Ein Datenbankproblem bleibt selten innerhalb der Datenbank. Wenn die einzige Datenkopie langsam, unerreichbar, beschädigt oder überlastet ist, spürt das darüberliegende Geschäftssystem sofort die Folgen: Bestellungen können nicht erfasst werden, Berichte werden nicht erzeugt, Geräte laden keine Datensätze hoch, Benutzer können sich nicht anmelden und die Wiederherstellung wird zu einem Wettlauf gegen die Zeit.
Datenbankreplikation gibt es aus genau diesem Grund. Sie erstellt eine oder mehrere zusätzliche Datenkopien und hält sie mit der Quelldatenbank synchron, damit Systeme schneller lesen, schneller wiederherstellen, Arbeitslasten verteilen und weiterarbeiten können, wenn ein einzelner Datenbankknoten nicht mehr ausreicht.
Die Grundidee der Datenbankreplikation
Datenbankreplikation ist der Prozess, Daten von einem Datenbankknoten auf einen anderen zu kopieren und diese Kopien bei Änderungen aktuell zu halten. Die Quelldatenbank kann je nach Technologie Primary, Master, Publisher oder Leader heißen. Die empfangende Datenbank kann Replica, Standby, Subscriber, Secondary oder Follower heißen. Die Namen unterscheiden sich, der Zweck bleibt ähnlich: Änderungen von einem Ort werden kontrolliert an einen anderen Ort geliefert.
Kopiert werden können komplette Datenbanken, ausgewählte Tabellen, Partitionen, Schemas, Transaktionsprotokolle oder bestimmte Datenströme. In manchen Systemen dient die Replik nur der Sicherung oder dem Failover. In anderen übernehmen Repliken Leseverkehr, Analysen, Reporting, regionalen Zugriff oder nachgelagerte Datenverarbeitung. Replikation ist daher kein einzelnes starres Feature, sondern eine Entwurfsmethode für unterschiedliche Betriebsziele.
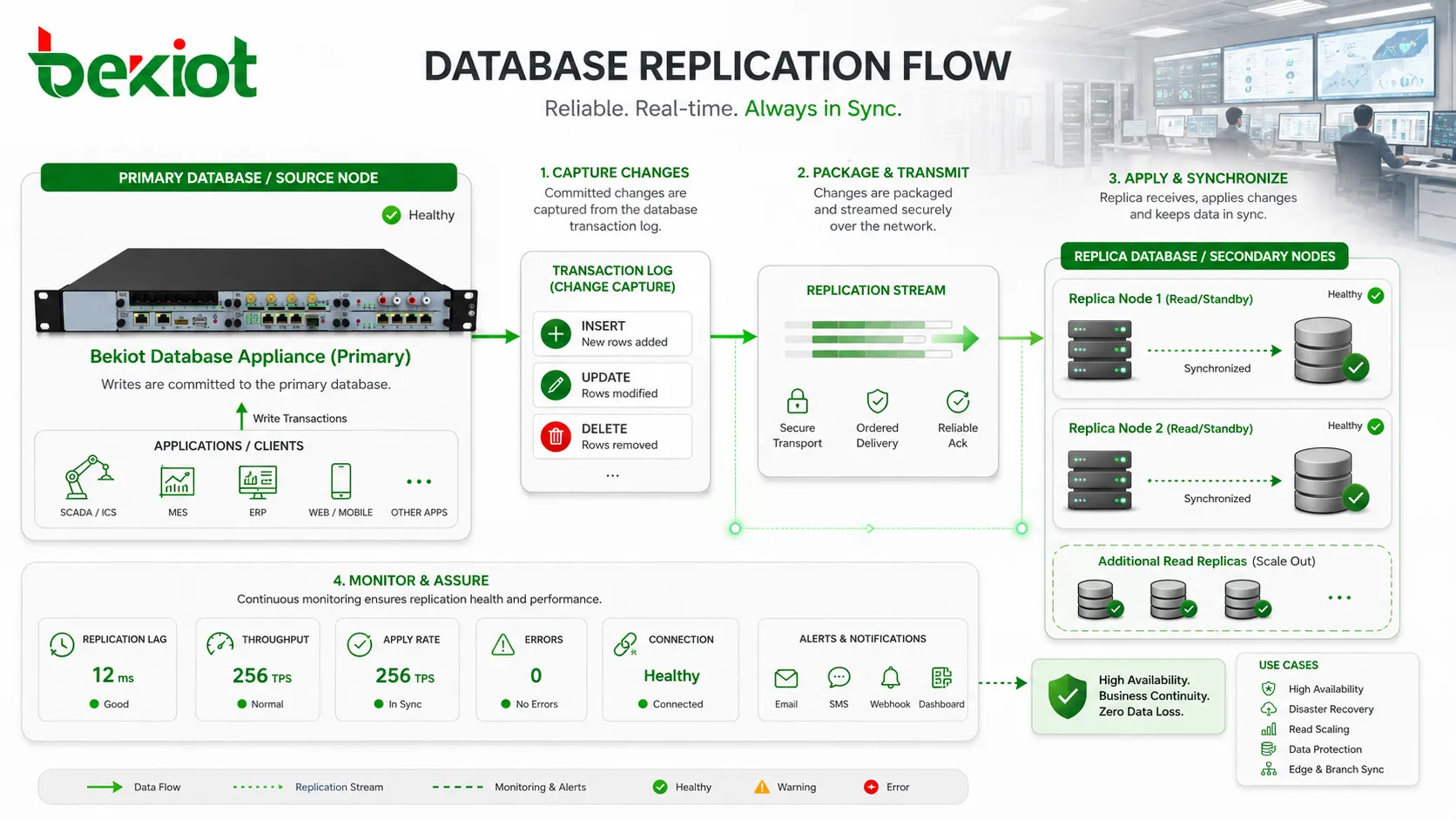
Im Kern steht die Änderungsverfolgung. Wenn Daten eingefügt, aktualisiert oder gelöscht werden, muss die Datenbank diese Änderung erkennen, zuverlässig verpacken, an einen anderen Knoten senden und in der richtigen Reihenfolge anwenden. Wird dieser Prozess nachlässig behandelt, kann die Replik inkonsistent werden. Ist er zu langsam, entsteht Replikationsverzug. Wird er nicht überwacht, bemerken Teams Probleme oft erst im Wiederherstellungsfall.
Ein gutes Replikationsdesign beantwortet praktische Fragen: Welche Daten werden kopiert, wie schnell müssen sie ankommen, wer darf schreiben, wie werden Konflikte behandelt, was passiert bei Netzwerkausfall und wie verhalten sich Anwendungen, wenn ein Knoten nicht verfügbar ist. Diese Antworten entscheiden, ob Replikation Resilienz schafft oder Verwirrung verbirgt.
Was tatsächlich zwischen Datenbankknoten übertragen wird
Replikation ist nicht immer eine einfache Dateikopie. In den meisten Produktionssystemen sendet die Datenbank nicht bei jeder Änderung den gesamten Datenbestand erneut. Sie erfasst stattdessen die Änderung und überträgt nur das, was nötig ist, um sie auf der Replik nachzubilden. Das spart Bandbreite und hält die Replik nahe an der Quelle, ohne alles neu aufzubauen.
Eine verbreitete Methode ist logbasierte Replikation. Die Primärdatenbank schreibt Änderungen in Transaktionslogs, Binärlogs, Write-Ahead-Logs oder Redo-Logs. Die Replik liest diese Logs und wendet dieselben Operationen nacheinander an. Diese Methode wird häufig genutzt, weil das Log bereits die verbindliche Reihenfolge der Datenbankänderungen enthält.
Eine andere Methode ist statementbasierte Replikation, bei der SQL-Anweisungen an die Replik gesendet werden. Das kann in manchen Systemen einfacher sein, kann aber Unterschiede erzeugen, wenn eine Anweisung von nichtdeterministischen Funktionen, Zeitwerten, Zufallswerten oder umgebungsspezifischem Verhalten abhängt. Zeilenbasierte Replikation vermeidet viele dieser Probleme, weil sie die tatsächlichen Zeilenänderungen überträgt.
Einige Systeme nutzen Snapshot-Replikation. Dabei wird zu einem Zeitpunkt eine vollständige oder teilweise Kopie der Daten erzeugt und an einen anderen Ort geliefert. Das eignet sich für die Erstsynchronisierung, Reporting-Datenbanken oder periodische Datenverteilung. Für nahezu Echtzeit-Aktualisierung reichen Snapshots allein jedoch meist nicht aus.
Moderne Architekturen können auch Change Data Capture einsetzen. CDC extrahiert Datenbankänderungen und sendet sie an Analyseplattformen, Suchindizes, Message Queues oder Data Lakes. Dann geht es bei Replikation nicht mehr nur um eine weitere Datenbankkopie, sondern um einen Teil der Datenbewegungspipeline der Organisation.
Primary-Replica-Replikation im täglichen Betrieb
Das bekannteste Muster ist Primary-Replica-Replikation. Ein Datenbankknoten nimmt Schreibvorgänge an, während eine oder mehrere Repliken Kopien der Änderungen erhalten. Anwendungen senden Inserts, Updates und Deletes an den Primary. Reine Leseabfragen können an Repliken gehen, wenn Anwendung und Architektur dies unterstützen.
Dieses Muster ist leicht verständlich und weit verbreitet, weil die Schreibverantwortung klar bleibt. Der Primary ist die Autorität für Änderungen, Repliken folgen seinem Zustand. Fällt eine Replik aus, kann der Primary weiterarbeiten. Fällt der Primary aus, kann je nach Failover-Design eine Replik zum neuen Primary befördert werden.
Der Vorteil liegt in der praktischen Lasttrennung. Transaktionale Schreibvorgänge, Benutzeroperationen und Geschäftsänderungen bleiben auf dem Primary, während Berichte, Dashboards, Suchabfragen oder leselastige Dienste Repliken nutzen können. Dadurch sinkt der Druck auf die Hauptdatenbank und die Antwortzeit kann besser werden.
Anwendungen müssen jedoch wissen, dass Repliken nicht immer vollständig aktuell sind, besonders bei asynchroner Replikation. Schreibt ein Benutzer auf den Primary und liest sofort von einer verzögerten Replik, sieht er die letzte Änderung möglicherweise nicht. Das ist nicht zwingend ein Fehler, sondern ein Designkompromiss, der sauber behandelt werden muss.
Multi-Primary- und verteilte Replikationsmuster
Manche Umgebungen benötigen mehr als einen schreibbaren Datenbankknoten. Bei Multi-Primary-Replikation können mehrere Knoten Schreibvorgänge annehmen und die Änderungen untereinander replizieren. Das unterstützt verteilte Standorte, regionale Abläufe, lokale Schreibzugriffe oder Hochverfügbarkeit über Rechenzentren hinweg. Es klingt attraktiv, ist aber deutlich komplexer als Primary-Replica-Replikation.
Die größte Herausforderung sind Konflikte. Wenn zwei Knoten denselben Datensatz gleichzeitig ändern, muss das System entscheiden, welche Änderung gewinnt oder wie Änderungen zusammengeführt werden. Regeln können auf Zeitstempeln, Versionsnummern, Anwendungslogik, Knotenvorrang oder manueller Entscheidung beruhen. Schlechte Konfliktbehandlung schädigt die Datenqualität.
Verteilte Replikation wird auch in Edge-Systemen, Filialen, Industrieanlagen, mobilen Anwendungen oder entfernten Betriebsorten eingesetzt, wo lokale Daten trotz instabiler Zentralverbindung verfügbar bleiben müssen. Ein lokaler Knoten kann Daten vorübergehend speichern und ändern und später mit dem Zentralsystem synchronisieren. Das verbessert lokale Kontinuität, verlangt aber klare Synchronisationsregeln.
Multi-Primary-Designs sollten nur gewählt werden, wenn der Geschäftsnutzen die Komplexität rechtfertigt. Für viele Anwendungen ist ein schreibender Primary mit Leserepliken einfacher zu betreiben. Wenn lokale Schreibvorgänge an mehreren Orten wirklich nötig sind, müssen Konfliktmanagement, Datenverantwortung und Monitoring vor der Bereitstellung feststehen.
Synchrone und asynchrone Replikation
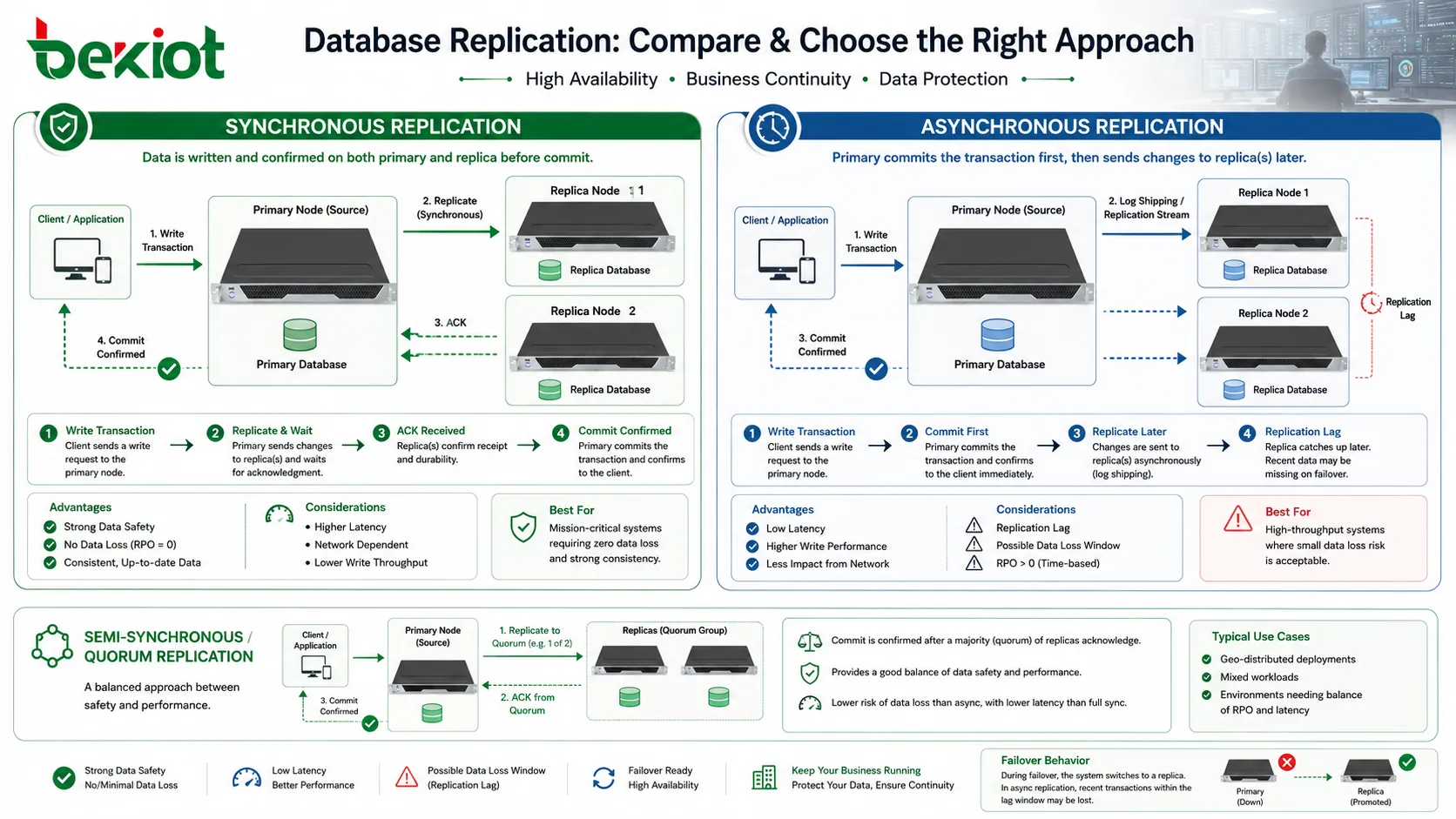
Der Zeitpunkt der Replikation ist eine der wichtigsten Designentscheidungen. Bei synchroner Replikation gilt eine Transaktion erst dann als vollständig bestätigt, wenn ein anderer Datenbankknoten die Änderung bestätigt hat. Das verbessert die Datensicherheit, weil die Replik die Änderung besitzt, bevor die Anwendung Erfolg meldet. Fällt der Primary kurz danach aus, existieren bestätigte Daten wahrscheinlicher auf einem anderen Knoten.
Der Preis ist Latenz. Ist die Replik weit entfernt oder das Netz langsam, muss der Primary länger warten, bevor die Transaktion abgeschlossen ist. Das kann die Antwortzeit der Anwendung beeinflussen. Synchrone Replikation wird daher dort eingesetzt, wo Datenverlust kaum toleriert wird und der Netzpfad zwischen Knoten zuverlässig genug ist.
Bei asynchroner Replikation bestätigt der Primary die Transaktion zuerst und sendet die Änderung danach an Repliken. Das verbessert die Schreibleistung, weil die Anwendung nicht auf entfernte Bestätigung wartet. Dieses Modell ist üblich für Reporting, Leseskalierung oder Disaster Recovery über größere Entfernungen.
Der Kompromiss ist Replikationsverzug. Fällt der Primary aus, bevor Änderungen die Replik erreichen, können jüngste Transaktionen verloren gehen oder aus Logs wiederhergestellt werden müssen. Asynchrone Replikation muss deshalb zu klaren Wiederherstellungszielen passen. Das Team muss wissen, wie viel Datenverlust akzeptabel ist und wie schnell eine Replik normalerweise aufholen soll.
Manche Systeme nutzen semisynchrone oder quorum-basierte Verfahren, um Leistung und Sicherheit auszubalancieren. Sie bestätigen eine Transaktion, nachdem eine oder mehrere Repliken geantwortet haben, warten aber nicht unbedingt auf alle. Die beste Wahl hängt von Geschäftsrisiko, Netzqualität, Transaktionsvolumen und Wiederherstellungsanforderungen ab.
Vorteile für Verfügbarkeit und Failover
Der direkteste Nutzen der Replikation ist höhere Verfügbarkeit. Wenn die Primärdatenbank ausfällt, kann eine Replik befördert werden und den Dienst fortsetzen. Ohne Replikation hängt die Wiederherstellung oft von Backups ab, was länger dauert und mehr jüngste Daten verlieren kann. Replikation liefert dem Betriebsteam eine lebende oder fast lebende Kopie für schnellere Wiederherstellung.
Failover kann manuell oder automatisch erfolgen. Manuelles Failover gibt Administratoren mehr Kontrolle, was bei komplexen Umgebungen oder Split-Brain-Risiko hilfreich ist. Automatisches Failover kann Ausfallzeiten verkürzen, muss aber verhindern, dass zwei Knoten gleichzeitig Primary sein wollen. Hochverfügbarkeitslösungen nutzen dafür oft Monitoring, Health Checks, Quorum-Regeln oder Cluster-Management.
Verfügbarkeit hängt auch vom Verhalten der Anwendung ab. Eine Replik zu befördern reicht nicht, wenn Anwendungen sich nicht neu verbinden, DNS langsam aktualisiert wird, Verbindungspools die alte Adresse halten oder Benutzer Einstellungen manuell ändern müssen. Replikation muss mit Anwendungsrouting, Load Balancern, Connection Strings, Service Discovery und Betriebsabläufen geplant werden.
Eine Replik kann auch Wartung unterstützen. Bei geplanten Upgrades, Patches, Hardwaretausch oder Speichermigration können Arbeitslasten manchmal auf einen anderen Knoten verlagert werden. Das reduziert geplante Ausfallzeiten und gibt Administratoren mehr Flexibilität. Starke Designs unterstützen sowohl Notfallwiederherstellung als auch Routinewartung.
Leseskalierung ohne Änderung des Hauptdatenmodells
Viele Datenbanksysteme überlasten nicht wegen zu vieler Schreibvorgänge, sondern weil Leseabfragen wachsen. Dashboards, Berichte, Suchseiten, Kundenportale, Monitoring-Tools und API-Aufrufe können dieselbe Datenbank lesen. Wenn jede Leseabfrage den Primary trifft, werden normale Transaktionen langsamer. Replikation verteilt Leseverkehr auf Repliken.
Leserepliken werden häufig für Reporting und Analysen eingesetzt. Langlaufende Abfragen können auf Repliken laufen, ohne kritische transaktionale Arbeit auf dem Primary zu blockieren oder zu verlangsamen. Das ist nützlich, wenn Fachbereiche häufig Berichte brauchen, die Produktionsdatenbank aber reaktionsfähig bleiben muss.
Auch Read/Write-Splitting in der Anwendung verbessert Skalierbarkeit. Die Anwendung sendet Schreibvorgänge an den Primary und ausgewählte Leseabfragen an Repliken. Das erfordert Sorgfalt, weil Repliken verzögert sein können. Daten, die sofort konsistent sein müssen, müssen eventuell weiterhin vom Primary gelesen werden; Daten mit leichter Verzögerung eignen sich für Repliken.
So lässt sich Lesekapazität erhöhen, ohne das gesamte Datenmodell neu zu entwerfen. Statt sofort auf eine neue Architektur zu wechseln, kann das Team Repliken hinzufügen, Abfragerouting optimieren und Reporting-Lasten trennen. Das ist oft ein praktischer Zwischenschritt bei der Datenbankskalierung.
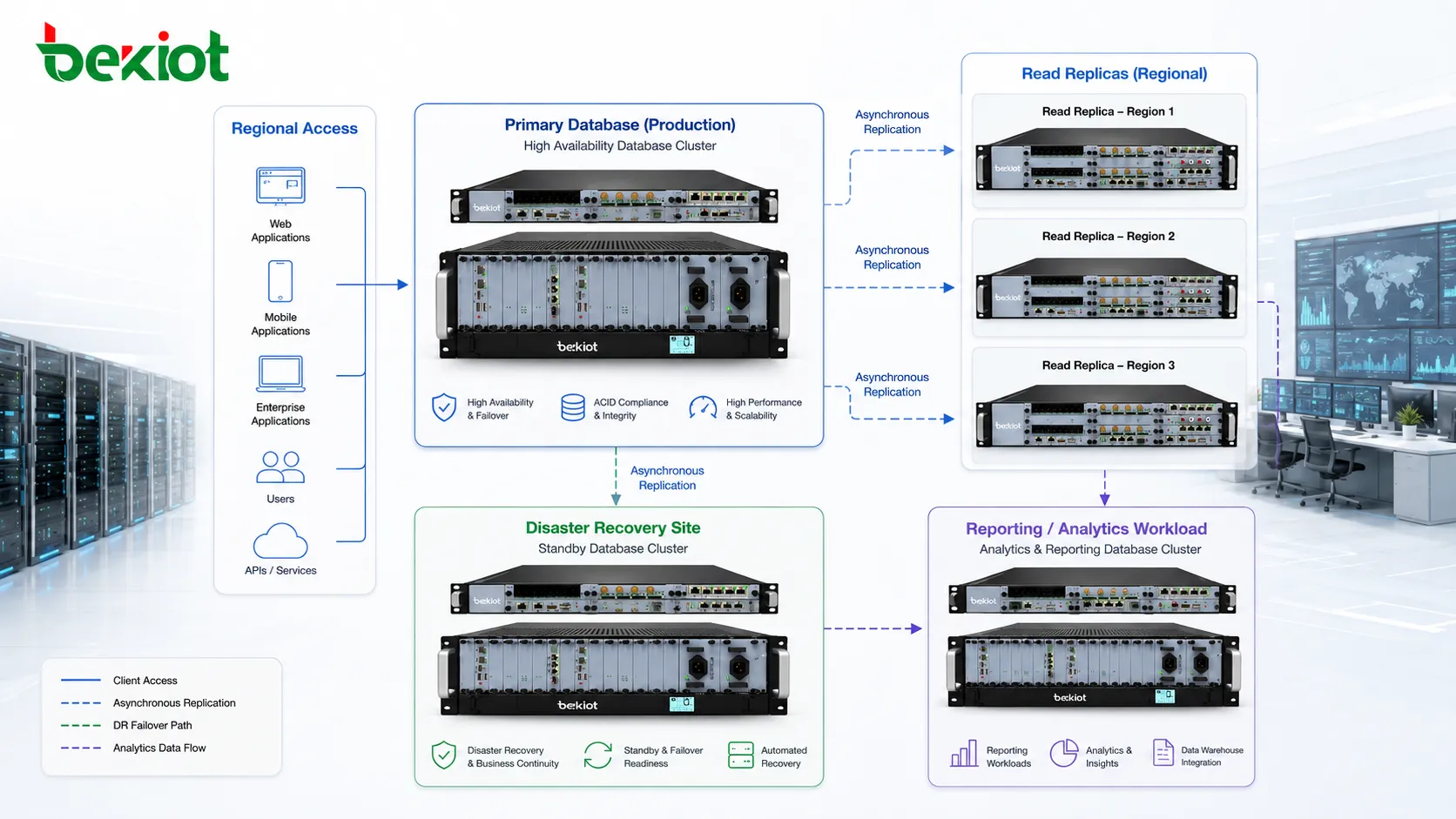
Disaster Recovery und geografische Resilienz
Replikation wird oft für Disaster Recovery genutzt. Eine Replik in einem anderen Rechenzentrum, einer Cloud-Region oder einem anderen Standort kann gegen lokale Ausfälle wie Feuer, Stromausfall, Netzstörung, Speicherschaden oder Standortkatastrophe schützen. Wird der Primärstandort unerreichbar, bietet die entfernte Replik einen Wiederherstellungspfad.
Geografische Replikation braucht sorgfältige Planung, weil Entfernung die Latenz erhöht. Synchrone Replikation über weite Distanzen kann für manche Anwendungen zu langsam sein. Asynchrone Replikation ist bei entfernter Notfallwiederherstellung häufiger, bringt aber möglichen Datenverlust mit sich, wenn der Primärstandort vor vollständiger Kopie ausfällt.
Die Wiederherstellungsplanung sollte Recovery Time Objective und Recovery Point Objective definieren. RTO beschreibt, wie schnell der Dienst zurückkehren soll. RPO beschreibt, wie viel Datenverlust akzeptabel ist. Ein strenges RPO kann mehr synchrone Absicherung oder sehr geringen Verzug erfordern. Ein flexibleres RPO kann asynchrone Replikation mit regelmäßigen Prüfungen nutzen.
Disaster Recovery muss getestet werden. Eine Replik, die nie befördert, nie auf Anwendungskompatibilität geprüft oder nie unter realistischen Bedingungen wiederhergestellt wurde, ist im Ernstfall möglicherweise unzuverlässig. Replikation liefert die technische Grundlage, Übungen beweisen den Prozess.
Datenlokalität und regionale Leistung
Replikation kann Daten näher zu Benutzern, Niederlassungen oder regionalen Anwendungen bringen. Wenn Benutzer an verschiedenen Orten von einer nahen Replik lesen, kann sich die Antwortzeit verbessern. Das ist nützlich für globale Anwendungen, Multi-Region-Dienste, Handelsketten, Logistiknetze, Finanzplattformen und verteilte Unternehmenssysteme.
Regionale Repliken verringern auch die Last auf zentralen Netzverbindungen. Statt jede Abfrage über eine lange Strecke zu senden, können lokale Benutzer oder Dienste von einer nahen Kopie lesen. Das ist besonders wertvoll, wenn viel Leseverkehr entsteht und Anforderungen an die Datenfrische beherrschbar sind.
Datenlokalität unterstützt zudem lokales Reporting. Eine regionale Niederlassung kann eigene Transaktionen, Bestände, Servicedaten oder Betriebsdaten analysieren, ohne die zentrale Produktionsdatenbank ständig zu belasten. Eine lokale Replik bietet diesen Zugriff, während das Zentralsystem auf Kerntransaktionen konzentriert bleibt.
Regionale Replikation muss jedoch Governance-Regeln beachten. Manche Daten unterliegen Datenschutzrecht, internen Richtlinien, Kundenverträgen oder Branchenvorgaben. Das Kopieren in eine andere Region oder ein anderes Land kann Freigabe, Verschlüsselung, Zugriffskontrolle oder Datenminimierung verlangen. Replikation soll Leistung verbessern, ohne Governance zu schwächen.
Backup ist nicht dasselbe wie Replikation
Replikation und Backup werden oft zusammen genannt, lösen aber unterschiedliche Probleme. Replikation hält eine weitere Datenbankkopie aktuell, meist für Verfügbarkeit, Leistung oder Verteilung. Backup erstellt wiederherstellbare historische Kopien nach Löschung, Korruption, Ransomware, versehentlichen Änderungen oder langfristigem Datenverlust.
Eine Replik kann einen Fehler treu kopieren. Löscht ein Benutzer wichtige Datensätze auf dem Primary, kann die Replikation sie schnell auch auf der Replik löschen. Schreibt eine Anwendung beschädigte Daten, erhält die Replik denselben Zustand. Dann schützt Replikation nur, wenn Point-in-Time-Recovery, verzögerte Replikation oder Backups vorhanden sind.
Backups dauern länger bei der Wiederherstellung, sind aber besser für historische Rückkehr. Sie erlauben eine Wiederherstellung zu einem früheren Zeitpunkt. Replikation ist schneller für Servicekontinuität, bietet aber nicht automatisch historischen Rollback. Eine starke Datenbankstrategie enthält normalerweise beides.
Dieser Unterschied muss in den Betriebsplänen klar sein. Geht es um schnelles Failover, hilft Replikation. Geht es um Daten der letzten Woche, ist Backup nötig. Sollen beide Ziele erreicht werden, müssen beide Prozesse regelmäßig entworfen und getestet werden.
Überwachung der Replikationsgesundheit
Replikation muss kontinuierlich überwacht werden. Eine Replik, die Stunden hinterherhinkt, kann online erscheinen, aber für Failover nutzlos oder für Reporting falsch sein. Typische Messpunkte sind Replikationsverzug, Replikstatus, Log-Shipping-Fortschritt, Apply-Rate, Fehlermeldungen, Verbindung, Plattennutzung, Transaktionsverzug und fehlgeschlagene Synchronisationen.
Replikationsverzug ist besonders wichtig. Er misst die Zeit zwischen einer Änderung auf dem Primary und ihrer Verfügbarkeit auf der Replik. Geringer Verzug kann für Reporting akzeptabel sein. Großer Verzug kann Anwendungsannahmen brechen oder beim Failover Datenverlustrisiken erhöhen. Akzeptable Schwellen müssen je nach Nutzung definiert werden.
Auch Speicher und Kapazität sind zu überwachen. Replikation kann Logs, temporäre Dateien, Relay-Logs, Archivlogs oder Staging-Daten erzeugen. Läuft der Speicher voll, kann Replikation stoppen. Ist die Replik zu schwach dimensioniert, wendet sie Änderungen bei Spitzenlast nicht schnell genug an. Eine Replik muss für ihre Arbeitslast ausgelegt sein.
Betriebsalarme sollten aussagekräftig sein. Sie sollten nicht nur melden, dass Replikation fehlgeschlagen ist, sondern helfen zu erkennen, ob Netzwerk, Authentifizierung, Logposition, Plattenplatz, Schema, Berechtigungen oder Konfliktschreibvorgänge die Ursache sind. Je schneller die Ursache bekannt ist, desto schneller wird der Datenpfad wiederhergestellt.
Sicherheit und Zugriffskontrolle
Replikation erhöht die Anzahl der Orte, an denen sensible Daten vorhanden sind. Jede Replik muss so ernst geschützt werden wie die Primärdatenbank. Ist eine Replik schwächer geschützt, kann sie der einfachste Weg zu Datenabfluss werden. Sicherheitsplanung umfasst daher Verschlüsselung, Zugriffskontrolle, Audit-Logging, Netzbeschränkung und Credential-Management für jeden Knoten.
Replikationsverkehr sollte geschützt werden, besonders wenn er Rechenzentren, Cloud-Regionen, öffentliche Netze oder Drittanbieterleitungen durchquert. Verschlüsselung während der Übertragung verhindert Abhören. Authentifizierung zwischen Knoten verhindert unautorisierte Teilnahme. Netzsegmentierung reduziert die Exponierung gegenüber fremden Systemen.
Berechtigungen für Repliken müssen separat geprüft werden. Eine Reporting-Replik kann für Analysten lesbar sein, aber nicht jede Tabelle sollte für jeden sichtbar sein. Sensible Felder können Maskierung, Filterung oder eigene Zugriffsregeln erfordern. In manchen Fällen sollte eine Replik nur die Daten enthalten, die für ihren Zweck nötig sind.
Auch Administratorzugriff braucht Kontrolle. Benutzer, die Replikation stoppen, eine Replik befördern, Filter ändern oder Credentials anpassen können, haben erhebliche Macht. Diese Aktionen müssen protokolliert und autorisiertem Personal vorbehalten bleiben. Replikation gehört zur Vertrauensgrenze der Datenbank, nicht nur zu einer Hintergrundfunktion.
Häufige Fehler bei der Bereitstellung
Ein häufiger Fehler ist Replikation ohne klares Ziel. Geht es um Verfügbarkeit, braucht das Design Failover-Verfahren und Anwendungswiederverbindung. Geht es um Reporting, müssen Abfragelast und Datenfrische behandelt werden. Geht es um Disaster Recovery, gehören entfernter Standort, RTO, RPO und Übungen dazu. Ein unklarer Zweck erzeugt eine unklare Architektur.
Ein weiterer Fehler ist die Annahme, die Replik sei immer aktuell. Asynchrone Repliken können verzögert sein. Viele Schreibvorgänge, instabiles Netz, langsame Platten, Schemaänderungen oder lange Transaktionen können Replikation verzögern. Anwendungen, die von Repliken lesen, müssen diesen Verzug berücksichtigen.
Manche Teams testen die Beförderung nie. Sie erstellen Repliken, üben aber den Wechsel nicht. Im Notfall entdecken sie Berechtigungsprobleme, Anwendungsverbindungsfehler, fehlende Jobs, unvollständige Konfiguration oder inkonsistente Daten. Failover sollte vor dem Ernstfall getestet werden.
Replikationsfilter können ebenfalls verwirren. Werden nur bestimmte Tabellen oder Datenbanken repliziert, müssen Teams genau wissen, was enthalten und ausgeschlossen ist. Ein Reporting-Team kann alle Daten erwarten, obwohl nur ein Teil des Schemas kopiert wird. Klare Dokumentation verhindert falsche Annahmen.
Schließlich unterschätzen viele Bereitstellungen die Wartung. Replikation muss Upgrades, Schemaänderungen, Zertifikatserneuerungen, Passwortrotation, Speicherwachstum, Netzänderungen und Versionsunterschiede überstehen. Sie ist kein Set-and-forget-Feature. Sie braucht Verantwortung.
Wann Replikation den größten Wert bringt
Replikation bringt den größten Wert, wenn eine Organisation einen klaren Bedarf an Verfügbarkeit, Leseskalierung, Disaster Recovery, Datenverteilung oder Lasttrennung hat. Sie ist weniger nützlich, wenn die Datenbank klein ist, Ausfalltoleranz hoch, Leseverkehr gering und Backup-Wiederherstellung ausreichend ist. Wie jede Architekturentscheidung muss sie zum Problem passen.
Für geschäftskritische Systeme kann sie Ausfallzeiten reduzieren und Wiederherstellungsoptionen verbessern. Für wachsende Anwendungen kann sie Reporting und Leseabfragen vom Primary weg verlagern. Für verteilte Organisationen unterstützt sie regionalen Zugriff. Für Datenteams liefert sie operative Daten an Analysesysteme, ohne die Produktion zu stören.
Die stärksten Designs sind meist schlicht und klar. Sie definieren, welcher Knoten schreibt, welche Knoten lesen, wie Verzug überwacht wird, wie Failover funktioniert, wie Backups gepflegt werden und wer für die Replikationsbeziehung verantwortlich ist. Komplexität sollte nur bei starkem Geschäftsnutzen ergänzt werden.
Replikation ist keine magische Sicherheitskopie. Sie ist eine disziplinierte Methode, Daten an mehr als einem Ort verfügbar zu halten. Ihre Vorteile entstehen, wenn technisches Design, Anwendungsverhalten, Monitoring, Sicherheit und Wiederherstellung gemeinsam geplant werden.
FAQ
Wird Datenbankreplikation hauptsächlich für Backups genutzt?
Nein. Replikation kann Wiederherstellung unterstützen, ersetzt aber keine Backups. Eine Replik kann versehentliche Löschung oder beschädigte Daten vom Primary kopieren. Backups bleiben für historische Wiederherstellung und Point-in-Time-Restore notwendig.
Was ist Replikationsverzug?
Replikationsverzug ist die Zeit zwischen der Bestätigung einer Änderung auf der Primärdatenbank und dem Auftauchen derselben Änderung auf der Replik. Er ist bei asynchroner Replikation üblich und muss überwacht werden, wenn Repliken für Lesen oder Failover genutzt werden.
Können Anwendungen auf Repliken schreiben?
In Primary-Replica-Designs sind Repliken normalerweise schreibgeschützt. Multi-Primary-Systeme erlauben Schreibvorgänge auf mehreren Knoten, benötigen aber Konfliktbehandlung und stärkere Betriebskontrolle.
Verbessert Replikation die Datenbankleistung?
Sie kann Leistung verbessern, indem Leseverkehr, Reporting und Analysen vom Primary weg verlagert werden. Sie beschleunigt nicht automatisch jede Last. Schreiblastige Systeme brauchen oft zusätzlich Indexierung, Abfrageoptimierung, Partitionierung, bessere Hardware oder Architekturänderungen.
Was sollte vor dem Vertrauen in Replikation getestet werden?
Zu testen sind Erstsynchronisierung, Verzug unter Last, Failover, Beförderung der Replik, Wiederverbindung der Anwendung, Backup-Wiederherstellung, Monitoring-Alarme, Sicherheitsberechtigungen und Verhalten bei Netzunterbrechung.