitband plus Mobilfunk-Backup. Entfernte Industriestandorte nutzen private Glasfaser oder drahtlosen Backhaul. Cloud-Verkehr kann direkt zu Cloud-Plattformen gehen, statt über die Zentrale zurückgeführt zu werden.
Zentrale Verwaltung nutzen, ohne lokale Resilienz zu verlieren
Zentrale Verwaltung erlaubt es Administratoren, viele Standorte von einer Plattform aus zu konfigurieren, zu überwachen, zu aktualisieren und zu sichern. Das reduziert manuelle Fehler, verbessert Standardisierung und macht den Großbetrieb effizienter.
Zentralisierung darf jedoch keinen Single Point of Failure erzeugen. Eine Filiale sollte nicht vollständig ausfallen, nur weil sie den Kontakt zum zentralen Controller vorübergehend verliert. Je nach Standortbedeutung können lokaler Internetausgang, zwischengespeicherte Richtlinien, Backup-Routing, lokales DHCP, lokale DNS-Weiterleitung und Notfallkommunikationswege nötig sein.
Das Ziel ist ausgewogene Kontrolle. Die Organisation verwaltet einheitlich aus der Mitte, während Standorte bei Link- oder Controller-Ausfällen wesentliche Aufgaben fortsetzen können.
Verkehr nach Funktion und Risiko segmentieren
Segmentierung ist in einer verteilten Architektur wesentlich. Benutzerverkehr, Sprache, Videoüberwachung, Gäste-WLAN, industrielle Steuerung, Zahlungssysteme, Serververkehr, Managementschnittstellen und IoT-Geräte sollten nicht denselben Sicherheitsbereich teilen.
VLANs, VRFs, Firewall-Zonen, Zugriffskontrolllisten, Mikrosegmentierung, Zero-Trust-Richtlinien und softwaredefinierte Sicherheitsgruppen helfen bei der Trennung. Ziel ist es, Risiken zu senken, Zugriff zu steuern und zu verhindern, dass ein kompromittierter Bereich die gesamte Organisation beeinflusst.
Segmentierung sollte der Geschäftslogik folgen. Ein Gäste-WLAN-Nutzer darf keine internen Server erreichen. Ein Kameranetz kann Video an Speicher senden, sollte aber keine Bürogeräte erreichen. Industrieterminals benötigen häufig strikte Kommunikationswege zu Steuerungen und Monitoring-Servern.
Anwendungspfade optimieren
Anwendungsleistung ist ein Hauptgrund für die Modernisierung standortübergreifender Konnektivität. Benutzer bewerten das Netzwerk nicht nach Linkdiagrammen, sondern danach, ob Anrufe klar sind, Dashboards schnell laden, Dateien synchronisieren, Videostreams stabil bleiben und Geschäftssysteme ohne Verzögerung reagieren.
Anwendungsbewusstes Routing wählt Pfade nach Latenz, Paketverlust, Jitter, Bandbreite und Servicepriorität. Sprache und Video brauchen niedrige Latenz und geringen Jitter. Große Dateiübertragungen tolerieren Verzögerung, benötigen aber Bandbreite. Cloud-Anwendungen profitieren häufig von direktem Internetausgang. Sensible Daten benötigen möglicherweise Inspektion über Sicherheitsgateways.
Traffic Engineering muss auf realem Anwendungsverhalten basieren. Ein pauschales Modell „alles über die Zentrale“ wird ineffizient, wenn die meisten Anwendungen in der Cloud gehostet sind.
Cloud- und SaaS-Zugriff stärken
Cloud-Zugriff hat das Netzwerkdesign verändert. Viele Organisationen nutzen SaaS-Plattformen, Public-Cloud-Workloads, Identitätsdienste, Cloud-Speicher, Remote-Desktops und API-getriebene Geschäftssysteme. Wird der gesamte Cloud-Verkehr durch ein zentrales Rechenzentrum gezwungen, entstehen unnötige Verzögerungen.
Direkter Cloud-Zugriff kann die Leistung verbessern, muss aber gesichert werden. Dazu gehören sichere Web-Gateways, CASB-Funktionen, identitätsbasierte Richtlinien, DNS-Sicherheit, Endpoint-Posture-Prüfungen und gegebenenfalls die Inspektion verschlüsselten Verkehrs.
Auch Cloud-Konnektivität muss auf Zuverlässigkeit geplant werden. Kritische Workloads benötigen eventuell redundante Cloud-Regionen, dedizierte Cloud-Interconnects, Backup-Internetlinks oder Failover-Routing.
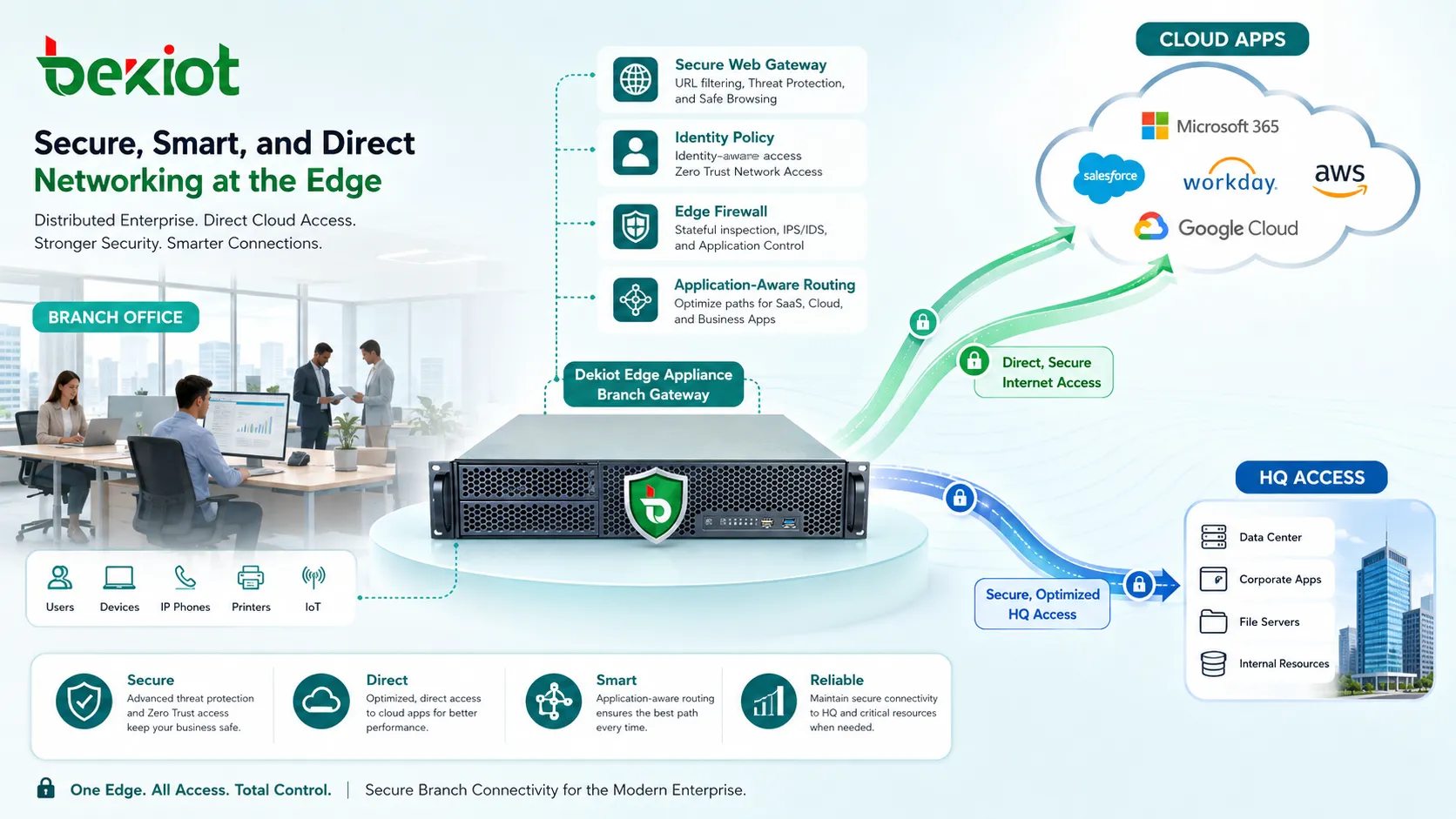
Unified Communications über Standorte unterstützen
Sprache, Video, Messaging, Konferenzen, Intercom, Paging und Dispatch-Systeme hängen oft von derselben Netzwerkbasis ab. Schlechtes Routing, Jitter, Paketverlust oder Firewall-Fehlkonfiguration beeinträchtigen die Kommunikationsqualität schnell.
Ein gut gestaltetes verteiltes Netzwerk klassifiziert Echtzeit-Medienverkehr, priorisiert verzögerungssensitive Streams, gewährleistet bei Bedarf NAT-Traversal und überwacht Sprachqualitätsindikatoren. Für kritische Kommunikation sollte es lokale Überlebensfähigkeit bieten, wenn zentrale Dienste nicht erreichbar sind.
Bei Organisationen mit vielen Standorten sollte Unified Communication mit Verzeichnisdiensten, Nummerierungsplänen, Notfallrouting, Aufzeichnungsrichtlinien und Sicherheitsregeln integriert sein. So entstehen keine Kommunikationsinseln und die Koordination im Alltag und bei Vorfällen wird verbessert.
Video und IoT in großem Maßstab ermöglichen
Videoüberwachung, Sensoren, Zugangskontrolle, Umweltüberwachung, Smart Meter, Industrieterminals und IoT-Geräte erzeugen große Datenmengen. Sie besitzen außerdem andere Sicherheitsmerkmale als gewöhnliche Benutzergeräte.
Um diese Systeme wirksam zu nutzen, muss das Netzwerk definieren, wo Daten verarbeitet werden. Manche Videoanalyse findet am Edge statt. Manche Aufzeichnungen werden lokal gespeichert und zentral synchronisiert. Einige Sensordaten gehen an Cloud-Plattformen. Nicht jeder Datenstrom muss ständig über das WAN laufen.
Edge-Verarbeitung reduziert Bandbreitendruck und verbessert Reaktionszeiten. Zentrale Plattformen liefern Sichtbarkeit und Verwaltung. Der beste Ansatz hängt von Standort, Anwendung, Datenwert und Aufbewahrungsanforderungen ab.
Richtlinienbasierte Sicherheit verwenden
Traditionelle Sicherheit konzentrierte sich oft auf Standortgrenzen. Moderne verteilte Umgebungen brauchen feinere Kontrolle. Ein Benutzer greift aus einer Filiale, dem Homeoffice, von einem Mobilgerät oder aus einem Cloud-Workspace zu. Ein Gerät bewegt sich zwischen Netzen. Ein Dienst läuft in mehreren Regionen.
Richtlinien sollten auf Identität, Gerätezustand, Standort, Anwendung, Datensensitivität und Risikoniveau basieren. Hier sind Zero-Trust-Prinzipien hilfreich. Zugriff wird nach verifiziertem Kontext gewährt, nicht nur weil ein Standort im WAN liegt.
Richtlinienbasierte Sicherheit verbessert auch Konsistenz. Statt jede Firewall und jeden Router unterschiedlich zu konfigurieren, definieren Organisationen Standardzugriffsmodelle und rollen sie über Standorte aus.
Für Ausfälle entwerfen, nicht nur für Normalbetrieb
Ein verteiltes System wird Ausfälle erleben. Internetlinks fallen aus, Strom versagt, Geräte stürzen ab, Cloud-Dienste werden unerreichbar, Glasfaser wird getrennt und Konfigurationsänderungen verursachen unerwartetes Routing. Der echte Test ist, ob geschäftskritische Funktionen weiterlaufen oder schnell wiederhergestellt werden.
Resilienzplanung umfasst redundante Links, Ersatzstrom, doppelte Geräte, automatisches Failover, lokale Überlebensfähigkeit, Out-of-Band-Management, Konfigurationssicherung und Disaster-Recovery-Verfahren. Kritische Standorte brauchen mehr Schutz als Standorte mit geringem Risiko.
Failover muss getestet werden. Ein nie getesteter Backup-Link kann im entscheidenden Moment versagen. Tests sollten Routing, Sicherheitsrichtlinien, Sprachdienste, Anwendungszugriff und Monitoring-Alarme umfassen.
Sichtbarkeit mit Monitoring und Telemetrie verbessern
Große verteilte Umgebungen lassen sich nicht manuell beobachten. Administratoren brauchen Echtzeit- und Verlaufsdaten zu Linkstatus, Bandbreitennutzung, Latenz, Paketverlust, Gerätezustand, Anwendungsleistung, Sicherheitsereignissen, Benutzererfahrung und Konfigurationsänderungen.
Monitoring sollte geschichtet sein. Gerätemonitoring zeigt, ob Geräte online sind. Linkmonitoring zeigt Transportqualität. Anwendungsmonitoring zeigt, ob Benutzer Aufgaben erledigen können. Sicherheitsmonitoring zeigt verdächtiges Verhalten. Log-Analyse zeigt, was sich vor einem Vorfall geändert hat.
Gute Sichtbarkeit verkürzt die Fehlersuche. Statt zu fragen, ob es „das Netzwerk“ ist, sehen Ingenieure, ob DNS, WAN-Überlastung, Firewall-Blockade, Cloud-Ausfall, WLAN-Problem oder Endpoint-Fehler vorliegt.

Wiederholte Abläufe automatisieren
Automatisierung reduziert wiederholte manuelle Arbeit. Häufige Aufgaben sind Geräte-Onboarding, Konfigurationsvorlagen, Richtlinienbereitstellung, Firmware-Updates, Zertifikatserneuerung, Konfigurationsbackup, Alarmreaktion und Compliance-Prüfung.
Vorlagenbasierte Konfiguration ist besonders wertvoll für neue Filialen. Statt Routing, VLANs, VPNs, Firewall-Regeln und Monitoring jedes Mal neu aufzubauen, wenden Administratoren ein Standardprofil an und passen nur standortspezifische Parameter an.
Automatisierung muss über Genehmigung, Versionsverfolgung, Tests und Rollback kontrolliert werden. Schnelle Bereitstellung ist nur nützlich, wenn Änderungen zuverlässig sind.
Adressierung und Benennung standardisieren
Adressplanung wird schwierig, wenn viele Standorte unabhängig wachsen. Überlappende IP-Bereiche, unklare VLAN-Namen, inkonsistente DNS-Einträge und undokumentierte Subnetze führen zu Routingkonflikten und verzögerter Fehlersuche.
Ein zentraler Adressplan sollte Standortcodes, IP-Blöcke, VLAN-Bereiche, Loopback-Adressen, Managementnetze, DHCP-Bereiche und reservierte Bereiche definieren. Benennungsregeln sollten Standort, Gerätetyp, Funktion und Rolle klar erkennen lassen.
Gute Benennung und Adressierung reduzieren Verwirrung. Sie erleichtern auch Automatisierung, Monitoring, Firewall-Richtlinien und Dokumentationspflege.
WLAN und Edge-Zugriff konsistent planen
Viele Standorte hängen stark von Wi-Fi, Handhelds, mobilen Geräten, Barcode-Scannern, Tablets, Kameras, Sensoren und Gästezugang ab. Das WLAN-Design muss einheitlich genug für Roaming, Sicherheit und Verwaltung sein, zugleich aber flexibel für lokale Gebäudestrukturen.
Zentrale WLAN-Controller oder cloudverwaltete Access Points vereinfachen die Richtlinienbereitstellung. Funkplanung erfordert jedoch weiterhin Standortbegehungen, Kanaldesign, Interferenzanalyse und Kapazitätsplanung.
Edge-Zugriff muss auch physische Sicherheit berücksichtigen. Netzwerkports in öffentlichen Bereichen, Lagern und Industrieanlagen dürfen keinen uneingeschränkten internen Zugriff bieten.
Operational Technology vorsichtig verbinden
Industrie- und Gebäudesysteme enthalten häufig Operational Technology wie PLCs, SCADA-Terminals, Sensoren, Zutrittskontrolle, Energiesysteme und Produktionsanlagen. Diese Systeme benötigen möglicherweise niedrige Latenz, stabilen Betrieb, strikte Segmentierung und kontrollierte Wartungsfenster.
Die Verbindung operativer Netze mit Unternehmenssystemen verbessert Monitoring und Datenanalyse, bringt aber Cyberrisiken. Zugriff sollte durch Firewalls, Gateways, Jump Hosts, Identitätsprüfungen und Protokollierung kontrolliert werden.
IT- und OT-Teams sollten Verantwortlichkeiten, Wartungsverfahren, Notfallzugriff und Change Control abstimmen. Eine im Büronetz harmlose Änderung kann Produktionssysteme beeinträchtigen, wenn sie unachtsam angewendet wird.
Lokalen Breakout strategisch nutzen
Lokaler Internet-Breakout ermöglicht einer Filiale den direkten Zugriff auf Cloud- und Internetdienste, statt den gesamten Verkehr zur Zentrale zu senden. Das senkt Latenz und verbessert die Anwendungserfahrung.
Das Risiko ist, dass Filialverkehr zentrale Sicherheitskontrollen umgeht. Deshalb sollte lokaler Breakout mit sicheren Web-Gateways, DNS-Filterung, Endpoint-Schutz, Cloud-Sicherheitsdiensten und richtlinienbasierter Inspektion kombiniert werden.
Nicht jeder Verkehr sollte lokal ausbrechen. Sensible interne Anwendungen nutzen weiterhin private Pfade, während SaaS und risikoarmer Webverkehr kontrolliert lokal austreten können.
Netzwerkdesign an Geschäftskontinuität ausrichten
Geschäftskontinuität muss definieren, welche Dienste verschiedene Ausfallszenarien überstehen müssen. Eine Filiale im Einzelhandel benötigt Zahlungsabwicklung. Ein Krankenhaus braucht klinischen Zugriff und Notfallkommunikation. Eine Fabrik braucht Produktionsüberwachung. Ein Lager braucht Scan- und Logistiksysteme.
Sobald kritische Funktionen identifiziert sind, kann das Netzwerk die passende Redundanz und lokale Überlebensfähigkeit bereitstellen. Dazu gehören lokale Server, zwischengespeicherte Authentifizierung, Backup-WAN, Mobilfunk-Failover, lokales Sprachrouting oder Notfallverfahren.
Business Continuity sollte mit realen Szenarien getestet werden. Ein schriftlicher Plan reicht nicht, wenn Benutzer bei einem Netzwerkausfall nicht wissen, wie sie handeln sollen.
Governance und Change Control
Multisite-Umgebungen benötigen disziplinierte Governance. Eine schnelle Firewall-Änderung an einem Standort kann Zugriff von einem anderen Standort beeinflussen. Eine neue Cloud-Verbindung kann Routing ändern. Ein temporäres VPN kann ohne Prüfung dauerhaft werden.
Change Control sollte Antragsgrund, betroffene Standorte, Risikostufe, Rollback-Plan, Testmethode, Wartungsfenster, Genehmigung und Dokumentationsaktualisierung umfassen. Notfalländerungen sollten nach dem Vorfall überprüft werden.
Governance bedeutet nicht, alles zu verlangsamen. Sie macht Änderungen sicher, nachvollziehbar und wiederholbar.
Kostenoptimierung
Eine verteilte Architektur vollständig zu nutzen bedeutet auch, Kosten zu steuern. Manche Organisationen zahlen zu viel für Bandbreite an Standorten mit geringem Verkehr und investieren zu wenig in kritische Links. Andere halten alte private Leitungen, obwohl sich Cloud-Zugriffsmuster geändert haben.
Die Kostenanalyse sollte Geschäftswert, Leistungsbedarf, Risikoniveau und Redundanzanforderung vergleichen. Ein teurer Link kann für einen kritischen Standort gerechtfertigt sein, für ein kleines Büro mit reinen Cloud-Anwendungen aber unnötig.
Monitoringdaten helfen bei Entscheidungen. Reale Bandbreitennutzung, Paketverlust, Anwendungsantwortzeit und Failover-Ereignisse liefern bessere Belege als Annahmen.
Implementierungsfahrplan
Beginnen Sie mit Discovery. Erfassen Sie Standorte, Links, Geräte, Anwendungen, Benutzer, Sicherheitszonen, Cloud-Dienste und operative Abhängigkeiten. Identifizieren Sie doppelte Systeme, schwache Links, nicht verwaltete Geräte und undokumentierte Verkehrsflüsse.
Definieren Sie dann die Zielarchitektur. Entscheiden Sie, welche Standorte Redundanz benötigen, welcher Verkehr private Pfade nutzt, welche Dienste lokalen Breakout verwenden, wie Segmentierung funktioniert und wie Richtlinien verwaltet werden.
Setzen Sie anschließend schrittweise um. Standardisieren Sie zuerst Benennung und Adressierung, verbessern Sie Monitoring, führen Sie Sicherheitssegmentierung ein, optimieren Sie Cloud-Zugriff, ergänzen Sie Automatisierung und testen Sie Resilienz. Vermeiden Sie Änderungen an allen Standorten gleichzeitig, sofern keine starke Rollback-Fähigkeit vorhanden ist.
Häufige Fehler
Ein Fehler ist, alle Standorte gleich zu behandeln. Standorte haben unterschiedliche Risiken, Verkehrsprofile und Geschäftsbedeutung. Die Architektur sollte diese Unterschiede abbilden.
Ein weiterer Fehler ist der Fokus nur auf Bandbreite. Mehr Bandbreite löst keine Routingfehler, Sicherheitslücken, schlechtes Wi-Fi, DNS-Probleme, Anwendungslatenz oder fehlende Sichtbarkeit.
Ein dritter Fehler ist das unkontrollierte Wachstum lokaler Ausnahmen. Temporäre Routen, nicht verwaltete Switches, Schatten-Internetleitungen und nicht nachverfolgte VPNs erzeugen langfristige Risiken.
Ein vierter Fehler ist, die Benutzererfahrung zu ignorieren. Das Netzwerk kann laut Gerätestatus gesund wirken, während Benutzer langsame Anwendungen oder schlechte Sprachqualität erleben.
Ein fünfter Fehler ist verzögerte Dokumentation. In einer verteilten Umgebung wird undokumentiertes Design zum Risiko künftiger Ausfälle.
Branchentrends
Verteilte Netzwerke bewegen sich zu cloudverwalteter Steuerung, SD-WAN, SASE, Zero-Trust-Zugriff, Edge Computing, KI-gestütztem Monitoring und stärkerer Integration von Netzwerk und Sicherheit. Die Grenze zwischen WAN, Cloud-Zugriff, Identität und Bedrohungsschutz wird unschärfer.
Gleichzeitig fügen Organisationen mehr verbundene Geräte und Echtzeitdienste hinzu. Video, Sprache, Sensoren, industrielle Telemetrie und Remote-Betrieb erhöhen den Druck auf das Netzwerkdesign.
Die erfolgreichste Richtung ist nicht einfach mehr Werkzeuge hinzuzufügen. Sie besteht darin, ein kohärentes Betriebsmodell aufzubauen, in dem Konnektivität, Sicherheit, Monitoring, Automatisierung und Geschäftsprozesse einander unterstützen.
Ein standortübergreifendes Netzwerk ist vollständig genutzt, wenn es zu einer verwalteten digitalen Grundlage wird, die Standorte verbindet, Zugriff schützt, Anwendungen optimiert, Resilienz unterstützt und Administratoren klare Sicht auf die gesamte Organisation gibt.
Häufige Fragen
Warum erleben unterschiedliche Filialen unterschiedliche Netzwerkqualität?
Jede Filiale kann andere Zugangslinks, Wi-Fi-Umgebungen, Routingpfade, Gerätemodelle, Cloud-Distanzen und lokale Verkehrslasten haben. Monitoring sollte standortbezogene Bedingungen vergleichen, statt eine gemeinsame Ursache anzunehmen.
Sollte der gesamte Verkehr zur Zentrale zurückkehren?
Nicht immer. Cloud- und SaaS-Verkehr kann über kontrollierten lokalen Breakout besser funktionieren, während sensibler interner Verkehr private Routen oder zentrale Inspektion benötigen kann.
Wie können kleine Standorte ohne komplexe Geräte geschützt werden?
Nutzen Sie standardisierte Vorlagen, verwaltete Firewalls, sichere Cloud-Gateways, Endpoint-Schutz, DNS-Filterung, starke Authentifizierung und zentrales Monitoring. Die Komplexität sollte zum Standort-Risiko passen.
Warum ist Segmentierung über Standorte wichtig?
Segmentierung begrenzt unnötigen Zugriff zwischen Benutzern, Geräten, Servern, IoT-Systemen und operativen Netzen. Sie reduziert die Auswirkungen einer Kompromittierung und verbessert Richtlinienkontrolle.
Was sollte vor dem Hinzufügen einer neuen Filiale geprüft werden?
Prüfen Sie Bandbreitenbedarf, Anwendungszugriff, IP-Adressierung, Sicherheitszonen, Wi-Fi-Design, Redundanzanforderung, Cloud-Zugriff, Monitoring-Integration, Benennungsregeln und Supportverantwortung.