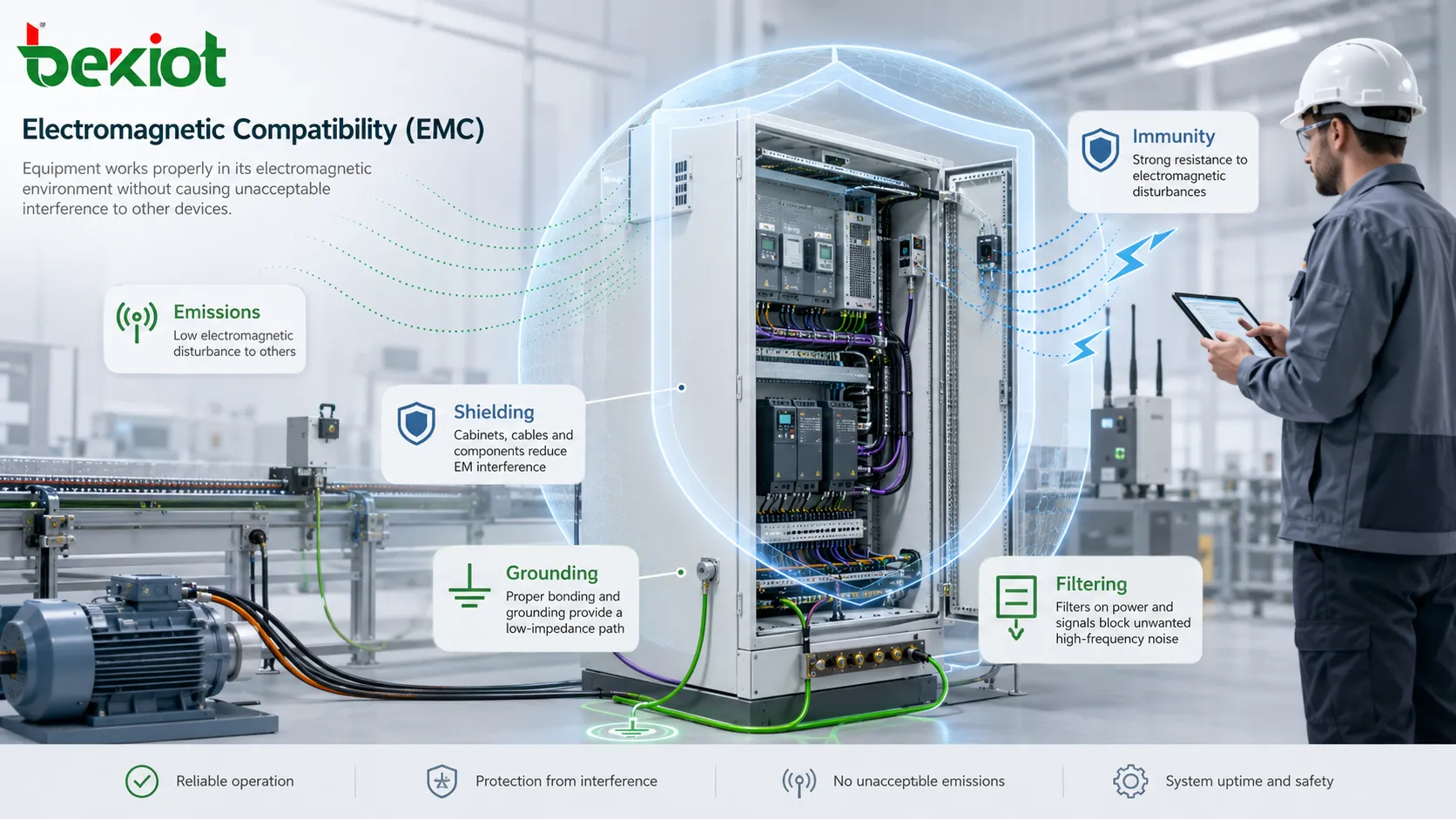
Redundanz bezeichnet die bewusste Duplizierung kritischer Komponenten, Funktionen, Verbindungen oder Ressourcen in einem System, damit der Dienst auch dann fortgesetzt werden kann, wenn ein Teil ausfällt. In praktischer technischer und betrieblicher Hinsicht ist Redundanz keine Verschwendung. Sie ist eine Zuverlässigkeitsstrategie. Das Ziel ist es, einzelne Fehlerquellen zu reduzieren und die Fähigkeit eines Systems zu verbessern, während Fehlern, Wartungsereignissen, Überlastbedingungen oder unerwarteten Störungen verfügbar zu bleiben.
Das Konzept tritt in vielen technischen und betrieblichen Bereichen auf. In der Netzwerktechnik kann Redundanz duale Uplinks, Backup-Switches oder mehrere Übertragungswege bedeuten. In der Telefonie und Unified Communications kann sie redundante SIP-Server, Standby-IP-PBX-Plattformen, duplizierte Gateways oder eine Backup-Anrufroutinglogik umfassen. In Stromversorgungssystemen kann sie duale Netzteile, Batterie-Backup und redundante Stromeinspeisungen umfassen. In industriellen Umgebungen erstreckt sich Redundanz oft weiter auf duplizierte Controller, Kommunikationswege, Feldgeräte und Failover-Server, die hochverfügbare Abläufe unterstützen.
Obwohl Redundanz häufig im Zusammenhang mit Infrastruktur und kritischen Systemen diskutiert wird, ist die zugrunde liegende Idee einfach. Ein System wird zerbrechlich, wenn ein einziger Fehler den gesamten Dienst stoppen kann. Redundanz verringert diese Zerbrechlichkeit, indem sie sicherstellt, dass ein alternativer Pfad, ein alternatives Gerät oder eine alternative Dienstinstanz bereits vorbereitet ist, um zu übernehmen. Aus diesem Grund ist Redundanz eines der wichtigsten Entwurfsprinzipien in Kommunikationsnetzen, Sicherheitssystemen, Automatisierungsplattformen, Systemen der öffentlichen Sicherheit und der Unternehmens-IT-Architektur.

Redundanz verbessert die Dienstkontinuität, indem sie Backup-Ressourcen hinzufügt und einzelne Fehlerquellen reduziert.
Was Redundanz in der Praxis bedeutet
Mehr als eine einfache Sicherung
Viele Menschen verwenden die Wörter Redundanz und Sicherung so, als ob sie dasselbe bedeuten, aber im realen Systementwurf sind sie verwandt, nicht identisch. Eine Sicherung ist oft eine Reservekopie oder eine Standby-Ressource, die nach einem Fehler verwendet werden kann, während Redundanz normalerweise impliziert, dass bereits mehrere Ressourcen in die Live-Systemarchitektur eingebaut sind. Mit anderen Worten: Bei Redundanz geht es nicht nur um die Wiederherstellung, nachdem etwas schiefgegangen ist. Es geht darum, das System so zu gestalten, dass es mit minimaler Unterbrechung weiterarbeiten kann, wenn etwas schiefgeht.
Beispielsweise ist eine offline gespeicherte Backup-Konfigurationsdatei nützlich, aber sie schafft keine Echtzeit-Dienstkontinuität. Im Gegensatz dazu können ein redundantes Serverpaar, ein sekundärer Netzwerkpfad oder eine zweite Stromversorgung die Kontinuität unterstützen, während das System noch läuft. Diese Unterscheidung ist besonders wichtig in Umgebungen, in denen Dienstunterbrechungen kostspielig oder gefährlich sind, wie in Krankenhäusern, Kontrollräumen, Verkehrsknotenpunkten, Industrieanlagen, Notfallkommunikationssystemen und großen Unternehmensnetzwerken.
Deshalb wird Redundanz oft als Teil der Verfügbarkeitstechnik behandelt und nicht nur als Teil der Notfallwiederherstellung. Sie befasst sich mit der Frage, wie sich das System während eines Fehlers verhält, und nicht nur damit, wie es wiederhergestellt werden kann, nachdem der Fehler bereits zu Ausfallzeiten geführt hat.
Reduzierung einzelner Fehlerquellen
Der häufigste Grund für den Einsatz von Redundanz ist die Beseitigung oder Verringerung einzelner Fehlerquellen. Eine einzelne Fehlerquelle ist jede Komponente, deren Ausfall das gesamte System zum Absturz bringen kann. Dies kann ein Netzwerk-Switch, ein Netzteilmodul, ein Server, ein Speichergerät, ein Gateway, ein Controller oder sogar ein Kabelpfad sein. Wenn dieses Element ausfällt und keine Alternative existiert, stoppt der Dienst.
Redundanz ändert dieses Risikomodell. Anstatt von einem einzigen kritischen Element abzuhängen, wird das System so gestaltet, dass eine andere Komponente, ein anderer Weg oder eine andere Instanz die Aufgabe fortsetzen kann. In einigen Entwürfen bleibt die Reserve-Ressource untätig, bis sie benötigt wird. In anderen sind beide Ressourcen aktiv und teilen sich die Last. In beiden Fällen ist das Ziel, den Dienst auch dann verfügbar zu halten, wenn ein Fehler auftritt.
Aus diesem Grund ist Redundanz in modernen Kommunikationssystemen so wertvoll. Sprach-, Daten-, Steuerungs- und Alarmfunktionen sind zunehmend auf eine vernetzte digitale Infrastruktur angewiesen. Wenn ein Fehler mehrere Dienste gleichzeitig beeinträchtigt, können die betrieblichen Auswirkungen viel größer sein als in älteren, isolierten Systemen. Redundanz hilft, dieses Risiko zu begrenzen.
Redundanz ist die technische Entscheidung, davon auszugehen, dass Fehler auftreten werden, und das System so zu gestalten, dass diese Fehler nicht zum Dienstzusammenbruch führen.
Wie Redundanz funktioniert
Standby- und Active-Active-Modelle
Redundanz kann auf verschiedene Weise implementiert werden, aber zwei gängige Modelle sind Active-Standby und Active-Active. Bei einem Active-Standby-Design übernimmt die primäre Ressource den Dienst unter normalen Bedingungen, während die sekundäre Ressource in Reserve wartet. Fällt die primäre aus, übernimmt die sekundäre. Dieser Ansatz ist bei Servern, Controllern, Gateways, Netzteilen und Kommunikationsknoten üblich, bei denen ein vereinfachtes Failover-Verhalten erwünscht ist.
Bei einem Active-Active-Modell sind mehrere Ressourcen gleichzeitig aktiv. Sie können den Verkehr gemeinsam nutzen, Anfragen parallel verarbeiten oder gegenseitige Kontinuität bieten, wenn eine Instanz ausfällt. Dieses Design kann sowohl die Verfügbarkeit als auch die Kapazität verbessern, erfordert jedoch oft eine sorgfältigere Synchronisierung, Zustandsverwaltung und Verkehrssteuerung. In Netzwerk- und Datendiensten sind Active-Active-Ansätze besonders verbreitet, wenn sowohl Lastverteilung als auch kontinuierliche Reaktionsfähigkeit wichtig sind.
Die beste Wahl hängt von der Anwendung ab. Active-Standby ist oft einfacher zu steuern und zu überprüfen, während Active-Active in größeren Systemen eine stärkere Leistung und eine reibungslosere Kontinuität bieten kann. Beide Ansätze sind Formen der Redundanz, unterscheiden sich jedoch im Betriebsverhalten und in der Designkomplexität.
Failover-, Switchover- und Wiederherstellungslogik
Redundanz wird nur dann nützlich, wenn das System weiß, wie es auf Fehler reagieren soll. Hier ist die Failover-Logik wichtig. Ein redundantes Design umfasst normalerweise Zustandsüberwachung, Heartbeat-Signale, Synchronisationsmechanismen, Rollendefinitionen und Switchover-Regeln. Wenn das System erkennt, dass eine Ressource nicht mehr korrekt funktioniert, leitet es einen Übergang ein, damit die alternative Ressource den Dienst weiter erbringen kann.
Dieser Übergang kann je nach Umgebung automatisch oder manuell sein. In der kritischen Kommunikation wird oft das automatische Failover bevorzugt, da Verzögerungen den Sprachverkehr oder Reaktionsabläufe stören können. In einigen industriellen oder regulierten Umgebungen wird möglicherweise ein überwachter oder halbmanueller Switchover verwendet, um die Kontrolle über den Systemzustand und die Prozesssicherheit zu behalten. In beiden Fällen hängt die Effektivität der Redundanz nicht nur von zusätzlicher Hardware oder Software ab, sondern auch von der korrekten Verwaltung des Übergangs.
Auch die Wiederherstellung nach einem Failover ist wichtig. Sobald die ausgefallene Komponente repariert ist, muss das System entscheiden, ob es den Dienst sofort an die ursprüngliche Ressource zurückgibt, auf die Zustimmung des Bedieners wartet oder das Backup bis zu einem geplanten Wartungsfenster unter Kontrolle hält. Diese Richtlinienentscheidungen beeinflussen die Stabilität und sollten geplant und nicht improvisiert werden.
Synchronisierung und Zustandsbewusstsein
In vielen redundanten Systemen muss die sekundäre Ressource bereit sein, zu übernehmen, ohne den kritischen Kontext zu verlieren. Das bedeutet, dass Konfigurationsdaten, Sitzungsinformationen, Anrufzustand, Routing-Tabellen, Benutzerdaten, Alarme oder Anwendungsstatus zwischen primären und sekundären Komponenten synchronisiert werden müssen. Ohne Synchronisierung kann ein Failover zwar die Infrastrukturverfügbarkeit erhalten, aber dennoch die Diensterfahrung erheblich beeinträchtigen.
Dies ist besonders wichtig in Sprach- und Kommunikationssystemen. Eine redundante SIP-Plattform, ein Dispositionsserver oder eine IP-PBX benötigt möglicherweise synchronisierte Benutzerprofile, Nebenstellerdaten, Routing-Richtlinien und Registrierungslogik. In Speicher- und Virtualisierungsumgebungen hilft der synchronisierte Zustand, Dateninkonsistenzen zu verhindern. In industriellen Steuerungssystemen ist synchronisierte Logik unerlässlich, um das Automatisierungsverhalten während des Wechsels vorhersehbar zu halten.
Aus diesem Grund geht es bei Redundanz nicht nur um physische Duplizierung. Es geht auch um informationelle Kontinuität. Ein Standby-Server, der existiert, aber nicht synchronisiert ist, kann die Organisation immer noch anfällig für Dienstunterbrechungen machen, wenn er übernimmt.
Hauptmerkmale der Redundanz
Hohe Verfügbarkeitsunterstützung
Das am weitesten anerkannte Merkmal der Redundanz ist die verbesserte Verfügbarkeit. Ein redundantes Design hilft Diensten, auch dann zugänglich zu bleiben, wenn Hardware-, Software- oder Konnektivitätsprobleme auftreten. Anstatt die Betriebszeit als Glückssache zu betrachten, macht Redundanz die Verfügbarkeit zu einem Teil der Architektur selbst. Dies ist besonders wertvoll in Systemen, die Live-Kommunikation, Betriebskoordination, Alarme, Sicherheit oder kundenorientierte Interaktion unterstützen.
Bei realen Bereitstellungen geht es bei hoher Verfügbarkeit nicht nur darum, ob das System technisch online ist. Es geht auch darum, ob Benutzer ihre Arbeit mit minimalen Unterbrechungen fortsetzen können. Ein Kommunikationssystem, das während eines einzelnen Serverfehlers alle aktiven Registrierungen verliert oder unerreichbar wird, erfüllt möglicherweise nicht die Betriebserwartungen, selbst wenn es schnell neu gestartet werden kann. Redundanz reduziert diese Gefährdung, indem sie Kontinuitätspfade im Voraus vorbereitet.
Aus diesem Grund ist das Design hoher Verfügbarkeit oft untrennbar mit der Redundanzplanung verbunden. Wo Betriebszeit wichtig ist, ist Redundanz normalerweise eines der wichtigsten Werkzeuge, um sie zu erreichen.
Fehlertoleranz und Dienstkontinuität
Redundanz ist eng mit Fehlertoleranz verbunden, aber die beiden Ideen sind nicht genau gleich. Fehlertoleranz bezieht sich auf die Fähigkeit eines Systems, trotz Fehlern korrekt zu funktionieren. Redundanz ist einer der Mechanismen, die dazu beitragen, dieses Ergebnis zu erzielen. Durch die Duplizierung kritischer Ressourcen gewinnt das System Toleranz gegenüber Ausfällen in Bereichen, die andernfalls sofortige Dienstunterbrechungen verursachen würden.
In Kommunikations- und Infrastruktursystemen bedeutet dies, dass Benutzer oft weiterhin Anrufe tätigen, auf Dienste zugreifen oder Daten austauschen können, selbst wenn ein Knoten, eine Verbindung oder eine Stromquelle ausfällt. In industriellen Umgebungen kann dies bedeuten, dass Überwachungs-, Rundfunk-, Gegensprech- oder Steuerungsvorgänge ohne gefährlichen blinden Fleck fortgesetzt werden. In der Unternehmens-IT kann es ermöglichen, dass Anwendungen und Benutzersitzungen verfügbar bleiben, während Fehler isoliert und repariert werden.
Die Dienstkontinuität ist das praktische Ergebnis, das den Benutzern am Herzen liegt. Sie sehen die Redundanzlogik vielleicht nicht direkt, aber sie erleben das System als zuverlässig und widerstandsfähig unter Stress.
Flexible Wartung und betriebliche Widerstandsfähigkeit
Ein weiteres wichtiges Merkmal der Redundanz ist, dass sie Wartung ohne vollständige Dienstunterbrechung unterstützt. Wenn eine Plattform über redundante Server, Switches, Verbindungen oder Netzteile verfügt, können Techniker möglicherweise einen Teil warten, während der andere Teil die Arbeitslast weiter trägt. Dies verbessert die Lebenszyklusverwaltbarkeit und reduziert die Kosten für Wartungsfenster.
Redundanz unterstützt auch die betriebliche Widerstandsfähigkeit bei teilweiser Degradierung. Nicht jedes Problem ist ein Totalausfall. Manchmal liegt das Problem in Überlastung, intermittierender Instabilität, geplanten Upgrades oder vorübergehenden Umgebungsstörungen. Ein redundantes Design bietet Optionen zur Umleitung, Isolierung und Stabilisierung von Diensten, bevor ein kleines Problem zu einem großen Ausfall wird.
Diese Widerstandsfähigkeit wird immer wichtiger, da Unternehmen auf immer aktive digitale Kommunikation angewiesen sind. Das System muss nicht nur seltene Katastrophen überleben, sondern auch alltägliche Fehler und Wartungsrealitäten.

Redundanz unterstützt hohe Verfügbarkeit, Fehlertoleranz und flexiblere Wartung in Kommunikations- und Infrastruktursystemen.
Häufige Arten von Redundanz
Netzwerkredundanz
Netzwerkredundanz ist eine der häufigsten Formen. Sie kann mehrere Uplinks, redundante Switches, duale Router, Ringtopologien, Maschenverbindungen oder alternative WAN-Pfade umfassen. Der Zweck ist sicherzustellen, dass der Verkehr noch fließen kann, wenn eine Verbindung oder ein Gerät ausfällt. In Geschäfts- und Industrienetzen ist dies unerlässlich, da ein Netzwerkausfall gleichzeitig Sprache, Video, Alarme, Steuerungsverkehr und Geschäftsanwendungen beeinträchtigen kann.
In realen Projekten wird Netzwerkredundanz oft mit Spanning-Protokollen, Routing-Failover, schnellen Wiederherstellungsmechanismen, VLAN-Design und QoS-Planung kombiniert. Das Netzwerk sollte nicht nur über zusätzliche Verbindungen verfügen, sondern auch wissen, wie es sie nutzen kann, ohne Schleifen, Instabilität oder unvorhersehbares Switching-Verhalten zu verursachen. Dies ist besonders wichtig für VoIP- und SIP-Verkehr, wo Verzögerung und Verlust den Dienst schnell verschlechtern können.
Da sich Kommunikationssysteme über Fabriken, Campusse, Verkehrsstandorte und Versorgungsumgebungen ausbreiten, wird Netzwerkredundanz zu einer grundlegenden Anforderung und nicht zu einer optionalen Verbesserung.
Server- und Anwendungsredundanz
Serverredundanz wird verwendet, wenn Anwendungen, Steuerungslogik oder Kommunikationsdienste trotz Hardware- oder Softwareausfall verfügbar bleiben müssen. Dies kann geclusterte Server, virtualisierte Failover-Umgebungen, gespiegelte Anwendungsknoten oder Standby-Dienstinstanzen umfassen. Auf SIP- und IP-Kommunikationsplattformen kann Redundanz Anrufsteuerungsserver, Provisionierungssysteme, Voicemail-Plattformen, Dispositionsserver und Verwaltungsanwendungen abdecken.
Anwendungsredundanz ist besonders wichtig, wenn Benutzer für Registrierung, Authentifizierung, Routing oder Koordinierung auf zentrale Dienste angewiesen sind. Wenn ein einzelner Kommunikationsserver ausfällt, können Hunderte oder Tausende von Endpunkten betroffen sein. Redundanz reduziert diese Risikokonzentration, indem sie sicherstellt, dass der Dienst von einem anderen Knoten aus fortgesetzt werden kann.
Eine erfolgreiche Serverredundanz erfordert mehr als die Installation einer zweiten Maschine. Sie hängt auch von Synchronisierung, Zustandsprüfungen, Datenbankhandhabung und einer klar definierten, zur Anwendung passenden Failover-Sequenz ab.
Stromredundanz
Viele Ausfälle beginnen nicht mit Softwarefehlern, sondern mit Stromunterbrechungen. Die Stromredundanz begegnet diesem Risiko, indem sie mehr als eine Energiequelle oder einen Energieversorgungspfad bereitstellt. Häufige Beispiele sind doppelte Netzteile, unabhängige Stromzuführungen, USV-Anlagen, Batterie-Backup, Generatorintegration und die Duplizierung von Strommodulen in Netzwerk- oder Kommunikationsgeräten.
In Kommunikationssystemen ist die Stromredundanz von entscheidender Bedeutung, da selbst eine gut gestaltete Netzwerk- und Serverarchitektur unverfügbar wird, wenn an einem zentralen Knoten oder Feldendpunkt der Strom ausfällt. Dies ist besonders wichtig in der Notfalltelefonie, in Rufsystemen, der Transportkommunikation, der industriellen Gegensprechanlage und in Kontrollraumumgebungen, in denen der Dienst bei Infrastrukturbelastung am dringendsten benötigt wird.
Aus diesem Grund wird die Stromredundanz oft als untrennbar mit der Kommunikationsredundanz betrachtet. Der Netzwerkpfad und der Strompfad müssen beide widerstandsfähig sein, sonst kann das allgemeine Verfügbarkeitsziel nicht erreicht werden.
Speicher- und Datenredundanz
Auch Daten benötigen Schutz. Speicherredundanz kann gespiegelte Festplatten, RAID-Konfigurationen, replizierte Datenbanken, synchronisierte Speicherknoten und entfernte Datenkopien umfassen. Der Zweck ist es, Informationsverlust oder Dienstunterbrechung zu verhindern, wenn ein Speichergerät ausfällt. In Unternehmenssystemen unterstützt dies die Anwendungskontinuität. Auf Kommunikationsplattformen kann es Benutzerdaten, Protokolle, Voicemail, Konfigurationsdaten, Routing-Regeln und den Ereignisverlauf schützen.
Die Speicherredundanz sollte jedoch nicht mit vollständigem Datenschutz verwechselt werden. Spiegelung schützt vor einigen Arten von Hardwareausfällen, aber sie löst nicht automatisch Korruption, versehentliches Löschen oder Anwendungsfehler. Aus diesem Grund kombinieren Organisationen Redundanz normalerweise mit Backup- und Wiederherstellungsplanung, anstatt eine als Ersatz für die andere zu behandeln.
Dies veranschaulicht einen wichtigen Punkt: Redundanz verbessert die Kontinuität, funktioniert aber am besten, wenn sie mit einer umfassenderen Resilienzstrategie kombiniert wird.
Anwendungen der Redundanz
Kommunikationssysteme und IP-Telefonie
Redundanz wird in Kommunikationsplattformen häufig eingesetzt, da von Sprachdiensten erwartet wird, dass sie kontinuierlich verfügbar sind. In SIP- und IP-Telefonieumgebungen kann Redundanz duplizierte SIP-Server, Backup-IP-PBX-Knoten, sekundäre Session-Border-Elemente, redundante Gateways und alternative WAN-Konnektivität umfassen. Diese Designs helfen sicherzustellen, dass Anrufe auch dann noch verarbeitet werden können, wenn ein Knoten oder Pfad ausfällt.
In der Praxis ist dies wichtig für Büros, Campusse, Krankenhäuser, Industriestandorte, Verkehrseinrichtungen und Notfallkoordinationszentren. Ein Telefonsystem kann für den täglichen Betrieb, die Kundeninteraktion und die Reaktion auf Vorfälle zentral sein. Wenn der Hauptserver oder Netzwerkpfad ohne Redundanz ausfällt, können die Kommunikationsauswirkungen sofort und weitreichend sein.
Aus diesem Grund betrachtet die moderne Geschäftstelefonie Redundanz zunehmend als erwartetes architektonisches Merkmal und nicht als zusätzliche Option. Da Systeme stärker mit Rufanlagen, Gegensprechanlagen, Alarmanlagen, Video und Disposition integriert werden, wird der Wert der Kommunikationskontinuität noch höher.
Industrielle Steuerung und kritische Infrastruktur
Industrielle Umgebungen und kritische Infrastrukturen sind stark auf Redundanz angewiesen, da eine Dienstunterbrechung nicht nur die Produktivität, sondern auch die Sicherheit beeinträchtigen kann. Kraftwerke, Raffinerien, Tunnel, U-Bahn-Systeme, Wasseraufbereitungsanlagen, Versorgungskorridore und Produktionsstätten verwenden häufig redundante Kommunikationsverbindungen, Steuerungsserver, Netzwerkpfade und Stromversorgungskonzepte, um Betriebsrisiken zu reduzieren.
In solchen Umgebungen kann Redundanz SCADA-Kommunikation, industrielle Telefonie, PAGA-Systeme, Alarmrundfunk, Dispositionskonsolen, Feldgegensprechanlagen und zentrale Überwachungsplattformen unterstützen. Das Ziel ist es, die Sichtbarkeit und Kontrolle auch bei Gerätefehlern oder Infrastrukturbelastung zu bewahren. Dies ist besonders wichtig, wo Bediener ein kontinuierliches Bewusstsein für den Anlagenstatus und die Fähigkeit zur Kommunikation mit Feldpersonal benötigen.
Da die Kosten eines Ausfalls hoch sein können, wird Redundanz in diesen Sektoren in der Regel bewusster geplant und strenger getestet als in normalen Büroumgebungen.
Rechenzentren, Unternehmens-IT und Cloud-Dienste
In Unternehmens-IT- und Rechenzentrumsumgebungen unterstützt Redundanz die Anwendungsverfügbarkeit, Dienstkontinuität und Geschäftswiderstandsfähigkeit. Organisationen verwenden redundante Rechenknoten, Netzwerk-Fabrics, Speichersysteme, Kühlpfade und Strominfrastrukturen, um digitale Dienste zugänglich zu halten. Selbst wenn Cloud-Dienste involviert sind, bleibt Redundanz wichtig, da die Architektur immer noch von widerstandsfähiger Konnektivität, Plattformdesign und Dienstverteilung abhängt.
Für Benutzer kann dies als eine Website erscheinen, die online bleibt, eine Kommunikationsplattform, die weiterarbeitet, oder ein Remote-Kooperationsdienst, der lokale Fehler überlebt. Hinter dieser Erfahrung steht oft ein sorgfältig geschichtetes Redundanzmodell, das Risiken über Hardware-, Software- und Konnektivitätsschichten verteilt.
Da Geschäftsabläufe digitaler werden, wird Redundanz weniger zu einem Spezialistenthema und mehr zu einer Grundvoraussetzung für zuverlässige Dienstleistungserbringung.
Sicherheits-, Schutz- und Notfalleinsätze
Sicherheits- und Notfallsysteme sind ein weiteres wichtiges Anwendungsgebiet. Videoüberwachungs-Backbones, Zugangskontrollserver, Notrufplattformen, Beschallungssysteme, Dispositionslösungen und Alarmverteilungsnetze erfordern oft Redundanz, da sie unter abnormalen Bedingungen verfügbar bleiben müssen. In vielen Fällen sind dies genau die Momente, in denen die Systeme am dringendsten benötigt werden.
Beispielsweise kann ein Notrufstellennetz redundante Kommunikationsrouten und Notstrom benötigen. Ein Kontrollraum benötigt möglicherweise duplizierte Server und alternative Sprachpfade. Ein Rundfunksystem für die öffentliche Sicherheit kann redundante Verstärker, Netzwerk-Switches oder zentrale Verwaltungsknoten erfordern. Ohne Redundanz kann das System genau dann ausfallen, wenn seine Funktion kritisch wird.
Aus diesem Grund wird Redundanz oft als ein zentrales Entwurfsprinzip in sicherheitsbezogenen Kommunikations- und Überwachungsarchitekturen behandelt.

Redundanz wird in der Telefonie, in industriellen Systemen, der Unternehmens-IT und sicherheitskritischen Kommunikumgebungen häufig eingesetzt.
Der Wert der Redundanz wird am deutlichsten sichtbar, wenn das Unerwartete passiert und das System trotzdem weiterarbeitet.
Entwurfsüberlegungen für redundante Systeme
Komplexität, Kosten und Tests
Redundanz erhöht die Widerstandsfähigkeit, aber auch die Komplexität. Mehr Geräte, mehr Verbindungen, mehr Logik und mehr Synchronisationsanforderungen können die Entwurfslast erhöhen. Wenn sie schlecht implementiert ist, kann ein redundantes System schwer zu verwalten sein oder während des Switchovers unvorhersehbar ausfallen. Aus diesem Grund sollte Redundanz mit klarer Architektur, kontrolliertem Umfang und realistischen Betriebsabläufen geplant werden.
Kosten sind ein weiterer Faktor. Redundante Komponenten erhöhen den Hardware-, Lizenzierungs-, Integrations- und Wartungsaufwand. Die Entscheidung sollte jedoch auf Risiko und Dienstgewichtung basieren, nicht allein auf den Hardwarekosten. In vielen Umgebungen sind die Kosten für Ausfallzeiten weitaus höher als die Kosten für den korrekten Aufbau von Redundanz.
Tests sind unerlässlich. Ein redundantes Design, das nie getestet wird, kann falsches Vertrauen schaffen. Organisationen sollten das Failover-Verhalten, die Zeitabläufe, die Zustandserhaltung, die Alarmbehandlung und die Wiederherstellungsverfahren unter kontrollierten Bedingungen überprüfen.
Redundanz an das tatsächliche Geschäftsrisiko anpassen
Nicht jede Komponente benötigt die gleiche Redundanzstufe. Ein effektives Design beginnt mit der Identifizierung, welche Dienste wirklich kritisch sind und welche Unterbrechungsstufe akzeptabel ist. Ein Sprachserver im Kontrollraum mag eine vollständige Redundanz rechtfertigen, während ein nicht wesentliches Berichtstool dies nicht tut. Ein Backbone-Switch kann duplizierte Uplinks erfordern, während ein lokaler Drucker mit geringer Auswirkung nicht die gleiche Aufmerksamkeit benötigt.
Dieser risikobasierte Ansatz hilft Organisationen, Redundanz dort einzusetzen, wo sie den größten Nutzen bringt. Er verhindert auch Überdesign, bei dem die Komplexität ohne sinnvollen betrieblichen Nutzen erhöht wird. Das Ziel ist nicht, blind alles zu duplizieren. Das Ziel ist es, die Teile des Systems zu schützen, deren Ausfall unverhältnismäßige Folgen hätte.
Eine gute Redundanzplanung ist daher strategisch. Sie bringt die technische Architektur mit den betrieblichen Prioritäten in Einklang.
Fazit
Warum Redundanz wichtig ist
Redundanz ist wichtig, weil moderne Systeme zu wichtig sind, um vollständig von einem Pfad, einem Knoten oder einer Stromquelle abzuhängen. Ob es sich um ein Bürotelefonsystem, eine industrielle Kommunikationsplattform, ein Steuerungsnetzwerk oder einen cloudbasierten Unternehmensdienst handelt, das Risiko einer einzelnen Fehlerquelle kann den Betrieb stören, die Sicherheit verringern und die Servicequalität beeinträchtigen. Redundanz verringert dieses Risiko, indem sie die Kontinuität im Voraus vorbereitet.
Ihr praktischer Wert liegt in der verbesserten Verfügbarkeit, einer stärkeren Fehlertoleranz, einer besseren Wartungsflexibilität und einem zuverlässigeren Dienst während abnormaler Ereignisse. Gleichzeitig ist Redundanz nicht nur eine Frage der zusätzlichen Hardware. Sie erfordert eine gute Failover-Logik, Synchronisierung, Tests und Architekturdisziplin. Die effektivsten redundanten Systeme sind diejenigen, die um tatsächliche betriebliche Anforderungen herum entworfen wurden, nicht um abstrakte technische Ambitionen.
Da Unternehmen weiterhin auf immer aktive Kommunikation und digitale Infrastruktur angewiesen sind, bleibt Redundanz einer der wichtigsten Bausteine eines widerstandsfähigen Systemdesigns.
FAQ
Ist Redundanz dasselbe wie eine Sicherung?
Nein. Eine Sicherung bezieht sich normalerweise auf eine Reservekopie oder eine Wiederherstellungsressource, während Redundanz typischerweise bedeutet, dass duplizierte Live-Ressourcen in das System eingebaut sind, um den Dienst während eines Fehlers am Laufen zu halten.
Was ist der Hauptzweck von Redundanz?
Der Hauptzweck ist es, einzelne Fehlerquellen zu reduzieren und die Dienstkontinuität zu verbessern, wenn Geräte, Verbindungen, Software oder Stromquellen ausfallen.
Wo wird Redundanz häufig eingesetzt?
Sie wird häufig in Netzwerken, in SIP- und IP-Telefoniesystemen, in industriellen Steuerungsumgebungen, in Rechenzentren, auf Sicherheitsplattformen und in Notfallkommunikationssystemen eingesetzt.
Garantiert Redundanz eine hundertprozentige Betriebszeit?
Nicht immer. Redundanz kann Ausfallzeiten erheblich reduzieren, aber das tatsächliche Ergebnis hängt von der Architekturqualität, dem Failover-Design, der Synchronisierung und den Tests ab.