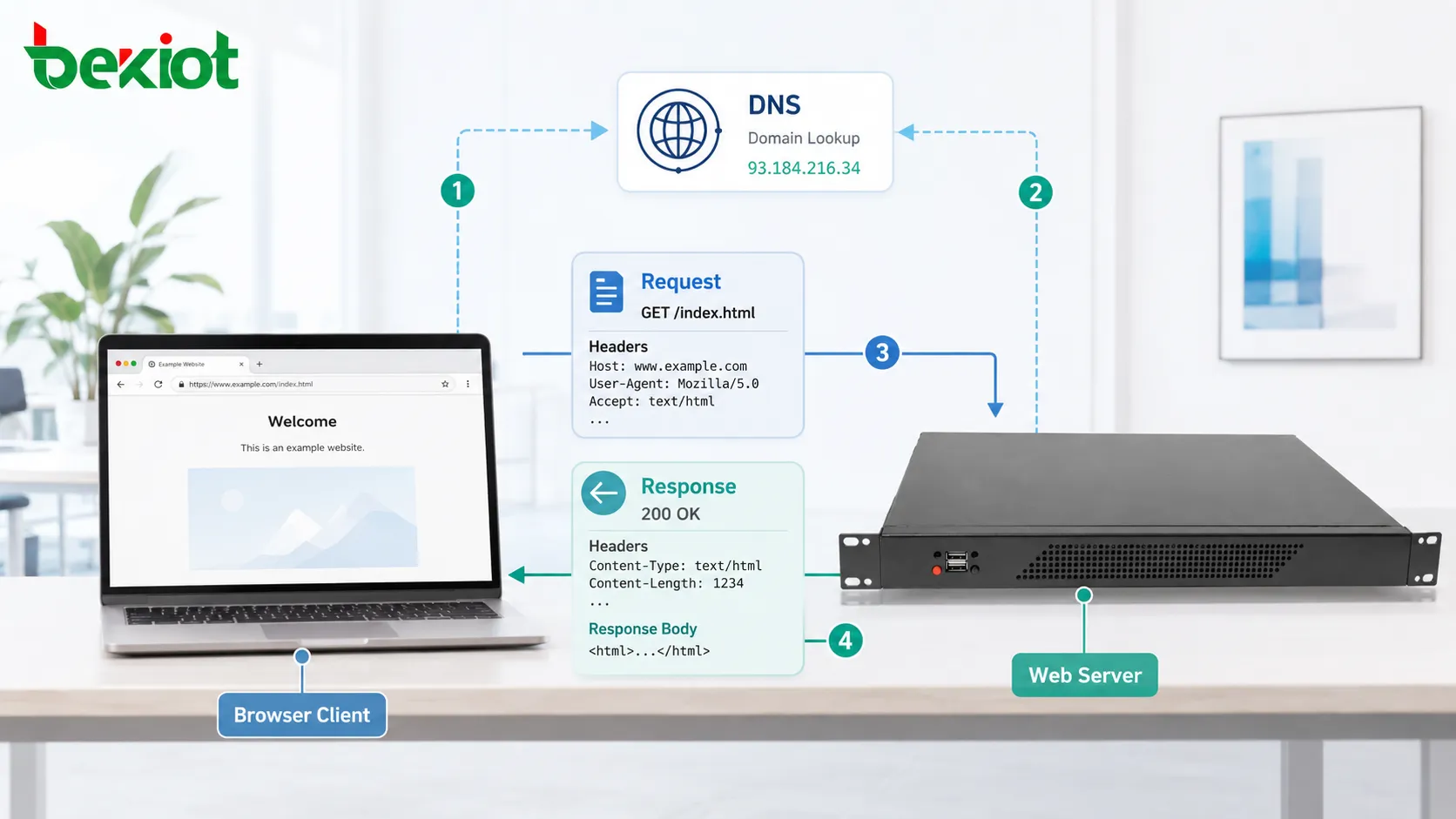
HTTP, das Hypertext Transfer Protocol, ist ein Protokoll der Anwendungsschicht, das Webseiten, API-Daten, Dateien, Formulare, Bilder, Skripte und andere Ressourcen zwischen Clients und Servern überträgt. Es bildet die Grundlage des World Wide Web und gehört zu den am häufigsten verwendeten Kommunikationsprotokollen moderner Internetsysteme.
Wenn ein Nutzer eine Website öffnet, auf einen Link klickt, ein Formular absendet, ein Bild lädt oder eine API aufruft, legt HTTP fest, wie der Client eine Ressource anfordert und wie der Server antwortet. Das Protokoll selbst entscheidet nicht, wie eine Seite aussieht oder wie sich eine Anwendung verhält. Seine Hauptaufgabe besteht darin, eine strukturierte Kommunikationsmethode zwischen zwei Seiten bereitzustellen.
Ein Gespräch aus Anfrage und Antwort
Das Grundprinzip ist einfach: Ein Client sendet eine Anfrage, und ein Server gibt eine Antwort zurück. Der Client ist meist ein Webbrowser, eine mobile App, eine Desktop-Anwendung, ein API-Werkzeug, ein Crawler oder ein eingebettetes Gerät. Der Server ist das System, das die angeforderte Ressource oder den Dienst bereitstellt.
Wenn ein Browser beispielsweise eine Website besucht, sendet er eine Anfrage nach einer bestimmten Seite. Der Server empfängt die Anfrage, prüft, welche Ressource angefordert wird, verarbeitet die dahinterliegenden Regeln und gibt eine Antwort mit Inhalt, Statusinformationen und Metadaten zurück.
Dieses Modell heißt Anfrage-Antwort-Kommunikation. Der Client startet den Austausch, und der Server antwortet. Jeder Austausch ist so strukturiert, dass beide Seiten verstehen können, was angefordert wird, wie es verarbeitet werden soll und welches Ergebnis zurückkommt.

Bevor das erste Byte übertragen wird
Bevor eine HTTP-Anfrage den Server erreichen kann, muss der Client wissen, wohin sie gesendet werden soll. Gibt ein Nutzer einen Domainnamen ein, führt der Browser normalerweise zuerst eine DNS-Auflösung durch. DNS übersetzt den für Menschen lesbaren Domainnamen in eine IP-Adresse.
Danach baut der Client eine Netzwerkverbindung zum Server auf. Bei klassischem HTTP über TCP bedeutet dies, eine TCP-Verbindung zu öffnen. Bei HTTPS wird zusätzlich ein TLS-Handshake durchgeführt, damit die Kommunikation verschlüsselt und authentifiziert werden kann.
Erst nach diesen Schritten kann die eigentliche HTTP-Nachricht ausgetauscht werden. Das Laden einer Webseite hängt also nicht nur von der Protokollnachricht selbst ab. Es hängt auch von DNS, Transportverbindung, Verschlüsselung, Serververfügbarkeit, Routing und Netzwerkleistung ab.
Aufbau einer Client-Anfrage
Eine HTTP-Anfrage enthält normalerweise eine Methode, einen Zielpfad, eine Version, Header und manchmal einen Nachrichtenkörper. Die Methode beschreibt die beabsichtigte Aktion. Der Pfad identifiziert die Ressource. Header liefern Zusatzinformationen. Der Körper überträgt bei Bedarf gesendete Daten.
Eine einfache Anfrage kann eine Startseite abrufen. Eine komplexere Anfrage kann Anmeldedaten senden, eine Datei hochladen, JSON-Daten an eine API schicken oder eine zwischengespeicherte Ressource nur dann anfordern, wenn sie geändert wurde.
Zu den gängigen Anfragemethoden gehören GET, POST, PUT, PATCH, DELETE, HEAD und OPTIONS. Jede Methode hat eine eigene Bedeutung und sollte entsprechend dem Zweck der Operation verwendet werden.
GET wird häufig zum Abrufen von Daten verwendet. POST wird oft zum Senden von Daten genutzt. PUT und PATCH dienen zum Aktualisieren von Ressourcen. DELETE fordert das Entfernen an. HEAD fragt Antwort-Header ohne vollständigen Körper ab. OPTIONS prüft unterstützte Kommunikationsoptionen.
Wie der Server die Nachricht interpretiert
Nach dem Empfang der Anfrage liest der Server Methode, Pfad, Header, Körper, Cookies, Authentifizierungsdaten und Routing-Regeln. Danach entscheidet er, was geschehen soll.
Wenn die Anfrage eine statische Datei betrifft, kann der Server die Datei direkt zurückgeben. Wenn sie eine dynamische Seite oder einen API-Endpunkt betrifft, kann der Server Anwendungscode ausführen, eine Datenbank abfragen, Benutzerrechte prüfen, Geschäftslogik ausführen oder mit einem anderen Dienst kommunizieren.
Der Server kann vor der Rückgabe auch Sicherheitsregeln anwenden. Er kann prüfen, ob die Anfrage authentifiziert ist, ob der Benutzer berechtigt ist, ob die Anfrage fehlerhaft aufgebaut ist, ob die Quelle blockiert ist oder ob Ratenlimits überschritten wurden.
Das endgültige Ergebnis wird in eine HTTP-Antwort verpackt.
Struktur und Bedeutung der Antwort
Eine HTTP-Antwort enthält normalerweise einen Statuscode, Header und einen optionalen Körper. Der Statuscode teilt dem Client mit, ob die Anfrage erfolgreich war, fehlgeschlagen ist, umgeleitet wurde oder weitere Maßnahmen erfordert.
Header beschreiben die Antwort. Sie können Inhaltstyp, Inhaltslänge, Cache-Regeln, Cookies, Serverinformationen, Kompressionsmethode, Sicherheitsrichtlinie und Umleitungsziel enthalten.
Der Körper trägt den tatsächlich zurückgegebenen Inhalt. Das kann HTML, JSON, XML, Bilddaten, Videosegmente, Textdateien, Stylesheets, Skripte oder binäre Downloads sein.
Ein Browser nutzt Antwortkörper und Header, um zu entscheiden, was angezeigt, zwischengespeichert, ausgeführt oder heruntergeladen wird und ob zusätzliche Anfragen erforderlich sind.
Statuscodes als Verkehrssignale
Statuscodes helfen Clients, das Ergebnis schnell zu verstehen. Sie sind nach Kategorien gruppiert.
| Codebereich | Allgemeine Bedeutung | Beispielhafte Verwendung |
|---|---|---|
| 100-199 | Informationsantwort | Verarbeitung fortsetzen oder Hinweis auf Protokollebene |
| 200-299 | Erfolgreiche Antwort | Seite geladen, API lieferte Daten, Datei übertragen |
| 300-399 | Umleitung | Ressource wurde verschoben oder Client soll eine andere URL anfordern |
| 400-499 | Clientseitiger Fehler | Fehlerhafte Anfrage, nicht autorisierter Zugriff, fehlende Ressource |
| 500-599 | Serverseitiger Fehler | Anwendungsfehler, Gateway-Fehler, Serverüberlastung |
Eine 200-Antwort bedeutet normalerweise, dass die Anfrage erfolgreich war. Eine 301- oder 302-Antwort bedeutet, dass der Client zu einem anderen Ort wechseln soll. Eine 404-Antwort bedeutet, dass die angeforderte Ressource nicht gefunden wurde. Eine 500-Antwort bedeutet, dass der Server ein internes Problem hatte.
Statuscodes sind nicht nur für Browser gedacht. Auch API-Clients, Überwachungssysteme, Crawler, Proxys und Load Balancer verwenden sie für Entscheidungen.
Header tragen den Kontext
Header sind Schlüssel-Wert-Felder, die Kontext für den Austausch liefern. Sie helfen beiden Seiten, Datenformat, Sprachpräferenz, Kompression, Authentifizierung, Cache-Verhalten, Cookies, Verbindungsverhalten und Sicherheitsanforderungen zu beschreiben.
Zum Beispiel kann der Accept-Header dem Server mitteilen, welche Inhaltstypen der Client bevorzugt. Der Content-Type-Header sagt dem Empfänger, welches Format der Körper verwendet. Der Authorization-Header kann Zugangsdaten oder Tokens tragen. Der Cache-Control-Header definiert das Cache-Verhalten.
Header machen das Protokoll flexibel. Dasselbe Anfrage-Antwort-Modell kann Websites, APIs, Dateidownloads, Streaming-Segmente, Authentifizierungsabläufe und Dienstintegrationen unterstützen, weil Header zusätzliche Anweisungen geben, ohne die Grundstruktur der Nachricht zu ändern.
Zustandsloses Design und Sitzungsbehandlung
HTTP wird häufig als zustandslos beschrieben. Das bedeutet, dass jede Anfrage standardmäßig unabhängig ist. Der Server merkt sich frühere Anfragen nicht automatisch als Teil des grundlegenden Protokollmodells.
Die meisten realen Websites und Anwendungen benötigen jedoch Sitzungsverhalten. Nutzer melden sich an, legen Artikel in Warenkörbe, ändern Einstellungen und setzen Abläufe über viele Anfragen hinweg fort. Dafür nutzen Systeme Cookies, Sitzungs-IDs, Tokens, lokalen Speicher, serverseitige Sitzungen und Authentifizierungs-Header.
Das Protokoll bleibt anfragebasiert, aber Anwendungen bauen darauf Kontinuität auf. Deshalb kann eine Website einen Nutzer wiedererkennen, obwohl der zugrunde liegende Austausch weiterhin aus getrennten Anfragen und Antworten besteht.
Ressourcenidentifikation mit URLs
Eine URL teilt dem Client mit, wo sich eine Ressource befindet und wie sie angefordert wird. Sie enthält meist Schema, Host, Pfad, Abfragezeichenfolge und manchmal Port oder Fragment.
Das Schema kann http oder https sein. Der Host identifiziert die Domain. Der Pfad zeigt auf eine bestimmte Ressource oder Route. Die Abfragezeichenfolge trägt zusätzliche Parameter. Das Fragment wird normalerweise clientseitig behandelt und muss nicht wie der Hauptpfad an den Server gesendet werden.
URLs machen Webressourcen adressierbar. Sie ermöglichen Browsern, APIs, Suchmaschinen, Anwendungen und Nutzern, Ressourcen in einem einheitlichen Format zu referenzieren.
Was beim Laden einer Webseite passiert
Ein einzelner Seitenaufruf kann viele HTTP-Austausche beinhalten. Die erste Anfrage kann das Haupt-HTML-Dokument abrufen. Nach dem Lesen dieses Dokuments entdeckt der Browser zusätzliche Ressourcen wie CSS-Dateien, JavaScript-Dateien, Bilder, Schriftarten, Symbole, Analyse-Skripte, API-Aufrufe und Mediendateien.
Jede Ressource kann eine weitere Anfrage erfordern. Einige Ressourcen können vom selben Server kommen, andere von CDNs, Drittanbieterdiensten, Werbesystemen, Kartenanbietern oder API-Gateways.
Der Browser kombiniert anschließend die empfangenen Ressourcen, baut die Seitenstruktur auf, wendet Stile an, führt Skripte aus und rendert die endgültige visuelle Oberfläche. Deshalb kann eine Webseite hinter einer sichtbaren Aktion Dutzende oder sogar Hunderte Protokollaustausche benötigen.
Caching und Leistungsverbesserung
Caching ermöglicht Clients, Browsern, Proxys, CDNs und Servern, zuvor heruntergeladene Ressourcen bei Bedarf wiederzuverwenden. Dadurch werden wiederholte Datenübertragungen reduziert, Latenz gesenkt, Bandbreite gespart und die Nutzererfahrung verbessert.
Das Cache-Verhalten wird durch Header wie Cache-Control, ETag, Last-Modified und Expires gesteuert. Diese Header helfen zu entscheiden, ob eine Ressource wiederverwendet, erneut validiert oder neu heruntergeladen werden muss.
Bei statischen Dateien wie Bildern, Skripten und Stylesheets kann Caching die Ladezeit stark verkürzen. Bei dynamischen Daten muss Caching vorsichtig eingesetzt werden, weil veraltete Inhalte falsche Ergebnisse verursachen können.
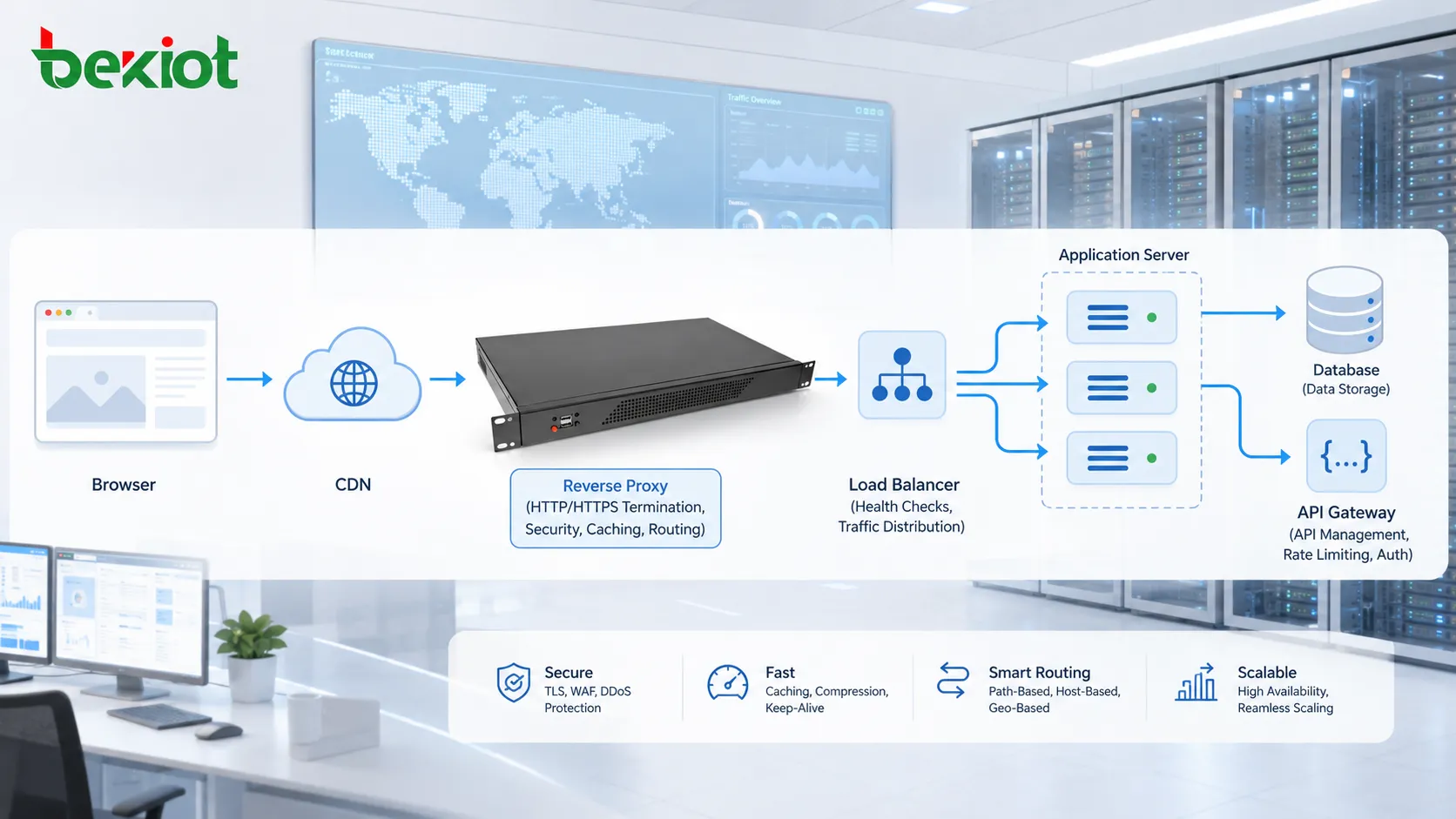
Rolle von Proxys, Gateways und CDNs
HTTP-Datenverkehr läuft nicht immer direkt vom Browser zum Ursprungsserver. Er kann über Reverse Proxys, Forward Proxys, API-Gateways, Load Balancer, Firewalls, CDN-Edge-Knoten oder Sicherheitsprüfsysteme geleitet werden.
Ein Reverse Proxy kann Anfragen im Namen von Backend-Servern entgegennehmen. Ein Load Balancer kann Datenverkehr auf mehrere Anwendungsserver verteilen. Ein CDN kann Inhalte näher bei den Nutzern zwischenspeichern. Ein API-Gateway kann Tokens prüfen, Anfrageraten begrenzen, Header umwandeln oder Verkehr zu Microservices leiten.
Diese Zwischensysteme verbessern Skalierbarkeit, Sicherheit, Leistung und Verwaltbarkeit. Sie machen die Fehlersuche aber auch komplexer, weil Fehler auf verschiedenen Ebenen auftreten können.
HTTPS und sichere Kommunikation
HTTPS ist HTTP über TLS-Verschlüsselung. Es schützt Daten während der Übertragung, indem es die Kommunikation zwischen Client und Server verschlüsselt. Außerdem hilft es, die Serveridentität durch digitale Zertifikate zu überprüfen.
Ohne Verschlüsselung könnten sensible Informationen wie Passwörter, Tokens, personenbezogene Daten und Sitzungscookies Angreifern im Netzwerk offengelegt werden. HTTPS reduziert dieses Risiko und ist zum normalen Standard für moderne Websites und APIs geworden.
Sichere Kommunikation hängt auch von korrekter Zertifikatskonfiguration, starken Protokollversionen, sicheren Cookies, richtigen Umleitungen und sicheren Servereinstellungen ab. HTTPS ist wesentlich, muss aber korrekt konfiguriert werden.
Entwicklung der Protokollversionen
HTTP hat sich weiterentwickelt, um Leistung und Effizienz zu verbessern. Frühere Versionen verwendeten einfachere Anfrageverarbeitung. Spätere Versionen führten persistente Verbindungen, Multiplexing, Header-Kompression, Server-Push-Konzepte und verbessertes Transportverhalten ein.
HTTP/1.1 verbesserte die Wiederverwendung von Verbindungen und wurde breit eingesetzt. HTTP/2 führte Multiplexing ein, sodass mehrere Anfragen und Antworten eine Verbindung effizienter teilen können. HTTP/3 nutzt QUIC über UDP, um den Verbindungsaufbau zu verbessern und unter bestimmten Netzwerkbedingungen einige Latenzprobleme zu reduzieren.
Das Funktionsprinzip bleibt Anfrage-Antwort-Kommunikation, aber Transport- und Leistungsmechanismen sind fortschrittlicher geworden.
APIs und Maschine-zu-Maschine-Kommunikation
HTTP wird nicht nur von Browsern genutzt. Es ist auch der dominierende Protokollstil für viele APIs. Mobile Apps, Webanwendungen, IoT-Plattformen, Cloud-Dienste, Zahlungssysteme, Überwachungswerkzeuge und Unternehmenssysteme tauschen häufig JSON- oder XML-Daten über HTTP aus.
Bei API-Kommunikation muss der Antwortkörper keine HTML-Seite sein. Er kann strukturierte Daten für ein anderes Programm enthalten. Statuscodes, Header, Authentifizierungs-Tokens und Anfragemethoden werden besonders wichtig für vorhersehbare Integration.
Deshalb müssen Entwickler sowohl das grundlegende Arbeitsmodell als auch die praktischen Konventionen des API-Designs verstehen.
Häufige Probleme und ihre Ursachen
Eine langsame Seite kann durch DNS-Verzögerung, große Dateien, schlechtes Caching, Serverüberlastung, Datenbanklatenz, Netzwerküberlastung, zu viele Anfragen oder ineffiziente Skripte verursacht werden.
Ein 404-Fehler kann auf eine fehlende Datei, eine falsche URL, eine gelöschte Route, eine falsche Rewrite-Regel oder einen defekten Link hinweisen. Ein 500-Fehler kann auf serverseitigen Codefehler, Datenbankproblem, Berechtigungsproblem oder falsch konfigurierten Backend-Dienst hindeuten.
Authentifizierungsfehler können abgelaufene Tokens, fehlende Cookies, falsche Zugangsdaten, blockierte Cross-Origin-Einstellungen oder falsche Header-Behandlung betreffen.
Das Verständnis des Anfrage-Antwort-Pfads hilft, den Ort des Problems zu finden.
Praktische Methode zur Fehlersuche
Beginnen Sie mit der Prüfung der URL und der Anfragemethode. Danach prüfen Sie den Statuscode. Anschließend überprüfen Sie Anfrage-Header, Antwort-Header, Cookies und Antwortkörper. Browser-Entwicklertools sind dafür hilfreich.
Bei serverseitigen Problemen prüfen Sie Zugriffsprotokolle, Fehlerprotokolle, Anwendungsprotokolle, Reverse-Proxy-Protokolle und den Status der Backend-Dienste. In verteilten Systemen helfen Trace-IDs und Request-IDs, eine Anfrage über mehrere Dienste hinweg zu verfolgen.
Bei Leistungsproblemen prüfen Sie DNS-Zeit, Verbindungszeit, TLS-Zeit, Serverantwortzeit, Downloadzeit des Inhalts, Cache-Verhalten und Ressourcengröße. Diese Details zeigen, ob das Problem netzwerk-, server- oder frontendbezogen ist.
Warum das Modell weiterhin wichtig ist
Das Funktionsprinzip von HTTP bleibt wichtig, weil fast jeder moderne digitale Dienst davon abhängt. Websites, APIs, mobile Apps, Cloud-Dashboards, Managementplattformen, Zahlungssysteme, Anmeldedienste, Überwachungssysteme und IoT-Plattformen nutzen alle dieselbe Grundidee: anfragen, verarbeiten, antworten.
Seine Stärke entsteht aus Einfachheit, Erweiterbarkeit, Lesbarkeit und breiter Kompatibilität. Es kann viele Arten von Inhalten übertragen und viele Arten von Anwendungen unterstützen, während es eine konsistente Kommunikationsstruktur beibehält.
Gleichzeitig erfordert gutes Design Aufmerksamkeit für Sicherheit, Caching, Header, Statuscodes, Fehlerbehandlung, Versionskompatibilität und Netzwerkarchitektur.
Zusammenfassung
HTTP funktioniert, indem ein Client eine strukturierte Anfrage an einen Server sendet und eine strukturierte Antwort erhält. Um dieses einfache Modell herum ergänzen moderne Websysteme DNS, TLS, Caching, Proxys, CDNs, APIs, Authentifizierung, Leistungsoptimierung und Sicherheitskontrollen.
Häufig gestellte Fragen
Ist HTTP dasselbe wie HTTPS?
Nein. HTTP definiert das Modell des Nachrichtenaustauschs, während HTTPS TLS-Verschlüsselung und zertifikatsbasierte Identitätsprüfung hinzufügt, um die Kommunikation während der Übertragung zu schützen.
Warum löst eine Webseite viele Anfragen aus?
Eine Seite hängt normalerweise von getrennten Dateien wie Bildern, Skripten, Stylesheets, Schriftarten, API-Aufrufen und Medienressourcen ab. Der Browser fordert diese Ressourcen nach dem Lesen des Hauptdokuments an.
Kann HTTP ohne Browser verwendet werden?
Ja. Mobile Apps, Server, Kommandozeilenwerkzeuge, IoT-Geräte, Überwachungssysteme und APIs können HTTP ohne traditionellen Webbrowser nutzen.
Warum geben manche API-Aufrufe Daten statt Webseiten zurück?
APIs geben häufig strukturierte Daten wie JSON oder XML zurück. Das empfangende Programm verarbeitet diese Daten, anstatt sie als Webseite anzuzeigen.
Was sollte zuerst geprüft werden, wenn eine HTTP-Anfrage fehlschlägt?
Prüfen Sie URL, Anfragemethode, Statuscode, Header, Authentifizierungsstatus, Netzwerkverbindung, Serverprotokolle und ob ein Proxy oder Gateway die Anfrage verändert.