Ein System-Upgrade sollte niemals mit dem Installationspaket beginnen.Es sollte mit einer einfachen Betriebsfrage beginnen: Was muss während der Änderung stabil bleiben? Eine neue Version kann Sicherheitspatches, bessere Leistung, neue Funktionen oder längeren Support bringen, sie kann aber auch Kompatibilitätsprobleme, Konfigurationsänderungen, Serviceunterbrechungen und Wiederherstellungsdruck verursachen.
Gutes Upgrade-Management bedeutet deshalb nicht nur, im richtigen Moment auf „Aktualisieren“ zu klicken. Es bedeutet, Änderungen so zu kontrollieren, dass Dienste, Benutzer, Daten und Geschäftskontinuität geschützt bleiben.
Mit dem Grund der Änderung beginnen
Die erste Regel besteht darin, klar zu bestätigen, warum das Upgrade nötig ist. Manche Upgrades sind dringend, weil sie Sicherheitslücken, schwere Fehler, Compliance-Risiken oder das Ende des Supports betreffen. Andere sind geplant, weil sie Leistung verbessern, Funktionen ergänzen, neue Hardware unterstützen oder die künftige Architektur vorbereiten. Optionale Upgrades sollten warten, bis genügend Testzeit vorhanden ist.
Ohne klaren Grund werden Upgrade-Entscheidungen schnell reaktiv. Ein Team aktualisiert vielleicht nur, weil eine neue Version verfügbar ist, der Hersteller sie empfiehlt oder eine andere Abteilung bereits umgestellt hat. Das erzeugt unnötige Risiken. Ein stabiles System sollte nicht ohne klaren Nutzen verändert werden.
Der Zweck des Upgrades sollte praktisch formuliert werden, etwa „Authentifizierungslücke schließen“, „neue Datenbankversion unterstützen“, „Anrufverarbeitungskapazität erhöhen“, „nicht unterstütztes Betriebssystem ersetzen“ oder „Integration mit einer neuen Plattform ermöglichen“. Ein klarer Zweck erleichtert später Testumfang und Abnahmekriterien.
Ist der Grund eindeutig, kann das Projektteam auch die Dringlichkeit bestimmen. Ein kritisches Sicherheits-Upgrade braucht eventuell einen kurzen Freigabeweg, ein Funktions-Upgrade kann in ein risikoarmes Wartungsfenster gelegt werden, und ein Architektur-Upgrade kann eine stufenweise Einführung erfordern.
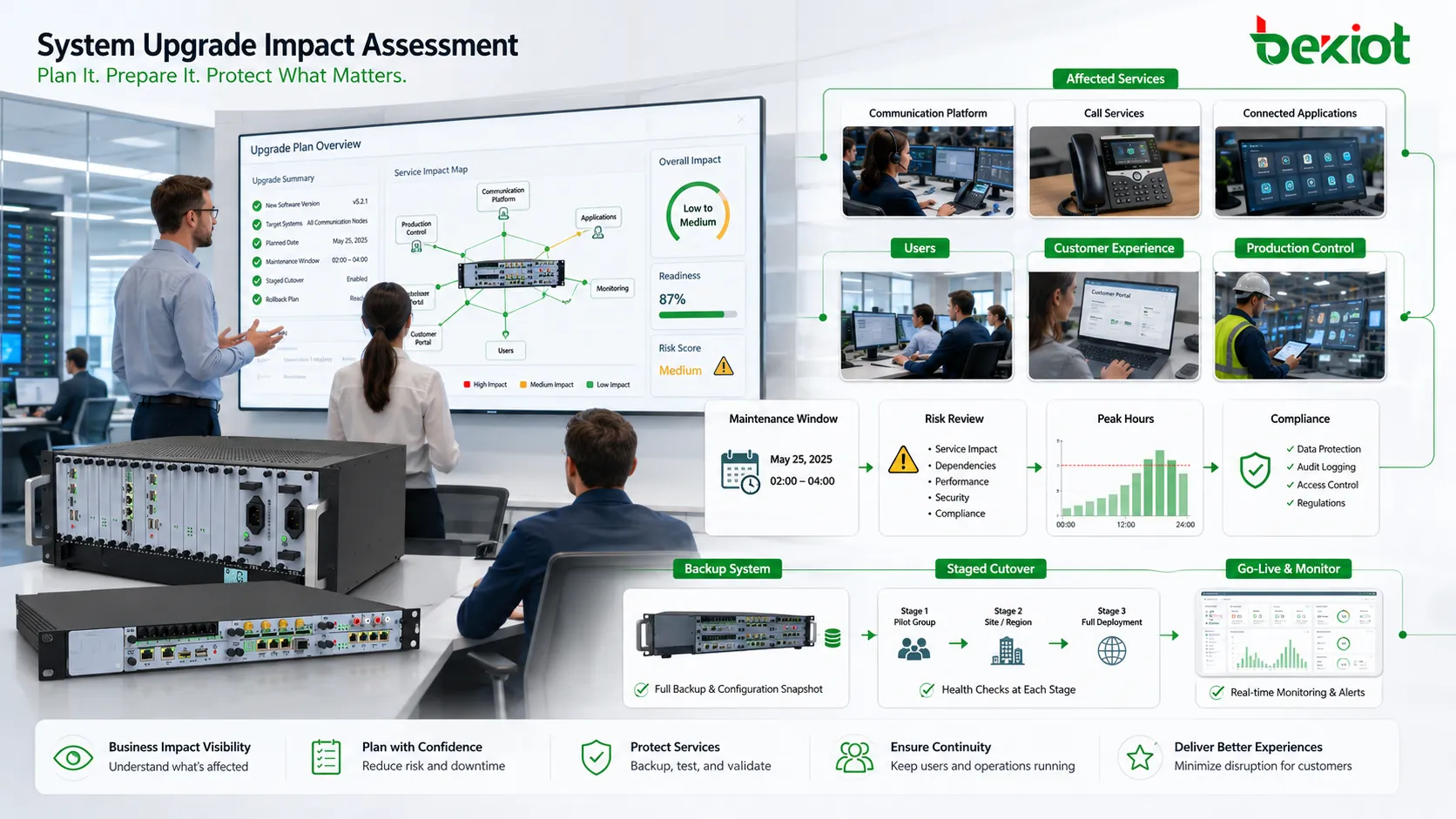
Geschäftliche Auswirkungen vor technischen Aktionen prüfen
Jedes Upgrade betrifft mehr als die Technik. Es kann Benutzer, Servicefenster, verbundene Anwendungen, Berichte, Zugriffsrechte, Geräte, Kundenerlebnis, Produktionsabläufe oder Supportteams beeinflussen. Vor technischen Schritten muss das Team klären, welche Geschäftsprozesse vom System abhängen.
Besonders wichtig ist dies bei Systemen im Dauerbetrieb, etwa Kommunikationsplattformen, Datenbanken, Industriesystemen, Kundenportalen, Zahlungssystemen, Monitoring-Plattformen und internen Betriebswerkzeugen. Selbst kurze Unterbrechungen können verpasste Anrufe, fehlgeschlagene Transaktionen, Produktionsverzögerungen, unvollständige Datensätze oder Beschwerden auslösen.
Die Impact-Analyse sollte Spitzenzeiten, kritische Benutzergruppen, externe Kunden, interne Abteilungen, Service-Level-Zusagen sowie rechtliche und Compliance-Anforderungen einbeziehen. Unterstützt das System Notfallreaktion, Produktionssteuerung, Sicherheitsüberwachung oder öffentliche Dienste, muss der Upgrade-Plan strenger sein als bei gewöhnlichen Bürotools.
Das Ergebnis dieser Prüfung steuert die Terminplanung. Manche Upgrades passen in normale Wartungszeiten, andere benötigen Nacht- oder Wochenendfenster. Manche erfordern temporäre Ersatzsysteme, Benutzerhinweise oder stufenweise Umschaltung. Auch ein technisch einfaches Upgrade kann riskant sein, wenn der Zeitpunkt falsch ist.
Zuerst ein genaues Inventar erstellen
Ein System lässt sich nicht sicher aktualisieren, wenn das Team nicht weiß, was damit verbunden ist. Das Inventar sollte Server, Betriebssysteme, Datenbanken, Middleware, Anwendungen, Endpunkte, Netzwerkgeräte, Speicher, Lizenzen, Zertifikate, APIs, Drittintegrationen, Backup-Werkzeuge, Monitoring-Systeme und Zugriffsmethoden enthalten.
Dieses Inventar deckt versteckte Abhängigkeiten auf. Ein Reporting-Tool kann von einer Datenbankversion abhängen, ein alter Client kann ein neues Protokoll nicht unterstützen, ein Gerät kann nach Firmwareänderungen ausfallen, und ein Sicherheitssystem kann eine veraltete API nutzen. Werden solche Abhängigkeiten erst nach der Einführung entdeckt, steigt der Rollback-Druck.
Auch das Konfigurationsinventar ist wichtig. Systemparameter, Routingregeln, Benutzerrechte, Integrationsschlüssel, geplante Jobs, Dienstkonten, Firewall-Regeln, Zertifikate und eigene Skripte müssen vor dem Upgrade dokumentiert werden. Viele Ausfälle entstehen nicht durch die neue Version, sondern durch verlorene oder überschriebenen Einstellungen.
In großen Umgebungen muss das Inventar außerdem Versionsunterschiede zwischen Standorten oder Knoten zeigen. Eine Niederlassung kann einen anderen Patchstand haben, ein Server ein Sondermodul enthalten, ein Gerätemodell einen speziellen Firmwarepfad brauchen. Diese Unterschiede beeinflussen Reihenfolge und Testdesign.
Kompatibilität bestätigen statt voraussetzen
Kompatibilität gehört zu den häufigsten Upgrade-Risiken. Eine neue Version kann eine neuere Datenbank, eine andere Laufzeitbibliothek, einen aktualisierten Browser, geänderte Treiber, eine überarbeitete API oder eine andere Authentifizierung verlangen. Sind angebundene Systeme nicht kompatibel, kann das Upgrade technisch erfolgreich und betrieblich dennoch fehlerhaft sein.
Die Prüfung sollte Hardware, Betriebssystem, Datenbank, Anwendungsversion, Protokoll, Schnittstelle, Browser, mobilen Client, Endgerät, Treiber, Plug-in, Zertifikat und Drittservice abdecken. Das Team sollte sich nicht allein auf allgemeine Release Notes verlassen, sondern Projektbedingungen mit Herstelleranforderungen und lokaler Konfiguration vergleichen.
Rückwärtskompatibilität ist ebenfalls wichtig. Wenn alte Clients, Geräte oder Integrationen nach dem Upgrade weiterarbeiten müssen, sollten sie direkt getestet werden. Manche Systeme erlauben für kurze Zeit Mischversionen, andere verlangen ein gemeinsames Upgrade aller Komponenten. Eine Fehleinschätzung kann Teilausfälle verursachen.
Bei unklarer Kompatibilität sollte eine Pilotumgebung genutzt werden. Dort kann das Team repräsentative Geräte, Rollen, Datenflüsse und Schnittstellenaufrufe testen, bevor Produktion berührt wird. So sinkt die Wahrscheinlichkeit, große Konflikte erst im Wartungsfenster zu entdecken.
| Upgrade-Bereich | Wichtige Regel | Grund der Prüfung |
|---|---|---|
| Anwendungsversion | Release Notes und Abhängigkeitsänderungen prüfen | Verhindert Funktionsverlust und Schnittstellenkonflikte |
| Datenbank | Schema, Treiber und Migrationsanforderungen prüfen | Schützt Datenzugriff und Transaktionsstabilität |
| Betriebssystem | Runtime-, Dienst- und Sicherheitsrichtlinienunterstützung bestätigen | Vermeidet Start- und Rechteprobleme |
| Netzwerk und Sicherheit | Firewall, Zertifikate, DNS und Zugriffsregeln prüfen | Verhindert Verbindungsfehler nach der Umschaltung |
| Endpunkte und Clients | Repräsentative Geräte und Versionen testen | Reduziert Kompatibilitätsbeschwerden im Feld |
Daten vor der Änderung der Umgebung schützen
Datenschutz ist eine nicht verhandelbare Regel. Vor dem Upgrade müssen Verfügbarkeit, Integrität, Wiederherstellungsmethode, Speicherort, Aufbewahrungspolitik und Wiederherstellungszeit des Backups bestätigt werden. Ein nie getestetes Backup ist eine Annahme, kein Wiederherstellungsplan.
Bei Datenbanken und Anwendungsplattformen muss das Backup zum richtigen Zeitpunkt erfolgen. Ändern sich Daten während des Upgrades weiter, muss entschieden werden, ob Schreibzugriffe gestoppt, Transaktionslogs genutzt, Snapshots erstellt oder eine replizierte Wiederherstellung vorbereitet werden. Die Methode hängt von Architektur und akzeptabler Ausfallzeit ab.
Konfigurationsbackups dürfen nicht vergessen werden. Anwendungseinstellungen, Dienstdateien, Routingtabellen, geplante Aufgaben, Rollen, Zertifikate, Schlüssel und eigene Vorlagen können ebenso wichtig sein wie Geschäftsdaten. Nach einem Fehlschlag kann ihre manuelle Rekonstruktion länger dauern als die Softwarewiederherstellung.
Auch Datenmigrationsskripte müssen genau geprüft werden. Manche Upgrades ändern Schema, Indizes, Codierung, Feldlängen oder Datenstruktur. Solche Änderungen sind schwer rückgängig zu machen. Das Team muss wissen, ob Migration reversibel ist, ob ein vollständiges Restore nötig wird und wie lange die Wiederherstellung dauert.
Eine Testumgebung mit realen Bedingungen nutzen
Tests sind nur wertvoll, wenn die Umgebung in den wichtigen Punkten der Produktion ähnelt. Ein kleines leeres Testsystem zeigt vielleicht, dass der Installer läuft, aber nicht unbedingt Leistungsprobleme, Migrationsfehler, Integrationsausfälle, Rechtekonflikte oder Geräteinkompatibilität.
Die Testumgebung sollte repräsentative Daten, Benutzerrollen, verbundene Dienste, Einstellungen, Schnittstellenaufrufe und typische Lasten enthalten. Sie muss keine perfekte Produktionskopie sein, aber genug Realität enthalten, um die Hauptrisiken sichtbar zu machen.
Testfälle sollten echten Arbeitsabläufen folgen. Benutzer sollten sich anmelden, Datensätze anlegen, Berichte ausführen, Transaktionen durchführen, Alarme auslösen, APIs aufrufen, Dateien erzeugen, mobile Clients nutzen oder angeschlossene Geräte bedienen. Ein erfolgreicher Start bedeutet noch keine Betriebsbereitschaft.
Bei Bedarf sind Leistungstests nötig. Eine neue Version kann mit einem Benutzer funktionieren und unter echter Last langsamer werden. Datenbankmigration, Cache, Speicher, CPU, Festplatten-I/O, Netzwerklatenz und Hintergrundjobs sollten beobachtet werden. Bewertet wird der Betrieb, nicht nur die Installation.

Rollback vor der Bereitstellung vorbereiten
Ein Upgrade sollte nicht ohne Rollback-Überlegung fortgesetzt werden. Rollback bedeutet, das System bei Fehlern oder inakzeptablen Problemen in den vorherigen funktionsfähigen Zustand zurückzubringen. „Wir stellen bei Bedarf das Backup wieder her“ reicht nicht aus; der genaue Ablauf muss bekannt sein.
Der Rollback-Plan definiert, wer entscheidet, welche Bedingungen ihn auslösen, welche Dateien oder Datenbanken wiederhergestellt werden, wie lange die Wiederherstellung dauert, welche Daten verloren gehen können und wie Benutzer informiert werden. Er muss auch klären, ob nach einer Migration ein Rollback möglich ist oder nur eine Vorwärtsreparatur bleibt.
Manche Upgrades sind leicht rückgängig zu machen. Andere ändern Datenbankstrukturen, Verschlüsselung, Firmware oder Konfigurationsformate so, dass ein Zurück schwierig wird. Dann sind stufenweise Einführung, Blue-Green-Architektur, Ersatzknoten oder Parallelbetrieb sinnvoll.
Rollback sollte nach Möglichkeit getestet werden. Ein ungeübter Plan kann im Notfall scheitern. Schon eine Teilprobe kann fehlende Rechte, langsame Restores, unvollständige Backups oder unklare Zuständigkeiten aufdecken.
Das Wartungsfenster kontrollieren
Das Wartungsfenster ist der geplante Zeitraum für das Upgrade. Es sollte nach Benutzerwirkung, Systemlast, Verfügbarkeit der Mitarbeiter, Herstellersupport, abgeschlossenen Backups und Rollback-Dauer gewählt werden. Ein häufiger Fehler ist, nur für das Upgrade selbst Zeit einzuplanen, nicht für Fehleranalyse oder Rückkehr.
Das Fenster muss Vorbereitung, finales Backup, Durchführung, Prüfung, mögliche Reparatur, Rollback-Entscheidung, Rollback-Ausführung und Benutzerkommunikation enthalten. Wenn das Upgrade eine Stunde dauert, der Rollback aber drei, muss die Planung das berücksichtigen.
Vor dem Upgrade kann ein Change Freeze nötig sein. Andere Teams sollten in derselben Zeit keine unabhängigen Konfigurations-, Netzwerk-, Datenbank- oder Zugriffsänderungen vornehmen. Mehrere gleichzeitige Änderungen erschweren die Fehlersuche erheblich.
Auch Supportverfügbarkeit zählt. Schlüsseltechniker, Anwendungsverantwortliche, Netzwerkingenieure, Datenbankadministratoren, Security-Teams und Hersteller-Support müssen erreichbar sein. Das Upgrade darf nicht stattfinden, wenn nur eine nicht verfügbare Person eine kritische Abhängigkeit versteht.
Vor und nach der Änderung mit Benutzern kommunizieren
Benutzerkommunikation verhindert Verwirrung. Vor dem Upgrade sollten betroffene Benutzer Zeitplan, Serviceauswirkung, temporäre Einschränkungen, Kontaktweg und zu vermeidende Aktionen kennen. Bei öffentlichen Systemen kann zusätzlich Kundenkommunikation nötig sein.
Die Nachricht sollte konkret, aber nicht technisch überladen sein. Benutzer müssen wissen, ob das System nicht verfügbar ist, ob Dateneingaben gestoppt werden sollen, ob mobile Clients aktualisiert werden müssen, ob Passwörter oder Loginmethoden wechseln und wann der Dienst zurückkehrt.
Nach dem Upgrade sollten Benutzer eine Bestätigung der Verfügbarkeit erhalten. Haben sich Funktionen geändert, können kurze Release Notes oder Nutzungshinweise nötig sein. Bleiben Probleme offen, sollte das Team bekannte Einschränkungen und nächste Lösungsschritte nennen.
Gute Kommunikation reduziert unnötige Tickets. Viele Beschwerden nach Upgrades entstehen nicht durch technische Fehler, sondern durch überraschende Oberflächenänderungen, Loginaufforderungen, abgelaufene Sitzungen oder vorübergehende Leistungsschwankungen.
Das Ergebnis mit Abnahmekontrollen prüfen
Ein Upgrade ist nicht fertig, wenn der Installer endet. Es ist erst abgeschlossen, wenn das System die Abnahmekontrollen bestanden hat. Diese Kontrollen müssen vor Beginn definiert werden, damit alle wissen, was „erfolgreich“ bedeutet.
Abnahmen können Dienststart, Anmeldung, Kernprozesse, Datenlesen und -schreiben, Berichtserstellung, Schnittstellenaufrufe, Geräteverbindung, geplante Aufgaben, Rechteprüfung, Backup-Funktion, Monitoringstatus und Benutzerbestätigung umfassen. Die genaue Liste hängt von der Systemfunktion ab.
Kritische Funktionen werden zuerst getestet. Unterstützt das System Transaktionen, werden Transaktionen getestet; unterstützt es Kommunikation, werden Anrufwege oder Nachrichtenflüsse geprüft; unterstützt es Monitoring, werden Alarme und Dashboards geprüft; stellt es Datenbankdienste bereit, werden Anwendungszugriff und Abfragen getestet. Nebenthemen dürfen nicht vor Kernservices stehen.
Zur Abnahme gehört auch die Logprüfung. Fehlerlogs, Warnungen, fehlgeschlagene Jobs, Authentifizierungsfehler, Migrationsmeldungen und Integrationsfehler können Probleme zeigen, bevor Benutzer sie bemerken. Ein sauberer Bildschirm bedeutet nicht automatisch ein sauberes Upgrade.

Das System nach der Freigabe überwachen
Die ersten Stunden und Tage nach dem Upgrade sind wichtig. Manche Probleme erscheinen erst unter realem Verkehr, geplanten Jobs, Spitzenlast oder bestimmten Benutzerhandlungen. Das Monitoring danach sollte aktiver sein als im Normalbetrieb, besonders bei kritischen Systemen.
Überwacht werden sollten CPU, Speicher, Festplatte, Datenbankleistung, Netzwerkverkehr, Dienststatus, Fehlerlogs, Benutzersitzungen, Transaktionserfolg, API-Antwort, Warteschlangenlänge und Speicherwachstum. Auch Benutzerfeedback ist wichtig, weil manche Störungen für Benutzer früher sichtbar sind als in Dashboards.
Leistungsbaselines helfen. Kennt das Team Antwortzeiten, Ressourcennutzung und Fehlerraten vor dem Upgrade, kann es die neue Version objektiver bewerten. Ohne Basiswerte lässt sich schwer sagen, ob eine Verlangsamung neu oder historisch ist.
Die Dauer des Monitorings muss definiert sein. Kleine Systeme brauchen vielleicht nur einige Stunden, kritische Systeme mehrere Tage oder einen vollständigen Geschäftszyklus. Das Upgrade sollte erst geschlossen werden, wenn der Betrieb unter normalen Bedingungen stabil ist.
Alle Änderungen dokumentieren
Dokumentation ist Teil des Upgrades und keine optionale Verwaltungsaufgabe. Das Team sollte festhalten, welche Version installiert wurde, welche Konfiguration geändert wurde, welche Backups erstellt wurden, welche Probleme auftraten, wie sie gelöst wurden, wer genehmigte und welche Folgearbeiten offen sind.
Versionsaufzeichnungen sind besonders wichtig. Künftige Fehleranalyse hängt davon ab, welche System-, Datenbank-, Firmware-, Treiber- oder Patchversion läuft. Ohne Dokumentation müssen spätere Teams die Umgebung erneut rekonstruieren.
Bekannte Probleme gehören ebenfalls in die Aufzeichnung. Wenn eine Funktion später angepasst, eine Integration vom Anbieter bestätigt oder eine Benutzergruppe geschult werden muss, darf dies nicht nur in Chatnachrichten stehen. Es muss Teil des Upgrade-Protokolls sein.
Gute Dokumentation verbessert das nächste Upgrade. Das Team kann prüfen, was gut lief, was länger dauerte, welche Risiken übersehen wurden und welche Schritte verbessert werden sollten. Jedes Upgrade sollte die Organisation besser auf das nächste vorbereiten.
Zusammenfassung
Die wichtigste Regel für ein System-Upgrade ist kontrollierte Änderung. Ein erfolgreiches Upgrade schützt Daten, prüft Kompatibilität, begrenzt Ausfallzeit, bereitet Rollback vor, kommuniziert mit Benutzern und bestätigt das Serviceverhalten nach der Freigabe. Das Upgrade-Paket ist nur ein Teil des Prozesses.
In geschäftskritischen Umgebungen ist es am sichersten, Upgrades als vollständigen Betriebsablauf zu behandeln: Auswirkungen bewerten, realistisch testen, sorgfältig planen, mit klarer Verantwortung ausführen, Ergebnisse prüfen und danach überwachen. So werden Upgrades zur Verbesserung und nicht zur vermeidbaren Störung.
FAQ
Sollte jedes System sofort nach Erscheinen einer neuen Version aktualisiert werden?
Nein. Dringende Sicherheitskorrekturen können schnelles Handeln erfordern, Funktions- oder Hauptversions-Upgrades sollten aber zuerst bewertet werden. Kompatibilität, Geschäftsauswirkung, Testbereitschaft und Rollback-Optionen müssen vor der Einführung geprüft werden.
Was ist die wichtigste Vorbereitung vor einem Upgrade?
Am wichtigsten ist die Wiederherstellbarkeit. Dazu gehören getestete Backups, Konfigurationsaufzeichnungen, Rollback-Verfahren und klare Entscheidungsregeln. Ohne Vertrauen in die Wiederherstellung kann selbst ein einfaches Upgrade riskant werden.
Warum scheitern Upgrades trotz Tests?
Tests können reale Produktionsbedingungen verfehlen, etwa hohe Last, ungewöhnliche Daten, alte Clients, Drittintegrationen, geplante Jobs, Rechteunterschiede oder Netzwerkbeschränkungen. Die Testumgebung muss die wichtigsten Produktionsabhängigkeiten abbilden.
Wie lange sollte das Monitoring nach dem Upgrade dauern?
Das hängt von Bedeutung und Nutzungszyklus des Systems ab. Ein kleines internes Werkzeug braucht vielleicht nur kurze Überwachung, ein kritischer Dienst dagegen Spitzenzeiten, geplante Aufgaben und einen vollständigen Geschäftszyklus.
Was gehört in ein Upgrade-Protokoll?
Es sollte alte und neue Versionen, Zeitpunkt, Verantwortliche, Backup-Details, geänderte Konfiguration, Testergebnisse, gefundene Probleme, Rollback-Status, Benutzerbenachrichtigung und offene Folgeaktionen enthalten.