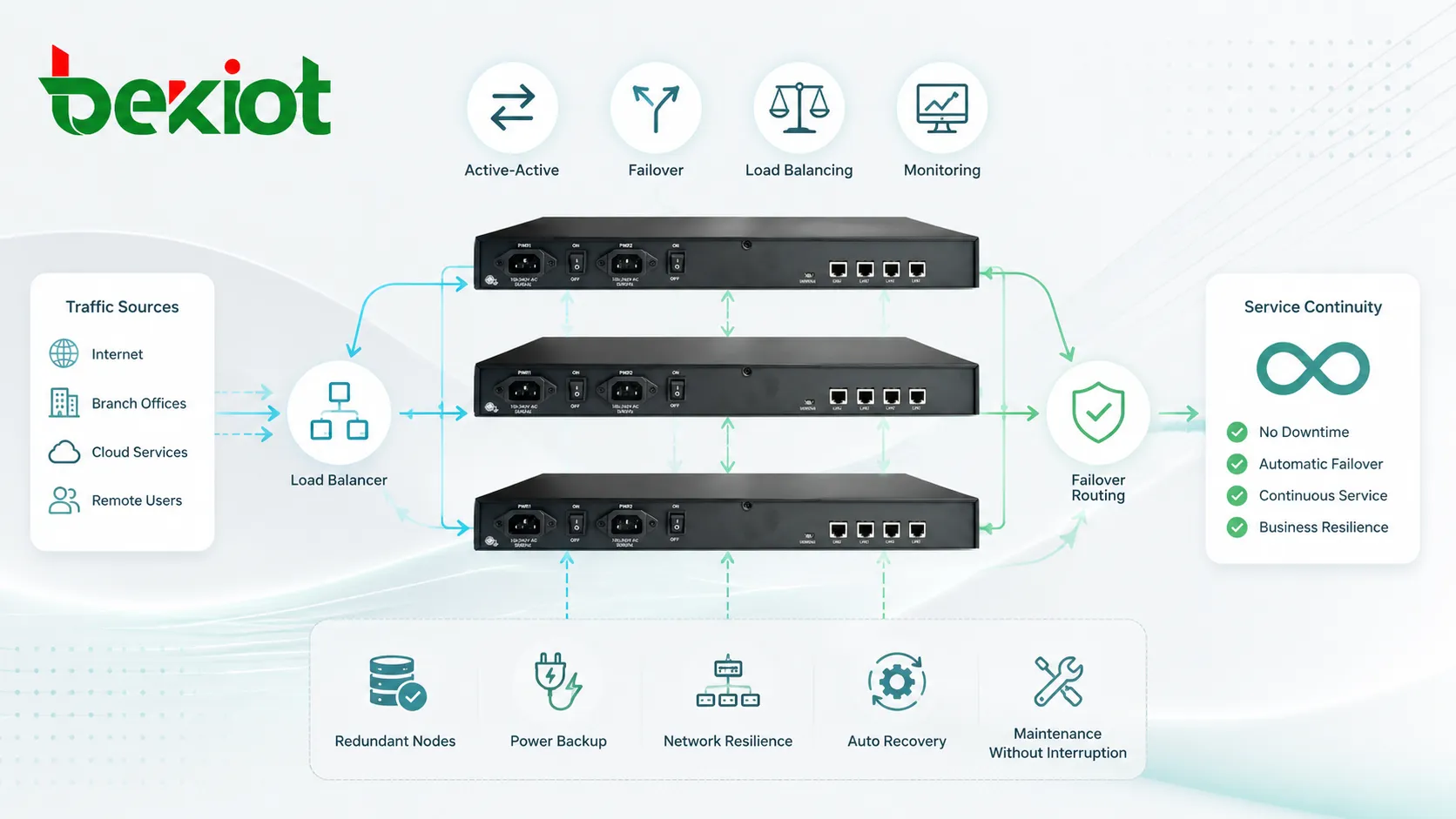
Ein Cluster ist eine Gruppe verbundener Computer, Server, Gateways, Geräte, Anwendungen oder Netzwerkknoten, die gemeinsam als koordiniertes System arbeiten. Statt von einer einzelnen Einheit abhängig zu sein, verteilt ein Cluster-Design Arbeitslasten, verbessert die Verfügbarkeit, unterstützt Failover und sorgt dafür, dass Dienste weiterlaufen können, wenn ein Teil des Systems ausfällt.
Der Begriff „Cluster“ wird in vielen Bereichen verwendet, darunter IT-Infrastruktur, Cloud Computing, Datenbanken, Kommunikationsplattformen, Telefoniesysteme, Funknetze, industrielle Automatisierung, Speichersysteme und Edge Computing. Auch wenn sich die technische Umsetzung unterscheidet, bleibt die Grundidee gleich: Mehrere Komponenten arbeiten zusammen, damit das Gesamtsystem zuverlässiger, skalierbarer und besser verwaltbar wird.

Die Grundidee hinter gruppierten Systemen
In einem einfachen Einzelsystem übernimmt ein Server oder Gerät den Dienst allein. Fällt diese Einheit aus, kann der Dienst stoppen. Steigt die Nachfrage, kann sie überlastet werden. Ist Wartung erforderlich, lässt sich eine Unterbrechung oft nur schwer vermeiden.
Ein Cluster-System ändert dieses Modell. Mehrere Knoten werden über ein Netzwerk verbunden und nach gemeinsamen Regeln verwaltet. Ein Knoten kann die aktuelle Last übernehmen, ein anderer als Reserve warten, oder alle Knoten verarbeiten gemeinsam Datenverkehr. Das Design hängt vom Ziel des Systems ab.
In einer Business-Kommunikationsplattform können beispielsweise mehrere Server Benutzerregistrierung, Anrufrouting, Aufzeichnung oder Medienverarbeitung teilen. In einer Radio-over-IP-Umgebung können mehrere Gateways verteilte Funkkanäle, Leitstellen und IP-Netze verbinden, sodass standortübergreifende Kommunikation verfügbar bleibt.
Wie gruppierte Knoten zusammenarbeiten
Teilnahme der Knoten
Ein Knoten ist eine teilnehmende Einheit innerhalb des Systems. Er kann ein physischer Server, eine virtuelle Maschine, ein Gateway, ein Controller, ein Speichergerät, ein Kommunikationsendpunkt oder ein Softwaredienst sein. Jeder Knoten hat eine definierte Rolle und kommuniziert über das Netzwerk mit anderen Knoten.
Manche Knoten können dieselbe Funktion übernehmen, andere haben spezialisierte Aufgaben. In einer Datenbankumgebung kann ein Knoten Schreibvorgänge annehmen, während andere Daten replizieren. In einem Kommunikationssystem kann ein Knoten Signalisierung verarbeiten, während ein anderer Medien, Aufzeichnung oder Gateway-Zugriff verwaltet.
Heartbeat und Zustandsprüfung
Viele Cluster-Systeme verwenden Heartbeat-Signale, um zu prüfen, ob Knoten aktiv sind. Ein Heartbeat ist eine regelmäßige Statusmeldung zwischen Knoten oder an einen Management-Controller. Wenn ein Knoten nicht mehr antwortet, nimmt das System an, dass er möglicherweise ausgefallen ist.
Die Zustandsprüfung kann auch CPU-Auslastung, Speicher, Netzwerkstatus, Anwendungsantwort, Prozesszustand, Speicherplatz, Gateway-Verbindung oder Geräteregistrierung überwachen. Dadurch kann das System entscheiden, ob ein Knoten weiter Datenverkehr bedienen oder vorübergehend entfernt werden soll.
Verteilung der Arbeitslast
Einige Cluster verteilen Arbeit auf mehrere Knoten. Dies kann über Load Balancer, Routing-Regeln, gemeinsame Warteschlangen, verteilte Datenbanken oder Koordination auf Anwendungsebene erfolgen. Ziel ist es, Überlastung eines Knotens zu vermeiden, während andere untätig bleiben.
Lastverteilung kann Leistung und Skalierbarkeit verbessern. Sie erfordert jedoch sauberes Sitzungsmanagement, Datensynchronisierung, ausreichende Netzwerkkapazität und Überwachung. Eine schlecht geplante Methode kann ungleichmäßige Last oder Dienstinstabilität verursachen.
Failover-Verhalten
Failover bedeutet, dass bei Ausfall eines Knotens ein anderer dessen Rolle übernimmt. In einem Active-Standby-Design bleibt der Ersatzknoten möglicherweise inaktiv, bis der aktive Knoten ausfällt. In einem Active-Active-Design bedienen mehrere Knoten bereits Datenverkehr und können zusätzliche Last aufnehmen, wenn ein Knoten offline geht.
Failover muss sorgfältig getestet werden. Ein Backup-Knoten ist nur dann nützlich, wenn er die richtige Konfiguration, aktuelle Daten, Netzwerkzugriff, Lizenzkapazität und den erforderlichen Anwendungszustand besitzt, um den Dienst fortzusetzen.
Ein Cluster-Design bedeutet nicht nur, mehr Geräte hinzuzufügen. Es bedeutet, Knoten so zu koordinieren, dass Ausfälle, Wachstum und Wartung ohne unnötige Dienstunterbrechung behandelt werden können.
Häufige Architekturmodelle
Active-Standby-Design
In einem Active-Standby-Design stellt ein Knoten den Dienst bereit, während ein anderer als Reserve wartet. Fällt der aktive Knoten aus, übernimmt der Standby-Knoten. Dieses Modell ist üblich, wenn Konsistenz und kontrolliertes Failover wichtiger sind als die gleichzeitige Nutzung aller Knoten.
Der Vorteil liegt in der Einfachheit. Der Nachteil ist, dass Backup-Ressourcen im Normalbetrieb untergenutzt bleiben können. Für kritische Systeme ist diese Reservekapazität jedoch oft akzeptabel, weil sie die Kontinuität verbessert.
Active-Active-Design
In einem Active-Active-Design stellen mehrere Knoten gleichzeitig Dienste bereit. Datenverkehr oder Aufgaben werden zwischen ihnen verteilt. Fällt ein Knoten aus, bedienen die verbleibenden Knoten weiter Benutzer, auch wenn die Gesamtkapazität sinken kann.
Dieses Modell verbessert Ressourcennutzung und Skalierbarkeit. Es wird häufig in Cloud-Plattformen, Webanwendungen, Kommunikationssystemen, verteilten Datenbanken und Multi-Node-Serviceplattformen eingesetzt.
Lastverteilte Bereitstellung
Eine lastverteilte Bereitstellung nutzt eine Frontend-Komponente, um Datenverkehr auf mehrere Backend-Knoten zu verteilen. Der Load Balancer kann Regeln wie Round-Robin, geringste Verbindungen, Gesundheitsstatus, Quelladresse, Dienstpriorität oder geografische Nähe verwenden.
Dieses Design ist typisch für Webdienste, SIP-Plattformen, APIs, Anwendungsserver, Mediensysteme und Unternehmensportale. Auch der Load Balancer selbst sollte redundant ausgelegt sein, sonst wird er zum Single Point of Failure.
Verteiltes Edge-Design
Einige Systeme platzieren Knoten an verschiedenen Standorten statt in einem einzigen Rechenzentrum. Das ist üblich bei Niederlassungskommunikation, Industriestandorten, Verkehrsnetzen, Funkintegration, IoT-Plattformen und öffentlicher Sicherheit.
Ein verteiltes Edge-Design reduziert die Abhängigkeit von einem zentralen Standort und kann lokale Reaktionszeiten verbessern. Es erfordert jedoch zuverlässige Synchronisierung, Fernüberwachung, Sicherheitskontrollen und klare Wartungsabläufe.
Warum Organisationen dieses Design nutzen
Höhere Verfügbarkeit
Verfügbarkeit ist einer der Hauptgründe für gruppierte Systeme. Fällt eine Einzelkomponente aus, kann der Dienst stoppen. Sind mehrere koordinierte Knoten vorhanden, kann ein anderer Knoten den Dienst fortsetzen oder die betroffene Last übernehmen.
Das ist wichtig für Kommunikationsplattformen, Notfalldienste, Geschäftsanwendungen, Finanzsysteme, Gesundheitswesen, industrielle Steuerung und kundennahe Dienste, bei denen Ausfallzeiten operative oder kommerzielle Folgen haben.
Skalierbarkeit für Wachstum
Mit steigender Nachfrage benötigen Organisationen möglicherweise mehr Rechenleistung, Anrufkapazität, Datenbankdurchsatz, Speicher, Gateway-Kanäle oder Service-Endpunkte. Ein Cluster-Design ermöglicht Wachstum durch Hinzufügen von Knoten statt durch Austausch des gesamten Systems.
Skalierbarkeit ist besonders wertvoll, wenn sich Verkehr im Laufe der Zeit verändert. Ein System kann klein beginnen und wachsen, wenn Standorte, Nutzer, Kanäle, Dienste oder Kundennachfrage zunehmen.
Wartung mit weniger Unterbrechung
Cluster-Systeme erleichtern Wartung. Administratoren können einen Knoten aus dem Dienst nehmen, aktualisieren, testen und zurückführen, während andere Knoten weiterhin Datenverkehr bedienen.
Planung bleibt dennoch notwendig. Wartung muss Kompatibilität, Synchronisierung, Benutzersitzungen, Failover-Verhalten und Rollback berücksichtigen. Das Design bietet aber deutlich mehr Flexibilität als ein Einzelknoten-System.
Bessere Ressourcennutzung
In Active-Active- oder Load-Balanced-Systemen können mehrere Knoten Arbeit teilen. Dadurch wird die Ressourcennutzung verbessert, weil Kapazität nicht auf eine Maschine oder ein Gerät begrenzt ist.
Mehrere Anwendungsserver können beispielsweise mehr Benutzer bedienen als ein einzelner Server. Mehrere Medien-Gateways können mehr Sprachkanäle unterstützen. Mehrere Speicherknoten können mehr Kapazität und Widerstandsfähigkeit liefern.
Verbesserte Dienstresilienz
Resilienz bedeutet, dass das System unter Last, Teilfehlern, Wartung oder Verkehrsänderungen weiterarbeiten kann. Cluster-Design hilft, indem es Verantwortung verteilt und die Abhängigkeit von einer einzelnen Komponente reduziert.
Für geschäftskritische Umgebungen sollte Resilienz auch Ersatzstrom, Netzwerkredundanz, geografische Trennung, Monitoring, Sicherheits-Härtung und getestete Wiederherstellungsverfahren umfassen.
Wichtige technische Komponenten
Gemeinsame Konfiguration
Knoten benötigen konsistente Konfigurationen, damit sie vorhersehbar arbeiten. Dazu können Netzwerkeinstellungen, Benutzerdaten, Routing-Regeln, Sicherheitszertifikate, Dienstparameter, Lizenzinformationen und Anwendungsrichtlinien gehören.
Wenn Konfigurationen auseinanderlaufen, werden Failover oder Lastverteilung unzuverlässig. Zentrales Konfigurationsmanagement oder automatisierte Bereitstellung kann dieses Risiko verringern.
Datensynchronisierung
Einige Systeme erfordern Datensynchronisierung zwischen Knoten. Dazu gehören Benutzersitzungen, Anrufzustände, Datenbankeinträge, Warteschlangenstatus, Geräteregistrierung, Voicemail-Daten, Zugriffsrechte oder Alarmprotokolle.
Das Synchronisierungsdesign ist kritisch. Wenn Daten nicht aktuell sind, übernimmt ein Backup-Knoten möglicherweise ohne den erwarteten Dienstzustand. Ist Synchronisierung zu schwergewichtig, kann sie Leistungsaufwand erzeugen.
Quorum und Split-Brain-Schutz
In bestimmten Clustern wird Quorum verwendet, um zu bestimmen, welche Knoten Entscheidungen treffen dürfen. Das hilft, Split-Brain-Situationen zu vermeiden, bei denen zwei Systemteile nach einer Netztrennung gleichzeitig glauben, aktiv zu sein.
Split-Brain kann gefährlich sein, weil es zu widersprüchlichen Daten, doppelter Dienststeuerung oder instabilem Failover führen kann. Geeignetes Quorum-Design, Fencing und Netzwerkredundanz reduzieren dieses Risiko.
Monitoring und Alarmierung
Monitoring ist entscheidend, weil Cluster Teilfehler verdecken können. Ein Dienst kann noch online erscheinen, obwohl ein Knoten, Link, Datenträger, Gateway oder Prozess ausgefallen ist.
Administratoren sollten Knotengesundheit, Verkehrsverteilung, Failover-Ereignisse, Synchronisationsstatus, Ressourcennutzung, Fehlerprotokolle und Service-Level-Indikatoren überwachen. Alarme sollten nicht nur melden, dass etwas ausgefallen ist, sondern auch welche Komponente Aufmerksamkeit braucht.
Sicherheitskontrolle
Gruppierte Systeme haben meist mehr interne Kommunikation als Einzelsysteme. Knoten können Status, Konfiguration, Daten, Zugangsdaten oder Steuerungsmeldungen austauschen. Diese Kanäle müssen durch Authentifizierung, Verschlüsselung, Segmentierung und Zugriffskontrolle geschützt werden.
Auch administrativer Zugriff sollte kontrolliert werden. Wenn ein Knoten kompromittiert wird, darf der Angreifer nicht automatisch die gesamte Umgebung kontrollieren.
Kommunikations- und Gateway-Szenarien
In Kommunikationsnetzen erscheint das Cluster-Konzept häufig in PBX-Plattformen, SIP-Servern, Dispatch-Systemen, Gateways, Radio-over-IP-Netzen, Aufzeichnungsplattformen, Contact Centern und Notfallkommunikation. Diese Dienste benötigen Kontinuität, da Kommunikationsausfälle Betrieb, Sicherheitsreaktion oder Kundendienst beeinträchtigen können.
Für Funk- und Dispatch-Integration kann ein Cluster-Gateway-Design mehrere Funkkanäle, IP-Netze und Kontrollzentren verbinden. Eine Gateway-Gruppe kann Kanalerweiterung, Failover, Fernzugriff und zentrale Verwaltung über verschiedene Standorte hinweg bereitstellen.
Beispielsweise kann das BK-ROIP-Cluster-Gateway von Becke Telcom in Projekten eingesetzt werden, in denen Funksysteme mit IP-Dispatch-Plattformen, mehrstandortfähigen Leitstellen oder Unternehmenskommunikationsnetzen verbunden werden müssen. In solchen Szenarien verbindet die Gateway-Schicht Funksprechverkehr, IP-Übertragung und operative Dispatch-Workflows und hält die Lösung skalierbar und einfacher verwaltbar.
Anwendungen in verschiedenen Branchen
Unternehmens-IT-Systeme
Unternehmen nutzen Cluster-Server für Geschäftsanwendungen, Datenbanken, Dateidienste, E-Mail-Systeme, Identitätsplattformen und interne Portale. Diese Systeme müssen bei Hardwarefehlern, Softwareupdates oder Lastspitzen verfügbar bleiben.
In der Unternehmens-IT sind die Hauptziele Betriebszeit, vorhersehbare Leistung, einfachere Wartung und Geschäftskontinuität. Das Design sollte der Bedeutung jeder Anwendung entsprechen.
Cloud und Rechenzentren
Cloud-Plattformen hängen stark von gruppierten Ressourcen ab. Compute-Knoten, Speicherknoten, Netzwerkcontroller und Anwendungsdienste werden über die Infrastruktur verteilt, damit Workloads skalieren und sich von Fehlern erholen können.
In Rechenzentren unterstützt dieses Design Hochverfügbarkeit, Ressourcen-Pooling, Virtualisierung, Container-Orchestrierung und automatisierte Workload-Migration.
Telefonie und Unified Communications
Sprachplattformen können gruppierte Server für Registrierung, Anrufrouting, Mediendienste, Voicemail, Aufzeichnung, Contact-Center-Warteschlangen oder SIP-Trunk-Steuerung verwenden. Dadurch sinkt das Risiko, dass ein Serverausfall die Kommunikation aller Benutzer unterbricht.
Für Unternehmen mit mehreren Standorten verbessern verteilte Kommunikationsknoten auch die lokale Überlebensfähigkeit. Eine Niederlassung kann interne Kommunikation fortsetzen, selbst wenn die Verbindung zum zentralen Standort vorübergehend ausfällt.
Industrie- und Energieanlagen
Industrieanlagen, Versorger, Öl- und Gasstandorte, Minen, Häfen und Kraftwerke können gruppierte Systeme für Monitoring, Dispatch, Alarmbearbeitung, Funkintegration, Zutrittskontrolle und Leitstellenkommunikation nutzen.
In diesen Umgebungen sind Betriebszeit und Resilienz besonders wichtig. Das System sollte gemeinsam mit redundanter Stromversorgung, Netzwerkschutz, Umgebungsbedingungen und Wartungsprozessen geplant werden.
Öffentliche Sicherheit und Notfallreaktion
Einsatzorganisationen können gruppierte Kommunikationsserver, Dispatch-Plattformen, Funk-Gateways, Aufzeichnungssysteme und Benachrichtigungstools nutzen. Ziel ist es, Kommunikation verfügbar zu halten, wenn die Nachfrage steigt oder ein Teil der Infrastruktur ausfällt.
Diese Systeme sollten unter realistischen Bedingungen getestet werden, einschließlich Failover, Ersatzstrom, hohem Anrufvolumen, behördenübergreifender Koordination und Netzwerkstörungen.

Die passende Einrichtung planen
Zuerst das Dienstziel definieren
Bevor ein Cluster-Design gewählt wird, sollten Organisationen das Dienstziel definieren. Es kann um Hochverfügbarkeit, Lastverteilung, geografische Redundanz, Wartungsflexibilität, Kanalerweiterung, Disaster Recovery oder Multi-Site-Integration gehen.
Jedes Ziel führt zu einer anderen Architektur. Ein hauptsächlich für Failover entworfenes System ist nicht unbedingt identisch mit einem System für Performance-Skalierung.
Fehlerpunkte identifizieren
Ein Cluster kann weiterhin ausfallen, wenn andere Komponenten nicht redundant sind. Stromversorgung, Switches, Router, Speicher, Firewalls, Load Balancer, Lizenzen, Datenbanken und Managementplattformen können Single Points of Failure werden.
Die Planung sollte über die Knoten selbst hinausgehen. Der vollständige Dienstpfad muss geprüft werden.
Anwendungskompatibilität prüfen
Nicht jede Anwendung oder jedes Gerät ist für Clustering ausgelegt. Manche Systeme benötigen spezielle Lizenzen, Datenbankunterstützung, Synchronisationslogik, gemeinsamen Speicher oder herstellerspezifische Architektur.
Kompatibilität sollte vor der Bereitstellung bestätigt werden. Ein auf dem Papier gutes Design kann scheitern, wenn die Anwendung Active-Active-Betrieb oder Zustandssynchronisierung nicht verarbeiten kann.
Wiederherstellungsverhalten testen
Failover sollte vor dem Produktivbetrieb getestet werden. Tests sollten Knotenausfall, Netzwerkunterbrechung, Dienstneustart, Datenbankverzögerung, Stromausfall, Wartungsmodus und Rückkehr in den Normalbetrieb abdecken.
Wiederherstellungstests zeigen versteckte Probleme wie langsames Failover, unvollständige Datensynchronisierung, falsches Routing oder Verlust von Benutzersitzungen.
Häufige Herausforderungen
Eine häufige Herausforderung ist Komplexität. Mehr Knoten, mehr Verbindungen und mehr Synchronisationsregeln erzeugen mehr Dinge, die konfiguriert und überwacht werden müssen. Ein schlecht verwalteter Cluster kann schwerer zu beheben sein als ein einfaches Einzelsystem.
Eine weitere Herausforderung ist falsche Sicherheit. Manche Organisationen nehmen an, dass mehr Knoten automatisch Hochverfügbarkeit erzeugen. Tatsächlich muss das Gesamtdesign Redundanz, Monitoring, Failover-Logik, getestete Wiederherstellung und qualifizierte Wartung enthalten.
Auch Kosten spielen eine Rolle. Zusätzliche Knoten, Lizenzen, Speicher, Switches, Gateways, Softwaremodule und Supportleistungen können Projektkosten erhöhen. Die Investition sollte zum Geschäftsrisiko von Ausfallzeiten oder begrenzter Kapazität passen.
Ein Cluster-System sollte an realen Dienstanforderungen ausgerichtet werden, nicht an der Annahme, dass mehr Knoten automatisch höhere Zuverlässigkeit bedeuten.
Wartung und Betrieb
Regelmäßige Wartung sollte Knotengesundheitsprüfungen, Konfigurationsprüfung, Backup-Validierung, Failover-Tests, Log-Analyse, Leistungsmonitoring und Sicherheitsupdates umfassen. Ein nie getesteter Cluster kann genau dann unerwartet ausfallen, wenn er am dringendsten benötigt wird.
Administratoren sollten auch Konfigurationsdrift beachten. Wenn ein Knoten manuell aktualisiert wird und ein anderer nicht, kann das Verhalten inkonsistent werden. Automatisierte Konfigurationswerkzeuge und dokumentiertes Change Management reduzieren dieses Risiko.
Kapazität sollte im Zeitverlauf überprüft werden. Wenn ein Knoten ausfällt, müssen die verbleibenden Knoten genügend Kapazität für kritische Workloads haben. Andernfalls bleibt der Dienst zwar online, aber mit inakzeptabler Leistung.
Wie man eine geeignete Lösung auswählt
Die richtige Lösung hängt von Workload-Typ, Bedeutung des Dienstes, Nutzergröße, Standortverteilung, Wiederherstellungsanforderungen und Budget ab. Eine kleine Büroanwendung benötigt vielleicht nur einfache Sicherung und Wiederherstellung, während eine Carrier-Grade-Kommunikationsplattform Active-Active-Redundanz über mehrere Standorte verlangt.
Für Kommunikationsprojekte sollten Anrufkapazität, Kanalkapazität, SIP-Kompatibilität, Medienverarbeitung, Funkintegration, Gateway-Redundanz, zentrale Verwaltung, Protokollierung und Failover-Verhalten berücksichtigt werden. Wenn die Lösung Funk, IP-Dispatch und Unternehmenskommunikation verbindet, werden Gateway-Skalierbarkeit und standortbezogene Resilienz besonders wichtig.
Organisationen sollten auch die langfristige Wartung berücksichtigen. Eine Lösung muss verständlich, dokumentiert, überwacht und vom Team für den täglichen Betrieb supportbar sein.
FAQ
Kann ein kleines Unternehmen Cluster-Systeme nutzen?
Ja. Ein kleines Unternehmen braucht vielleicht keine komplexe Multi-Node-Plattform, kann aber einfache Hochverfügbarkeitsdesigns wie redundante Firewalls, Backup-Server, replizierten Speicher oder Cloud-verwaltete Dienste nutzen.
Erfordert Clustering immer identische Hardware?
Nicht immer. Einige Systeme verlangen identische Hardware oder Softwareversionen, andere erlauben gemischte Knoten. Unterschiedliche Kapazitäten oder Versionen können jedoch Leistung, Failover und Supportfähigkeit beeinflussen.
Was ist der Unterschied zwischen Redundanz und Clustering?
Redundanz bedeutet, Backup-Komponenten zu haben. Clustering ist ein koordiniertes Design, bei dem mehrere Komponenten unter gemeinsamer Logik zusammenarbeiten. Ein Cluster enthält meist Redundanz, aber Redundanz allein bedeutet nicht immer, dass das System geclustert ist.
Warum dauert Failover manchmal länger als erwartet?
Failover kann durch Health-Check-Timer, Datensynchronisierung, Dienststartzeit, Routing-Konvergenz, DNS-Caching, Sitzungswiederherstellung oder manuelle Freigaben verzögert werden. Diese Faktoren sollten vor dem Produktivbetrieb getestet werden.
Was sollte nach der Bereitstellung dokumentiert werden?
Die Dokumentation sollte Knotenrollen, IP-Adressen, Dienstabhängigkeiten, Failover-Regeln, Administrationskonten, Monitoring-Schwellen, Backup-Verfahren, Wartungsfenster, Wiederherstellungsschritte und Kontaktverantwortlichkeiten enthalten.