

Hochverfügbarkeit ist ein Konstruktionsansatz, der ein System, einen Dienst, eine Anwendung oder ein Netzwerk selbst dann zugänglich hält, wenn einzelne Komponenten ausfallen. Statt sich auf einen einzigen Server, eine Datenbank, einen Netzwerkpfad, eine Stromquelle oder einen Softwareprozess zu stützen, setzt ein hochverfügbares System auf Redundanz, Überwachung, Failover und Wiederherstellungsplanung, um Ausfallzeiten zu verringern und die Dienstkontinuität zu wahren.
Für Unternehmen und Organisationen, deren Arbeit von digitalen Abläufen abhängt, ist Hochverfügbarkeit weit mehr als ein reines IT-Konzept. Sie prägt Kundenerlebnis, Produktionseffizienz, Notfallreaktion, Kommunikationszuverlässigkeit, Datenzugriff, Sicherheitsprozesse und Service-Level-Verpflichtungen. Eine kurze Unterbrechung mag bei einem nachrangigen internen Tool noch hinnehmbar sein – für ein Krankenhaussystem, eine Leitstellenplattform, ein Zahlungsgateway, ein industrielles Steuerungsnetz, einen öffentlichen Kommunikationsdienst oder eine von tausenden Nutzern verwendete Cloud-Anwendung ist sie hingegen nicht akzeptabel.
Bedeutung in der praktischen Systemarchitektur
Hochverfügbarkeit – häufig mit HA abgekürzt – beschreibt die Fähigkeit eines Systems, über einen sehr hohen Zeitanteil nutzbar zu bleiben. Meist wird sie über Betriebszeitziele wie 99,9 %, 99,99 % oder 99,999 % diskutiert. Doch Verfügbarkeit erschöpft sich nicht in der Frage, ob ein Server eingeschaltet ist. Ein System ist erst dann wirklich verfügbar, wenn Anwender die benötigten Aktionen auch tatsächlich ausführen können – etwa ein Telefonat führen, eine Transaktion abschließen, eine App öffnen, einen Alarm empfangen, Datensätze synchronisieren oder auf Echtzeitinformationen zugreifen.
Ein verlässlicher Dienst hängt von der gesamten Dienstkette ab. Sie kann Rechenressourcen, Speicher, Datenbank-Engines, Netzwerk-Switches, Firewalls, DNS, Identitätsdienste, Sicherheitszertifikate, Anwendungsprozesse, Überwachungswerkzeuge, Backup-Leitungen, Strominfrastruktur und Betriebsprozesse umfassen. Fehlt für eine kritische Abhängigkeit der Ausweichpfad, bleibt der gesamte Dienst angreifbar.
Hochverfügbarkeit unterscheidet sich zudem von gewöhnlichen Backups. Ein Backup hilft, Daten nach einem Ausfall wiederherzustellen, hält den Dienst während des Ausfalls aber möglicherweise nicht am Laufen. HA zielt auf Kontinuität: Sie erlaubt es einem anderen Knoten, Pfad, Dienstexemplar oder Standort, zu übernehmen, bevor Nutzer eine längere Unterbrechung erleben.
Warum Unternehmen auf Kontinuität setzen
Der Wert von Hochverfügbarkeit wird offensichtlich, wenn Ausfallzeiten reale Konsequenzen haben. Im E-Commerce bedeuten sie verlorene Bestellungen und Zahlungsausfälle. In der Telekommunikation entgangene Anrufe, nicht erreichbare Nebenstellen oder unterbrochene Notrufvermittlung. In der Fertigung können Produktionsabläufe zum Erliegen kommen. Im Gesundheitswesen und bei der öffentlichen Sicherheit verzögern sich Kommunikation, Koordination und Reaktion.
Verfügbarkeit schützt zudem Vertrauen. Kunden, Mitarbeiter, Partner und Außendienstteams erwarten, dass moderne Systeme jederzeit erreichbar sind. Geht eine Plattform wiederholt offline, schwindet das Vertrauen – selbst wenn jede einzelne Störung kurz ist. Für Dienstanbieter und Unternehmensplattformen ist stabile Betriebszeit Teil des ganzheitlichen Produkterlebnisses.
Ein weiterer Grund ist die Betriebskontrolle. Ohne HA-Planung sind technische Teams oft auf Ad-hoc-Fehlersuche angewiesen, nachdem ein Fehler bereits Nutzer getroffen hat. Mit Redundanz, automatisierten Zustandsprüfungen, Failover-Logik und klaren Vorfallprozeduren werden Ausfälle zu beherrschbaren Ereignissen statt zu unerwarteten Krisen.
Ein hochverfügbares System geht nicht davon aus, dass Ausfälle niemals passieren. Es geht davon aus, dass sie passieren werden, und bereitet den Dienst darauf vor, auch dann weiterzuarbeiten.
Kernfunktionen für zuverlässigen Betrieb
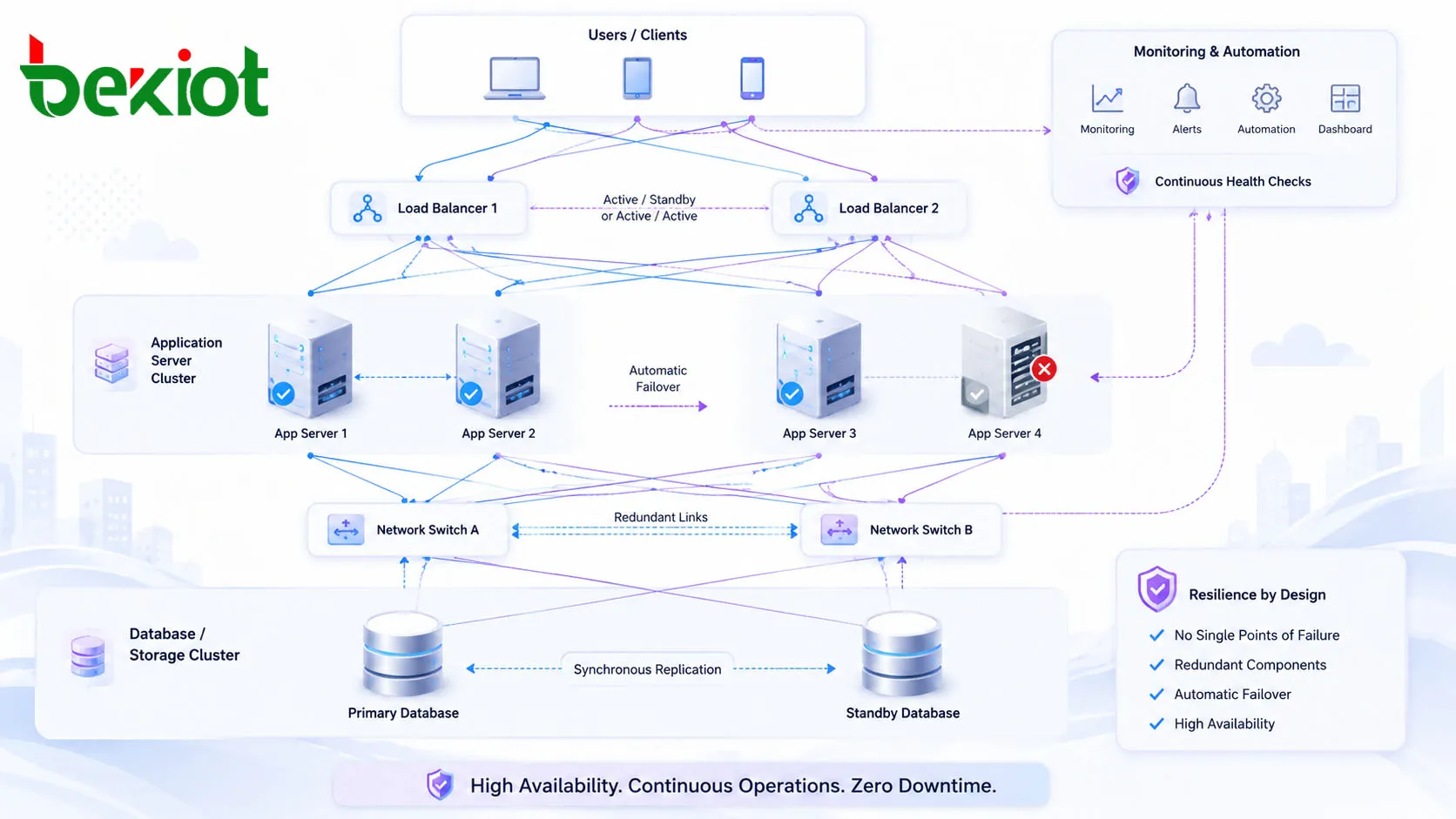
Redundante Infrastruktur
Redundanz ist das Fundament der Hochverfügbarkeit. Kritische Komponenten werden gedoppelt, sodass eine andere Komponente die Arbeit fortsetzen kann, wenn die aktive ausfällt. Redundanz kann mehrere Server, geclusterte Anwendungsknoten, gespiegelten Speicher, replizierte Datenbanken, doppelte Netzteile, Backup-Router, redundante Switches, mehrere Internetanbindungen und duplizierte Dienstinstanzen an verschiedenen Standorten umfassen.
Wirksame Redundanz muss den tatsächlichen Dienstpfad abdecken. Zwei Applikationsserver bieten keinen vollwertigen Schutz, wenn beide von einer einzigen Datenbank, einem Storage-Array, einer Firewall, einem Stromkreis oder einem externen Anbieter abhängen. HA-Planung muss jede Abhängigkeit überprüfen, die der Dienst zum Funktionieren benötigt.
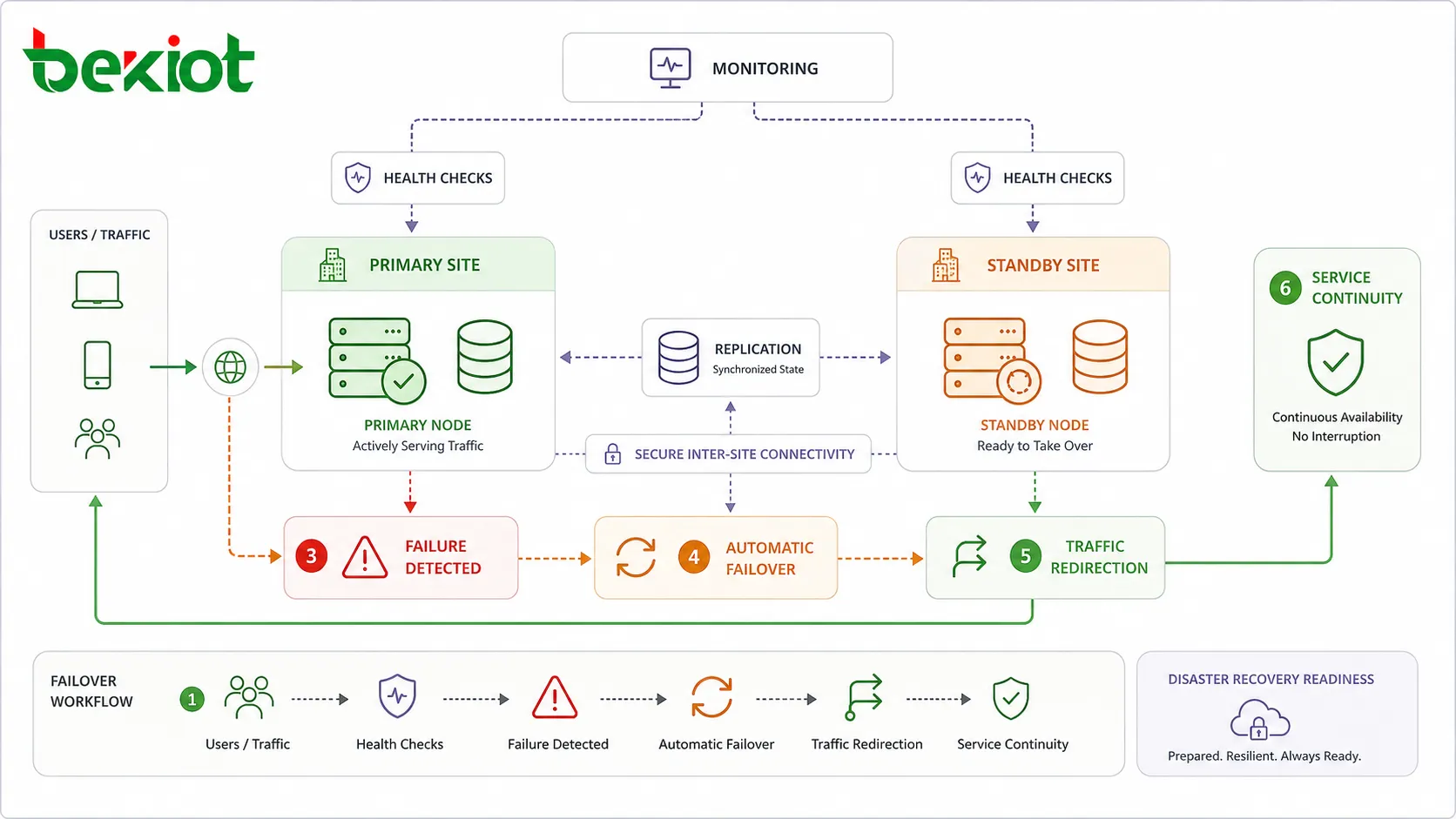
Automatisches Failover
Failover bezeichnet die Verlagerung eines Dienstes von einer ausgefallenen Komponente auf eine intakte. In vielen HA-Designs geschieht dies automatisch. Beispielsweise kann ein Load Balancer einen fehlerhaften Server aus der Rotation nehmen, eine Standby-Datenbank zur primären Datenbank werden oder eine Ausweichnetzroute einspringen, wenn die Hauptverbindung unterbrochen wird.
Automatisches Failover verkürzt die Wiederherstellungszeit, weil nicht auf die manuelle Diagnose durch einen Techniker gewartet werden muss. Allerdings muss die Failover-Logik sorgfältig entworfen werden. Sind die Zustandsprüfungen zu simpel, schaltet das System möglicherweise unnötig um. Greifen die Failover-Regeln zu langsam, erleben Nutzer längere Ausfälle als erwartet.
Überwachung des Dienstzustands
Überwachung ermöglicht es dem System und dem Betriebsteam, anormale Zustände frühzeitig zu erkennen. Eine sinnvolle Überwachung umfasst Servergesundheit, CPU- und Speicherauslastung, Plattenplatz, Dienstantwortzeit, Datenbankreplikation, Netzwerklatenz, Paketverlust, Anrufvervollständigung, Transaktionserfolgsrate, Zertifikatsablauf, Backup-Status und Sicherheitsereignisse.
Die nützlichsten Zustandsprüfungen sind an das reale Dienstverhalten gekoppelt. Ein Gerät antwortet auf Ping, während die Applikation eingefroren ist. Ein Webserver läuft, doch die Datenbankverbindung ist abgerissen. Ein Kommunikationsserver ist online, obwohl die Anrufvermittlung versagt. Die Überwachung muss bestätigen, ob der Dienst tatsächlich nutzbar ist.
Lastverteilung
Lastverteilung verteilt Verkehr auf mehrere Server oder Dienstinstanzen. Dies verbessert die Leistung im Normalbetrieb und stützt die Kontinuität bei Störungen. Wird ein Knoten überlastet oder fällt aus, kann der Datenverkehr auf andere gesunde Knoten umgelenkt werden.
Lastverteilung wird umfassend für Websites, APIs, Cloud-Anwendungen, Kommunikationsplattformen, Authentifizierungsdienste und interne Unternehmenssysteme eingesetzt. Je nach Auslegung kann sie Sitzungspersistenz, geografisches Routing, zustandsbasiertes Routing oder anwendungssensitive Verkehrssteuerung unterstützen.
Datenreplikation
Viele Systeme bleiben nur verfügbar, wenn auch die Daten verfügbar sind. Datenreplikation hält Kopien wichtiger Informationen auf mehreren Knoten oder Standorten vor. So kann ein sekundärer Server, ein weiteres Speichersystem oder ein zweites Rechenzentrum den Dienst fortsetzen, falls die primäre Umgebung versagt.
Die Replikation kann synchron oder asynchron erfolgen. Synchrone Replikation bestätigt einen Schreibvorgang erst, nachdem die Daten an mehr als einem Ort geschrieben wurden – das kann die Konsistenz verbessern, aber die Latenz erhöhen. Asynchrone Replikation ist meist schneller, jedoch kann bei einem plötzlichen Ausfall eine kleine Menge jüngster Daten gefährdet sein. Die richtige Wahl hängt vom geforderten Gleichgewicht zwischen Leistung, Konsistenz und akzeptablem Datenverlust ab.
Wartung ohne vollständige Abschaltung
Ein gutes HA-Design hilft auch bei geplanten Wartungsarbeiten. Systeme benötigen Updates, Sicherheitspatches, Hardwaretausch, Zertifikatserneuerungen, Konfigurationsänderungen und Kapazitätserweiterungen. Unterstützt die Architektur rollierende Updates oder kontrolliertes Failover, kann die Wartung ohne vollständige Dienstunterbrechung durchgeführt werden.
Das ist besonders für rund um die Uhr betriebene Dienste wertvoll. Statt auf lange Wartungsfenster zu warten, können Teams einen Knoten nach dem anderen aktualisieren, während die übrigen Knoten weiterhin Produktionsverkehr verarbeiten.
Gängige Architekturmuster
Aktiv-Passiv
In einem Aktiv-Passiv-Design verarbeitet ein System den Produktionsverkehr, während ein weiteres System in Bereitschaft bleibt, um zu übernehmen. Dieses Modell wird häufig für Firewalls, Datenbanken, Telefonanlagen, Gateways, Industrieanwendungen und zentrale Managementplattformen verwendet.
Der Vorteil der Aktiv-Passiv-Architektur liegt in der Einfachheit und dem vorhersagbaren Failover-Verhalten. Nachteilig ist, dass die Standby-Ressourcen im Normalbetrieb möglicherweise nicht voll genutzt werden. Das Bereitschaftssystem muss zudem regelmäßig getestet werden, um zu bestätigen, dass es synchronisiert und einsatzbereit ist.
Aktiv-Aktiv
In einem Aktiv-Aktiv-Design verarbeiten mehrere Systeme gleichzeitig Verkehr. Fällt ein Knoten aus, laufen die verbleibenden Knoten weiter und übernehmen die Arbeitslast. Dieses Modell kann sowohl die Verfügbarkeit als auch die Leistung steigern, weil die Kapazität kontinuierlich genutzt wird.
Eine Aktiv-Aktiv-Architektur erfordert in der Regel sorgfältigeres Design. Anwendungen müssen mit verteilten Sitzungen, Datenkonsistenz, Routing-Verhalten und möglichen Konfliktszenarien zurechtkommen. Ist die Software nicht für verteilten Betrieb ausgelegt, kann eine Aktiv-Aktiv-Implementierung eher Komplexität als Verlässlichkeit erzeugen.
Geclusterte Dienste
Ein Cluster ist eine Gruppe von Knoten, die als ein Dienst zusammenarbeiten. Geclusterte Systeme können Applikationen, Datenbanken, virtuelle Maschinen, Speicherplattformen, Container-Workloads und Kommunikationsdienste absichern. Cluster-Manager überwachen den Knotenzustand und koordinieren Failover oder die Neuverteilung der Arbeitslast.
Stabiler Clusterbetrieb setzt korrekte Heartbeat-Kommunikation, Quorum-Regeln, Fencing-Mechanismen und Netztrennung voraus. Diese Kontrollen helfen, Split-Brain-Situationen zu verhindern, in denen zwei Knoten fälschlich annehmen, beide seien das Primärsystem.
Multi-Site-Bereitstellung
Bei höheren Resilienzanforderungen können Systeme über mehrere Standorte, Rechenzentren, Cloud-Verfügbarkeitszonen oder Regionen hinweg bereitgestellt werden. Fällt ein Standort aufgrund eines Stromausfalls, Netzwerkproblems, physischen Schadens oder eines größeren Infrastrukturvorfalls aus, kann ein anderer Standort den Dienst fortsetzen.
Multi-Site-Design ist aufwändiger als lokale Redundanz. Es erfordert Verkehrslenkung, sichere Konnektivität, Replikationsplanung, konsistente Konfiguration, betriebliche Abstimmung und regelmäßige Disaster-Recovery-Tests. Zudem bedarf es klarer Regeln, wann der Verkehr zwischen Standorten umgeschaltet wird.
Metriken zur Messung der Dienstkontinuität
Betriebszeit in Prozent
Die prozentuale Betriebszeit misst, wie lange ein System innerhalb eines bestimmten Zeitraums betriebsbereit bleibt. Sie wird häufig in Service-Level-Agreements und internen Zuverlässigkeitszielen verwendet. Höhere Betriebszeitziele erfordern eine robustere Architektur, schnellere Wiederherstellung, bessere Überwachung und disziplinierteren Betrieb.
Allerdings sollte die Betriebszeit aus Anwendersicht gemessen werden. Ein System, das technisch läuft, aber keine Anfragen verarbeiten, Anrufe abschließen, Daten bereitstellen oder innerhalb annehmbarer Zeitgrenzen antworten kann, sollte nicht als voll verfügbar gelten.
Wiederherstellungszeit (RTO)
Das Recovery Time Objective (RTO) definiert, wie schnell ein Dienst nach einer Unterbrechung wiederhergestellt sein soll. Ein kurzes RTO verlangt meist automatisiertes Failover, einsatzbereite Standby-Kapazität, getestete Verfahren und schnelle Erkennung.
Das RTO sollte zur Geschäftsauswirkung passen. Nicht jedes System benötigt eine sofortige Wiederherstellung. Manche internen Systeme vertragen längere Wiederherstellungszeiten, während geschäftskritische Dienste nahezu kontinuierlichen Betrieb erfordern können.
Wiederherstellungspunktziel (RPO)
Das Recovery Point Objective (RPO) legt fest, wie viel Datenverlust nach einem Ausfall akzeptabel ist. Ein niedriges RPO erfordert häufige oder kontinuierliche Replikation. Ein höheres RPO kann die Wiederherstellung aus planmäßigen Backups erlauben.
Das RPO ist für Transaktionsdatensätze, Anruflisten, Ereignisverläufe, Produktionsdaten, Benutzerinformationen, Audit-Trails und Betriebsberichte von Bedeutung. Ist Datenverlust nicht hinnehmbar, müssen Replikation und Backup-Design strenger ausgelegt sein.
Mittlere Reparaturzeit (MTTR)
Die Mean Time to Repair (MTTR) misst, wie lange es dauert, nach einem Ausfall zum normalen Betrieb zurückzukehren. Hochverfügbarkeit verbessert sich, wenn die MTTR sinkt. Bessere Automatisierung, klarere Dokumentation, geschultes Personal, Vorratsressourcen und erprobte Wiederherstellungspläne helfen, die Reparaturzeit zu verkürzen.
Die Reparaturzeit zu verkürzen ist oft realistischer, als jeden möglichen Ausfall verhindern zu wollen. Selbst gut entworfene Systeme werden irgendwann ausfallen – eine gut vorbereitete Organisation kann sich jedoch schneller und mit geringeren Nutzerauswirkungen erholen.
Anwendungen in realen Umgebungen
Cloud-Plattformen und SaaS-Anwendungen
Cloud-Dienste und SaaS-Plattformen nutzen HA-Design, um Anwendungen für Nutzer über verschiedene Standorte und Zeitzonen hinweg zugänglich zu halten. Zu den gängigen Techniken gehören Auto-Scaling-Gruppen, Load Balancer, replizierte Datenbanken, verteilter Objektspeicher, Zustandsprüfungen, Backup-Regionen und rollierende Bereitstellungsstrategien.
Bei abonnementbasierten Diensten wirkt sich die Verfügbarkeit unmittelbar auf Kundenbindung und Markenreputation aus. Nutzer kennen die architektonischen Details meist nicht, bemerken aber sofort langsame Antwortzeiten, Anmeldefehler, fehlende Daten oder Dienstunterbrechungen.
Unternehmenskommunikationssysteme
Sprach-, Video-, Messaging-, Paging- und Dispositionssysteme benötigen oft Hochverfügbarkeit, weil Kommunikation sowohl im Routinebetrieb als auch bei dringenden Vorfällen erforderlich ist. HA-Planung kann redundante Anrufserver, Backup-SIP-Trunks, sekundäre Gateways, ausfallsichere Netzwerkpfade, lokal überlebensfähige Zweigstellensysteme und Notstrom umfassen.
Die Kommunikationsverfügbarkeit muss Ende-zu-Ende getestet werden. Es genügt nicht, dass ein Server online ist, wenn sich Telefone nicht registrieren, Anrufe nicht vermittelt werden, Sprache das Netzwerk nicht durchquert oder Notrufnummern nicht erreichbar sind.
Industrie- und Energiebetriebe
Industrieanlagen, Versorgungsbetriebe, Bergbaubetriebe, Häfen, Verkehrsknotenpunkte und Energieeinrichtungen sind oft auf durchgehende Überwachung und Kommunikation angewiesen. In solchen Umgebungen kann Hochverfügbarkeit redundante Glasfaserringe, drahtlose Backup-Strecken, doppelte Steuerungsserver, lokale Überlebensfähigkeit, robuste Geräte und isolierte Notfallpfade beinhalten.
Das Design muss sowohl IT-Ausfälle als auch physische Umgebungsbedingungen berücksichtigen. Raue Bedingungen, elektromagnetische Störungen, abgelegene Standorte, instabile Stromversorgung und eingeschränkter Wartungszugang können die Verfügbarkeit beeinträchtigen.
Gesundheitswesen und Rettungsdienste
Krankenhäuser, Notrufzentralen, Behörden mit Sicherheitsaufgaben und Leitstände sind auf zuverlässige Systeme zur Koordination angewiesen. Hochverfügbarkeit kann den Zugriff auf Patientendaten, Alarmbenachrichtigungen, Notfallkommunikation, Einsatzleitsystem-Workflows, Zutrittskontrolle, Videoüberwachung und interne Zusammenarbeit unterstützen.
In diesen Umgebungen ist ein Ausfall nicht bloß ein technisches Problem. Er kann Reaktionsgeschwindigkeit, Sicherheit, Entscheidungsfindung und die Kontinuität der Versorgung beeinträchtigen. Notstrom, redundante Netze, klare Eskalationsprozesse und regelmäßige Übungen sind hier besonders wichtig.
Finanzwesen, Einzelhandel und Online-Transaktionen
Banken, Zahlungsdienstleister, Handelsplattformen und Online-Shops benötigen verlässliche Systeme, um Transaktionen und Kundenzugänge zu schützen. Selbst kurze Ausfälle können zu fehlgeschlagenen Zahlungen, Umsatzverlusten, verzögerten Bestellungen, Abwicklungsproblemen oder Kundenbeschwerden führen.
Diese Systeme kombinieren häufig Verfügbarkeitsplanung mit strenger Sicherheit, Audit-Logging, Betrugsüberwachung, Verschlüsselung und Compliance-Kontrollen. Die Dienstkontinuität muss zusammen mit Datenintegrität und Risikomanagement konzipiert werden.
Planungsüberlegungen vor der Einführung
Die gesamte Abhängigkeitskette abbilden
Der erste Schritt besteht darin, zu verstehen, wie der Dienst tatsächlich funktioniert. Teams sollten Anwendungen, Datenbanken, Netzwerke, Speicher, Authentifizierung, DNS, Firewalls, Drittanbieterdienste, Zertifikate, Überwachungswerkzeuge und betriebliche Verantwortlichkeiten erfassen. Dies hilft, versteckte Abhängigkeiten zu identifizieren, die zu Single Points of Failure werden könnten.
Eine Dienstlandkarte hilft zudem bei der Entscheidung, welche Komponenten Redundanz benötigen und welche Risiken tragbar sind. Nicht jede Abhängigkeit verlangt das gleiche Schutzniveau, aber jede kritische Abhängigkeit muss sichtbar sein.
Realistische Wiederherstellungsziele setzen
Verfügbarkeitsziele sollten sich am Geschäftsbedarf orientieren, nicht an Marketingfloskeln. Eine geschäftskritische Plattform mag teure Redundanz und nahezu echtzeitnahe Replikation rechtfertigen. Ein nachrangiges Berichtstool benötigt vielleicht nur planmäßige Backups und manuelle Wiederherstellung.
Klare RTO- und RPO-Vorgaben helfen Teams, die passende Architektur zu wählen. Sie verhindern zudem, Systeme ohne fortgeschrittenen Schutzbedarf zu überentwickeln oder umgekehrt betriebswichtige Dienste unzureichend zu schützen.
Failover unter kontrollierten Bedingungen testen
Ein Failover-Plan ist nur so viel wert, wie er im Ernstfall funktioniert. Kontrollierte Tests prüfen, ob die Überwachung den Fehler erkennt, Standby-Ressourcen korrekt aktiviert werden, der Datenverkehr wie erwartet umgeleitet wird, die Daten konsistent bleiben und Nutzer ihre Arbeit fortsetzen können.
Die Tests sollten geplante Umschaltungen, die Simulation von Knotenausfällen, Netzwerkisolationen, Backup-Wiederherstellungen, Datenbank-Recoverys und Rollback-Verfahren umfassen. Die Ergebnisse sind zu dokumentieren, damit künftige Verbesserungen auf Fakten statt auf Annahmen beruhen.
Konfigurationsänderungen kontrollieren
Viele Ausfälle werden eher durch menschliche Fehler als durch Hardwaredefekte verursacht. Fehlerhafte Firewall-Regeln, abgelaufene Zertifikate, inkompatible Updates, falsche Routing-Änderungen, Datenbank-Berechtigungsfehler und inkonsistente Konfigurationen können den Dienst unterbrechen.
Änderungskontrolle, Versionsmanagement, Genehmigungsworkflows, Testumgebungen, Rollback-Pläne und Konfigurationsbackups reduzieren dieses Risiko. In HA-Umgebungen müssen das Primär- und das Standby-System stets synchron gehalten werden.
Herausforderungen und Grenzen
Hochverfügbarkeit reduziert Ausfallzeiten, macht ein System aber nicht narrensicher. Softwarefehler, Ransomware, Konfigurationsirrtümer, Datenkorruption, Ausfälle von Abhängigkeiten, regionale Katastrophen und Bedienfehler können den Dienst weiterhin stören. HA sollte stets mit Backup, Cybersicherheit, Disaster Recovery, Observability und Incident Response zusammenwirken.
Kosten sind eine weitere Herausforderung. Eine redundante Architektur erfordert möglicherweise mehr Server, Netzwerkgeräte, Cloud-Ressourcen, Lizenzen, Überwachungssysteme, Speicherkapazität und Betriebsexpertise. Je höher das Verfügbarkeitsziel, desto wichtiger wird die Rechtfertigung der Investition.
Auch Komplexität kann zum Risiko werden. Ein kompliziertes HA-Design, das das Betriebsteam nicht durchdringt, kann in einem Vorfall versagen. Praktische Hochverfügbarkeit muss dokumentiert, testbar und von den dafür Verantwortlichen beherrschbar sein.
Die beste Verfügbarkeitsstrategie ist nicht immer die komplizierteste. Es ist diejenige, welche die wichtigsten Dienste schützt, regelmäßig getestet werden kann und bei echten Vorfällen souverän betrieben werden kann.
Bewährte Verfahren für langfristige Zuverlässigkeit
Beginnen Sie mit der Klassifizierung der Dienste. Identifizieren Sie, welche Systeme geschäftskritisch, welche betriebswichtig sind und welche längere Wiederherstellungszeiten vertragen. So können Ressourcen dorthin gelenkt werden, wo Ausfallzeiten die stärksten Auswirkungen haben.
Nutzen Sie ein Monitoring, das die tatsächlichen Nutzerergebnisse widerspiegelt. Prüfen Sie nicht nur den Gerätestatus, sondern überwachen Sie, ob Benutzer sich anmelden, telefonieren, Datensätze abrufen, Formulare absenden, Benachrichtigungen erhalten oder Transaktionen abschließen können. Das liefert ein realistischeres Bild der Dienstgesundheit.
Halten Sie die Dokumentation aktuell. Architekturdiagramme, Failover-Schritte, Kontaktlisten, Eskalationswege, Backup-Positionen, Berechtigungsmanagement und Rollback-Verfahren sollten nach jeder größeren Änderung aktualisiert werden. Veraltete Dokumentation kann im Vorfall die Wiederherstellung verzögern.
Überprüfen Sie die Architektur regelmäßig. Verkehrsaufkommen, Softwareversionen, Sicherheitsanforderungen, Drittanbieterabhängigkeiten und Geschäftsprioritäten verändern sich im Laufe der Zeit. Ein System, das früher die Verfügbarkeitsziele erfüllte, benötigt bei steigender Nutzung und gewachsenem Risiko möglicherweise eine Neugestaltung.
Fazit
Hochverfügbarkeit ist eine praktische Methode, um wichtige Dienste auch bei Ausfällen zugänglich zu halten. Sie vereint redundante Infrastruktur, automatisches Failover, Zustandsüberwachung, Lastverteilung, Datenreplikation, Wartungsplanung und erprobte Wiederherstellungsverfahren. Ihr Wert zeigt sich besonders deutlich, wenn Ausfallzeiten Sicherheit, Umsatz, Kommunikation, Produktion, Compliance oder Kundenvertrauen gefährden.
Eine erfolgreiche HA-Strategie besteht nicht nur darin, mehr Ausrüstung hinzuzufügen. Sie erfordert das Verständnis der gesamten Dienstkette, die Identifikation von Single Points of Failure, realistische Wiederherstellungsziele, getestetes Failover und die Abwägung von Zuverlässigkeit gegen Kosten und Komplexität. Richtig konzipiert, hilft Hochverfügbarkeit Unternehmen, Systeme aufzubauen, die auch unter realen Bedingungen verlässlich bleiben.
FAQ
Kann ein hochverfügbares System trotzdem Daten verlieren?
Ja. Verfügbarkeit und Datenschutz hängen zusammen, sind aber nicht dasselbe. Hinkt die Replikation hinterher oder sind die Backup-Richtlinien schwach, kann ein Dienst zwar schnell wieder anlaufen, dabei jedoch jüngste Daten einbüßen. Eine RPO-Planung ist nötig, um dieses Risiko zu beherrschen.
Ist Hochverfügbarkeit dasselbe wie Fehlertoleranz?
Nein. Fehlertoleranz bedeutet üblicherweise, dass ein System auch beim Ausfall einer Komponente nahezu unterbrechungsfrei weiterläuft. Hochverfügbarkeit zielt auf die Minimierung von Ausfallzeiten ab – je nach Architektur kann dennoch eine kurze Failover-Verzögerung auftreten.
Sollten auch kleine Unternehmen auf Hochverfügbarkeit setzen?
Ja, aber der Entwurf muss zur geschäftlichen Betroffenheit passen. Ein Kleinbetrieb benötigt vielleicht keine Multi-Region-Architektur, kann aber dennoch von redundanten Internetzugängen, zuverlässigen Backups, Cloud-basiertem Failover, überwachten Diensten und Notstrom für kritische Systeme profitieren.
Kann Hochverfügbarkeit vor Cyberangriffen schützen?
Nur teilweise. HA kann helfen, den Dienst aufrechtzuerhalten, wenn ein Knoten isoliert oder wiederhergestellt wird, ersetzt jedoch keine Cybersicherheitskontrollen. Ransomware, Zugangsdatendiebstahl, DDoS-Angriffe und Datenmanipulation erfordern Sicherheitsüberwachung, Zugriffskontrollen, Patch-Management, Backup-Isolation und Incident-Response.
Unterstützt jede Anwendung einen Aktiv-Aktiv-Betrieb?
Nein. Manche Anwendungen sind nicht für verteilte Sitzungen, gemeinsam genutzte Zustände oder schreibende Zugriffe auf mehrere Knoten ausgelegt. Vor der Entscheidung für eine Aktiv-Aktiv-Architektur müssen Teams prüfen, ob Software, Datenbank, Lizenzmodell und Netzwerkdesign dies sicher unterstützen.







