Ein SLA wird nützlich, wenn Serviceerwartungen nicht nur versprochen, sondern messbar betrieben werden müssen.
Der Kunde erwartet stabile Verfügbarkeit, schnelle Wiederherstellung, klare Supportreaktion, planbare Wartungsfenster und transparente Berichte. Der Anbieter braucht Verantwortungsgrenzen, messbare Ziele, Eskalationsregeln und eine Bewertung auf Basis von Nachweisen. Das SLA verbindet diese Anforderungen.
Die Betriebslogik hinter messbaren Servicezusagen
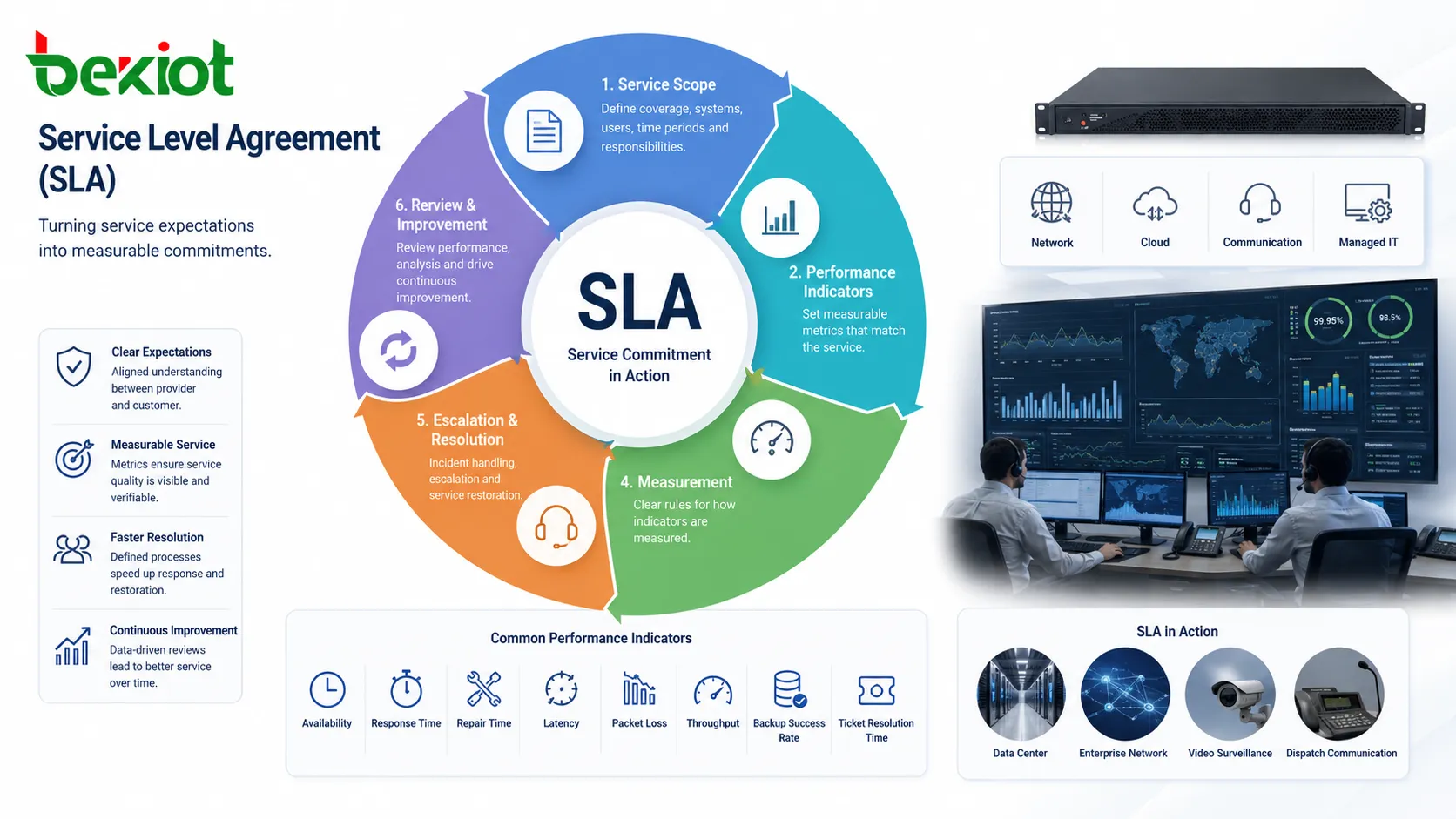
Ein Service Level Agreement, kurz SLA, ist eine formelle Vereinbarung über das erwartete Serviceniveau zwischen Anbieter und Kunde. Es kann für Netzwerke, Cloud-Plattformen, Rechenzentren, Kommunikationssysteme, Managed IT, Software, Wartung und Sicherheitsbetrieb gelten.
Der Betrieb beginnt mit dem Leistungsumfang: welche Dienste, Systeme, Standorte, Nutzer, Zeiträume und Verantwortlichkeiten gelten. Ohne diesen Umfang bleibt die spätere Leistungsbewertung unklar.
Danach definiert die Vereinbarung Kennzahlen wie Verfügbarkeit, Reaktionszeit, Reparaturzeit, Wiederherstellungszeit, Incident-Bearbeitung, Backup-Erfolg, Ticketlösung, Latenz, Paketverlust, Durchsatz oder Supportzeiten. Die Kennzahlen müssen zum Dienst passen.
Das SLA legt auch fest, wie diese Werte gemessen werden. Verfügbarkeit kann monatlich oder jährlich, am Rand des Anbieters oder beim Kunden gemessen werden und geplante Wartung einschließen oder ausschließen. Klare Messregeln sind entscheidend.
In der Praxis ist ein SLA ein fortlaufender Rahmen für Servicemanagement. Es setzt Erwartungen, steuert Monitoring, unterstützt Eskalation bei Störungen und liefert Belege für die spätere Bewertung.
Vom Vertragstext zur täglichen Serviceausführung
Ein SLA ist oft ein Dokument, aber sein Wert entsteht erst in der täglichen Ausführung. Es muss Monitoring, Ticketbearbeitung, Incident-Reaktion, Kundeninformationen und Leistungsreviews beeinflussen.
Die tägliche Umsetzung startet meist mit Monitoring. Bei Netzwerkdiensten werden Verfügbarkeit, Latenz, Jitter, Paketverlust, Schnittstellen und Gerätegesundheit überwacht. Bei Cloud- oder Softwarediensten zählen Anwendungsverfügbarkeit, Transaktionserfolg, API-Zeit, Ressourcennutzung und Fehler.
Incident-Management ist ein weiterer Kern. Das SLA definiert, wie schnell ein Problem bestätigt wird, wie es klassifiziert wird, wie Eskalation funktioniert und welches Wiederherstellungsziel gilt. Kritische Fälle benötigen schnelle Reaktion und häufige Updates.
Das SLA beeinflusst auch Personal und Supportstruktur. Wer 24/7-Reaktion verspricht, braucht Menschen, Werkzeuge und Prozesse dafür. Strenge Reparaturzeiten für kritische Geräte erfordern Ersatzteile, Fernzugriff und Außendienstbereitschaft.
Kundenkommunikation gehört ebenfalls zur Ausführung. Während einer Störung muss der Kunde wissen, ob der Fall angenommen wurde, welche Auswirkungen bestehen, welche Maßnahmen laufen und wann die nächste Information kommt.
Leistungsindikatoren, die dem Vertrag Bedeutung geben
Die Qualität eines SLA hängt stark von den Kennzahlen ab. Unklare Aussagen wie hohe Zuverlässigkeit oder schneller Support reichen nicht aus. Messbare Werte machen die Leistung für beide Seiten beurteilbar.
Verfügbarkeit ist eine der häufigsten Kennzahlen. Sie beschreibt, wie lange ein Dienst in einem definierten Zeitraum nutzbar ist. Die Berechnung muss klären, ob Wartung, kundenseitige Fehler, höhere Gewalt oder Dritte ausgeschlossen werden.
Reaktionszeit beschreibt, wie schnell der Anbieter einen Vorfall bestätigt oder mit der Bearbeitung beginnt. Sie ist nicht identisch mit Reparaturzeit. Beide Werte sind wichtig, messen aber unterschiedliche Phasen.
Lösungs- oder Wiederherstellungszeit misst, wie lange der Dienst braucht, um wieder normal oder akzeptabel zu funktionieren. Für geschäftskritische Systeme ist diese Kennzahl besonders wichtig und oft nach Schweregrad gestaffelt.
Weitere Kennzahlen können Latenz, Jitter, Paketverlust, Durchsatz, Transaktionserfolg, Backup-Abschluss, Recovery Point, Helpdesk-Verfügbarkeit, Sicherheitsreaktionszeit oder vorbeugende Wartung sein. Sie müssen die reale Abhängigkeit des Kunden abbilden.
Wie Schweregrade das Reaktionsverhalten prägen
Viele SLAs nutzen Schweregrade, um Vorfälle zu klassifizieren. So werden Totalausfall, Teilleistungsabfall, kleiner Fehler, Informationsanfrage und geplante Änderung nicht gleich behandelt.
Ein schwerer Vorfall kann vollständige Unterbrechung, Sicherheitsauswirkung, erheblichen Geschäftsschaden oder Verlust einer kritischen Funktion bedeuten. Er verlangt sofortige Bestätigung, schnelle Eskalation, erfahrene Techniker, häufige Updates und ein strenges Ziel.
Der Schweregrad muss nach Auswirkung und nicht nach Gefühl definiert sein. Kunden empfinden vieles als dringend, Anbieter klassifizieren oft vorsichtig. Klare Definitionen reduzieren Streit in angespannten Situationen.
Der Schweregrad steuert auch die Eskalation. Wenn ein Fehler nicht rechtzeitig gelöst wird, kann er an höhere Supportebenen, Management oder zusätzliche Berichte gehen. Dadurch bleiben ernste Fälle nicht im First Level stecken.
In reifen Betriebsmodellen werden Schweregraddaten regelmäßig geprüft. Viele kritische Fälle deuten auf Design- oder Stabilitätsprobleme hin; häufige Umklassifizierungen zeigen unklare Definitionen.
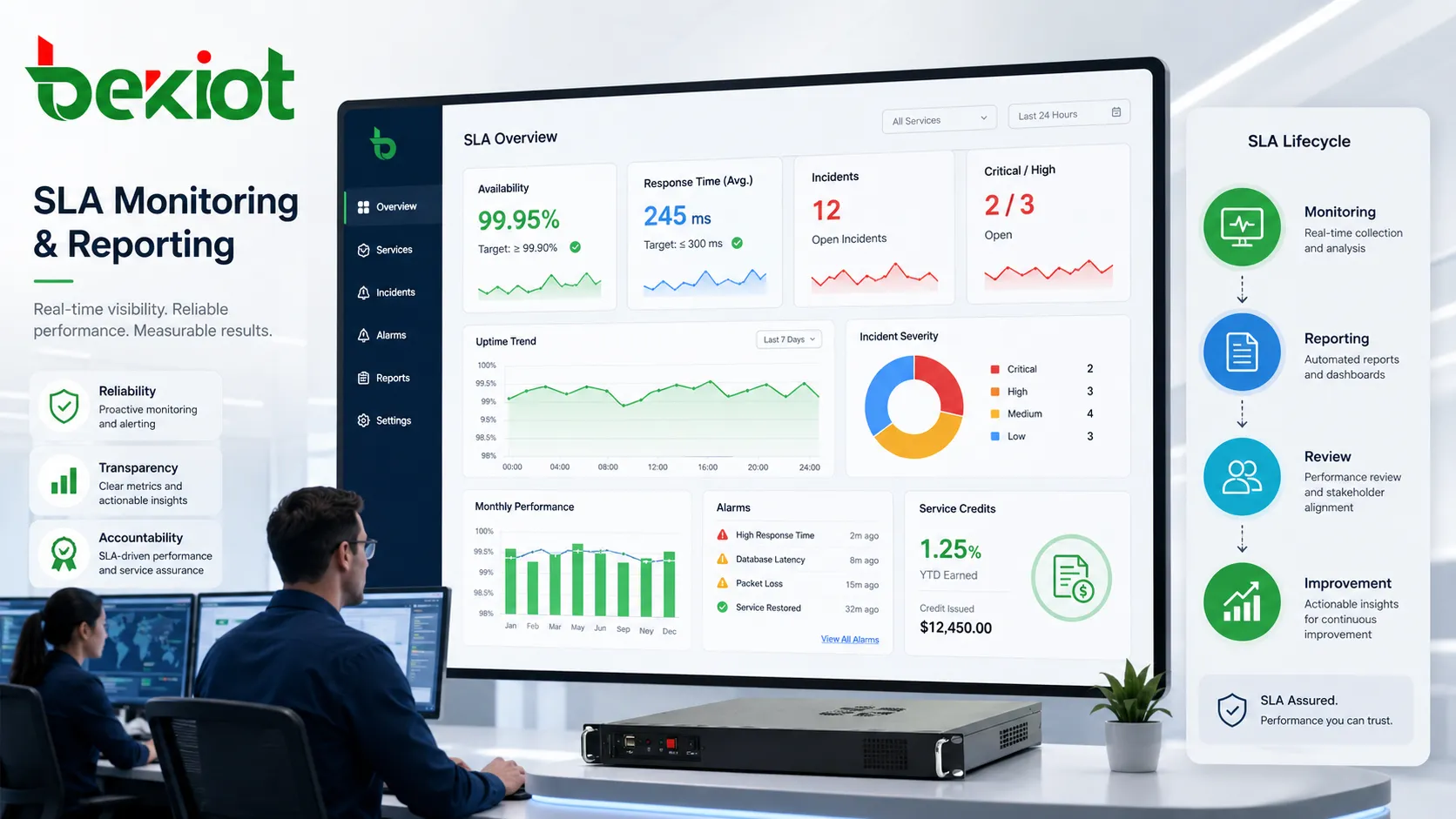
Monitoring und Reporting als Nachweisebene
Ohne Nachweise lässt sich ein SLA kaum durchsetzen oder verbessern. Monitoring und Berichte zeigen, ob Ziele erreicht wurden, wo sich Qualität verändert, welche Vorfälle auftraten, wie schnell Teams reagierten und ob Muster entstehen.
Monitoring kann automatisch oder manuell erfolgen. Tools erfassen Verfügbarkeit, Verkehr, Gerätestatus, Servergesundheit, Transaktionen, Alarme, Antwortzeiten und Fehler. Manuelle Aufzeichnungen ergänzen Wartungsbesuche, Kundenfeedback, Supportnotizen und Nachberichte.
Die Berichtshäufigkeit muss zum Dienst passen. Kritische Dienste benötigen Echtzeit-Dashboards, Tageszusammenfassungen oder sofortige Benachrichtigungen. Standarddienste nutzen oft Monatsberichte, Wartungsverträge Quartalsreviews.
Datenqualität ist entscheidend. Wird nur im Rechenzentrum des Anbieters gemessen, können Zugangsprobleme beim Kunden verborgen bleiben. Das SLA muss Messpunkte und Erfassungsmethoden klar definieren.
Gute Berichte schaffen Transparenz und reduzieren Streit. Sie zeigen wiederholte Ausfälle, langsame Reaktionen oder schwache Module und lenken Verbesserungen auf echte Muster.
Eskalation, Abhilfen und Servicegutschriften
Ein SLA muss definieren, was bei Zielverfehlung geschieht. Eskalation, Abhilfen und Servicegutschriften schaffen Verantwortung und zwingen beide Seiten, Probleme ernst zu behandeln.
Eskalation beschreibt, wie ungelöste Fälle durch die Supportstruktur wandern: erster Support, Spezialisten, Hersteller, Betriebszentrum oder Management. Sie braucht Schwellen, Kontaktwege, Verantwortliche und Update-Regeln.
Abhilfen beschreiben Folgen verfehlter Servicelevel: Gutschriften, Korrekturpläne, Wartungsverlängerungen, Managementreview oder Kündigungsrechte bei wiederholten Ausfällen.
Servicegutschriften müssen vorsichtig gestaltet werden. Sie können finanziell ausgleichen, decken aber selten den ganzen Geschäftsschaden. Für kritische Systeme zählen Wiederherstellung und Prävention mehr als kleine Gutschriften.
Ausschlüsse sind wichtig. Gutschriften können entfallen, wenn die Ursache in Kundeneinstellungen, unautorisierten Änderungen, Stromausfall außerhalb der Kontrolle, geplanter Wartung, höherer Gewalt oder Dritten liegt.
Vorteile für Kunden und Dienstanbieter
Für Kunden ist der Hauptvorteil Vorhersehbarkeit. Sie kennen erwartete Leistung, Reaktionszeiten, abgedeckte Dienste und Nachweise. Das unterstützt Planung, Risikomanagement und interne Verantwortlichkeit.
Das SLA hilft Kunden auch beim Vergleich von Anbietern. Ähnliche Preise und Funktionen können sehr unterschiedliche Zusagen bei Verfügbarkeit, Antwort, Eskalation, Reporting oder Wartungsfenstern enthalten.
Für Anbieter definiert ein SLA Grenzen. Es klärt, was enthalten ist, was ausgeschlossen ist, wie Vorfälle klassifiziert werden und welche Pflichten der Kunde hat. Dadurch werden unrealistische Erwartungen reduziert.
Es verbessert auch internes Management. Support priorisiert nach Schweregrad und Vertrag, Betrieb erkennt wiederkehrende Probleme, Vertrieb erklärt Servicewert und Finanzen bewerten Risiken aus Gutschriften oder Strafen.
Der größte Vorteil für beide Seiten ist Ausrichtung. Kundenerwartung und Lieferprozess des Anbieters werden über vereinbarte Kennzahlen und Verfahren verbunden.
Operativer Wert über den Vertragsschutz hinaus
Einige Organisationen sehen das SLA vor allem als Rechtsdokument, doch der operative Wert ist oft größer. Es fördert Monitoring, Dokumentation, Eskalation, Ursachenanalyse, Kapazitätsplanung und kontinuierliche Verbesserung.
Wenn das SLA strenge Reaktionsziele definiert, müssen Supportkanäle überwacht werden. Definiert es Verfügbarkeit, braucht der Anbieter Redundanz, Backups und Incident-Erkennung. Definiert es Reporting, müssen Daten gesammelt werden.
Auch Kunden profitieren operativ. Interne Teams nutzen SLA-Berichte, um Abhängigkeiten zu verstehen, Upgrades zu begründen, Wartungsfenster zu planen und Risiken sichtbar zu machen.
In komplexen Umgebungen unterstützen SLAs die Koordination mehrerer Anbieter für Cloud, Netzwerk, Sicherheit und Vor-Ort-Wartung. Sie zeigen Schnittstellen und mögliche Lücken.
Richtig genutzt wird das SLA Teil der Service-Governance. Es verlagert Servicearbeit von reaktiven Beschwerden zu strukturierter Leistungskontrolle.
Häufige Fehler beim SLA-Design
Ein häufiger Fehler sind beeindruckende Zahlen ohne praktikable Messregeln. Eine hohe Verfügbarkeitszusage ist schwach, wenn zu viele Ausnahmen gelten oder der Messpunkt die Kundenerfahrung nicht abbildet.
Ein weiterer Fehler sind zu viele Metriken. Eine lange Liste wirkt vollständig, macht Management aber kompliziert und unfokussiert. Gute Metriken hängen direkt mit Geschäftsauswirkung, Qualität oder Risiko zusammen.
Unklare Schweregrade sind ebenfalls häufig. Das SLA sollte Auswirkungsstufen klar beschreiben und nach Möglichkeit Beispiele enthalten, damit die Klassifizierung schnell und konsistent erfolgt.
Manche SLAs scheitern, weil Verantwortlichkeiten einseitig sind. Servicequalität hängt auch von Kundenzugang, genauen Meldungen, genehmigten Wartungsfenstern, Kontakten, Stromversorgung und Konfigurationshilfe ab.
Ein letzter Fehler ist fehlende Aktualisierung nach Serviceänderungen. Geschäftsbedarf, Nutzerzahl, Architektur, Sicherheit und Abhängigkeiten verändern sich. Regelmäßige Reviews halten das SLA realistisch.
Woran erkennt man ein wirksames SLA?
Ein wirksames SLA ist klar, messbar, relevant, realistisch und durchsetzbar. Beide Parteien müssen Umfang, Ziele, Messregeln, Schweregrade, Reporting und Abhilfen verstehen.
Messbarkeit bedeutet, dass Leistung mit zuverlässigen Daten überprüft wird. Das SLA muss Datenquelle, Berechnung und Streitbeilegung nennen.
Relevanz bedeutet, dass gemessen wird, was für den Kundenbetrieb zählt. Technische Werte sind nur nützlich, wenn sie Serviceerfahrung oder Geschäftsauswirkung berühren.
Realismus bedeutet, dass Ziele zu Architektur, Budget, Personal, Risiko und Umgebung passen. Ein gutes SLA verbindet Anspruch mit Machbarkeit.
Durchsetzbarkeit bedeutet, dass verfehlte Ziele definierte Aktionen auslösen: Eskalation, Korrektur, Gutschrift, Managementreview oder Verbesserungsplan.

FAQ
Wird ein SLA nur für ausgelagerte Dienste benötigt?
Nein. SLAs sind für externe Dienste nützlich, aber auch intern zwischen IT, Facility, Geschäftsbereichen oder Shared-Service-Centern.
Was ist der Unterschied zwischen SLA und KPI?
Ein SLA ist eine Vereinbarung über Servicezusagen. Ein KPI ist eine Kennzahl zur Leistungsmessung. SLA-Ziele nutzen oft KPI, aber nicht jeder KPI ist vertraglich.
Kann ein SLA garantieren, dass keine Ausfälle auftreten?
Nein. Ein SLA verhindert keine Ausfälle. Es definiert erwartete Leistung, Reaktion, Messung und Abhilfe. Gutes Design reduziert das Risiko.
Wer sollte SLA-Berichte prüfen?
Betriebsteams und Management sollten sie prüfen. Techniker brauchen Details zur Verbesserung, Manager Trends, Risiken und Geschäftsnachweise.
Wie oft sollte ein SLA aktualisiert werden?
Es sollte geprüft werden, wenn Umfang, Architektur, Nutzerzahl, Geschäftsabhängigkeit, Compliance oder Verantwortlichkeiten wechseln, und zusätzlich regelmäßig.