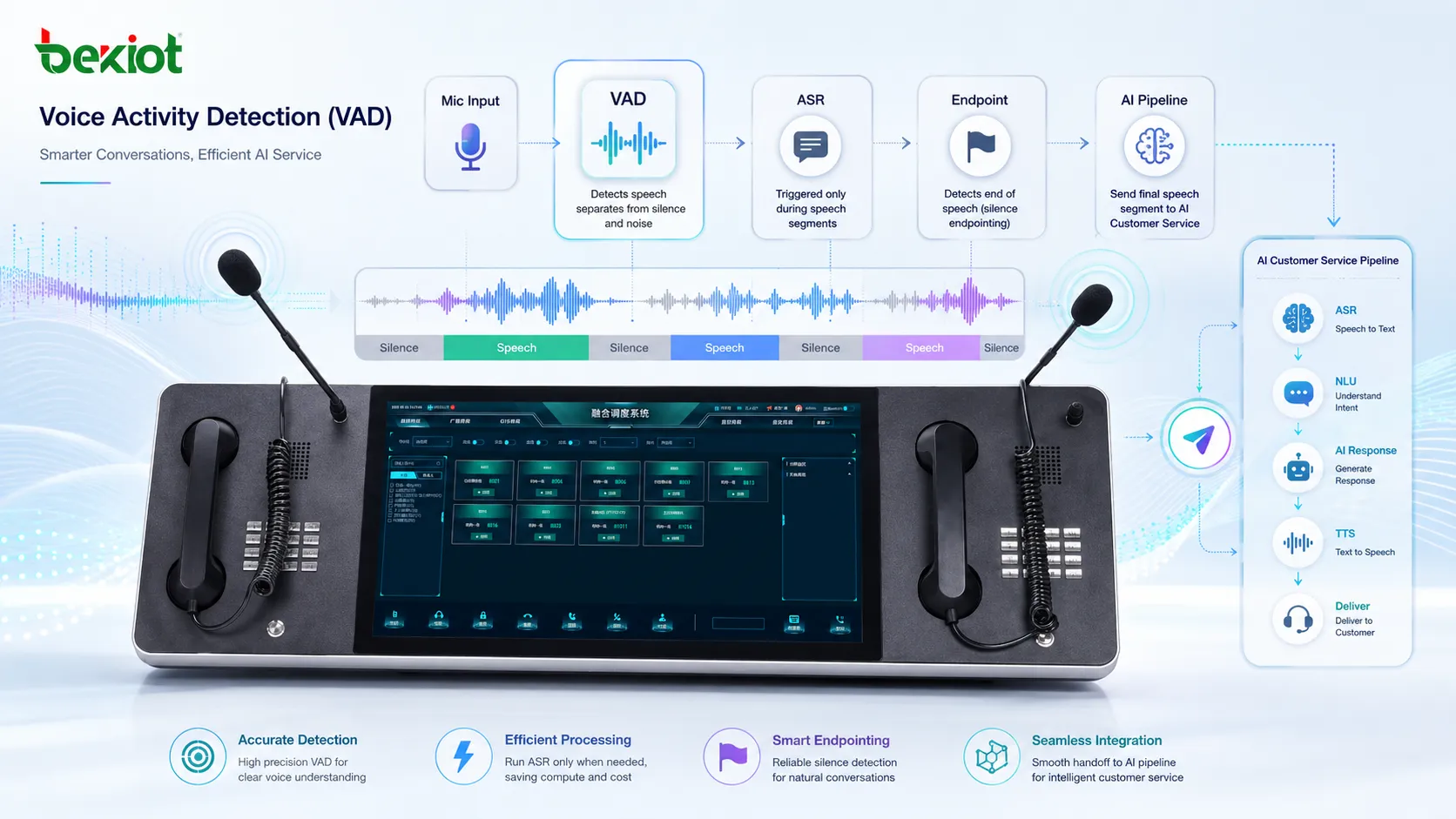
Sprachaktivitätserkennung, häufig als VAD abgekürzt, ist eine Technologie, mit der festgestellt wird, ob ein Audiosignal menschliche Sprache oder nichtsprachliche Inhalte wie Stille, Hintergrundgeräusche, Musik, Tastaturgeräusche, Atmung oder Umgebungsstörungen enthält. Sie wird breit in VoIP-Systemen, KI-Sprachassistenten, Spracherkennung, Konferenzplattformen, Gesprächsaufzeichnung, Funkgeräten, mobilen Anwendungen und eingebetteten Kommunikationsgeräten eingesetzt.
Was Sprachaktivitätserkennung in Audiosystemen bedeutet
In einem Echtzeit-Audiosystem nimmt das Mikrofon ständig Schall auf. Nicht jedes Geräusch sollte übertragen, aufgezeichnet, verarbeitet oder an eine Spracherkennungs-Engine gesendet werden. Die Sprachaktivitätserkennung hilft dem System zu entscheiden, wann eine Person tatsächlich spricht und wann der Audiostream als Stille oder Hintergrundgeräusch behandelt werden kann.
Diese Entscheidung wirkt einfach, ist technisch jedoch sehr wichtig. Ein schlechtes VAD-System kann den Anfang oder das Ende von Sprache abschneiden, zu viel Rauschen an den Server senden, Fehltrigger auslösen oder dem Nutzer das Gefühl geben, das System reagiere langsam. Ein gut entwickeltes VAD-System verbessert die Sprachqualität, spart Bandbreite, senkt Rechenkosten und macht Sprachinteraktion natürlicher.

Wie Sprachaktivitätserkennung funktioniert
Analyse des Audiosignals
VAD beginnt mit der Analyse kurzer Audioframes. Diese Frames werden normalerweise in Millisekunden gemessen, sodass das System schnell entscheiden kann, ohne auf eine lange Aufnahme zu warten. Jeder Frame kann nach Energiepegel, Frequenzverteilung, Signaländerung, Nulldurchgangsrate, spektralen Merkmalen oder einer auf maschinellem Lernen basierenden Sprachwahrscheinlichkeit geprüft werden.
Traditionelle VAD-Verfahren beruhen oft auf akustischen Schwellenwerten. Liegt die Audioenergie beispielsweise über dem Rauschboden, kann das System sie als Sprache bewerten. Moderne Systeme nutzen neuronale Netze oder statistische Modelle, um Sprache und Rauschen genauer zu unterscheiden, besonders in Umgebungen mit Lüftern, Verkehr, Maschinen, Musik oder mehreren Sprechern.
Entscheidung zwischen Sprache und Stille
Nach der Analyse des Audioframes trifft die VAD-Engine eine Entscheidung: Sprache, Stille oder manchmal unsicher. In praktischen Systemen wird diese Entscheidung meist zeitlich geglättet. Ohne Glättung kann das Ergebnis zu schnell zwischen Sprache und Stille wechseln und unnatürliche Audiounterbrechungen verursachen.
Die meisten realen Installationen verwenden Parameter wie Startschwelle, Endschwelle, minimale Sprachdauer, Stille-Zeitlimit und Nachlaufzeit. Nachlaufzeit bedeutet, dass das System den Ton nach dem Abfallen der erkannten Sprachenergie noch kurz als Sprache behandelt. Dadurch wird verhindert, dass die letzte Silbe eines Satzes zu früh abgeschnitten wird.
Integration mit Sprachverarbeitung
VAD wird selten allein genutzt. Es arbeitet häufig mit Rauschunterdrückung, Echokompensation, automatischer Verstärkungsregelung, Spracherkennung, Wake-Word-Erkennung, Gesprächsaufzeichnung, Audiokompression und Echtzeit-Kommunikationsprotokollen zusammen. In einem KI-Sprachsystem kann VAD entscheiden, wann Audio an ASR gestreamt wird und wann das Zuhören für den Satz des Nutzers endet.
In einem VoIP- oder Konferenzsystem kann VAD die Paketübertragung während Stille reduzieren. In Aufzeichnungssystemen kann es aktive Sprachsegmente markieren, damit Wiedergabe und Suche einfacher werden. In eingebetteten Geräten kann es CPU-Nutzung und Batterieverbrauch senken, indem unnötige Audioverarbeitung vermieden wird.
Hauptmerkmale der Sprachaktivitätserkennung
Echtzeit-Spracherkennung
Das wichtigste Merkmal von VAD ist die Erkennung in Echtzeit. Das System muss Sprache schnell genug erkennen, damit natürliche Kommunikation möglich bleibt. Ist die Verzögerung zu groß, erleben Nutzer langsame Antworten, unterbrochene Gespräche oder verzögerte KI-Interaktion.
Echtzeit-VAD ist besonders wichtig für Sprachassistenten, KI-Kundendienst, Dispatch-Kommunikation, Push-to-Talk-Systeme, Videokonferenzen und freihändige Gegensprechanlagen. Diese Szenarien benötigen eine schnelle Erkennung des Sprachbeginns und eine stabile Stilleerkennung am Ende einer Äußerung.
Robustheit gegen Geräusche
Reale Audioumgebungen sind selten ruhig. Ein VAD-System muss möglicherweise in Büros, Fabriken, Fahrzeugen, Straßen, Krankenhäusern, Schulen, Lagerhallen, Callcentern, Leitstellen oder Außenbereichen funktionieren. Hintergrundgeräusche erschweren die Spracherkennung, besonders wenn sich der Geräuschpegel im Zeitverlauf ändert.
Ein geräuschrobustes VAD kann sich an wechselnde Klangbedingungen anpassen und Fehltrigger reduzieren. Es sollte beispielsweise Tastaturtippen, Klimaanlagen, kurze Schläge oder entfernte Gespräche nicht als Stimme des Hauptsprechers behandeln. Das erhöht die Genauigkeit und reduziert unnötige Audioübertragung.
| VAD-Fähigkeit | Funktion | Warum sie wichtig ist |
|---|---|---|
| Erkennung des Sprachbeginns | Erkennt, wann ein Nutzer zu sprechen beginnt | Hilft Systemen, schnell zu reagieren und die ersten Wörter nicht zu verlieren |
| Stillebasierte Endpunkterkennung | Erkennt, wann Sprache beendet ist | Ermöglicht ASR, Aufzeichnung oder KI-Logik, zum richtigen Zeitpunkt zu stoppen |
| Geräuschfilterung | Reduziert falsche Erkennung durch Hintergrundgeräusche | Verbessert die Genauigkeit in realen Umgebungen |
| Nachlaufsteuerung | Hält den Sprachzustand kurz nach Signalabfall aktiv | Verhindert, dass Wort- oder Satzenden abgeschnitten werden |
| Framebasierte Analyse | Verarbeitet kurze Audiosegmente kontinuierlich | Unterstützt Echtzeitentscheidungen mit niedriger Latenz |
Konfigurierbare Empfindlichkeit
Verschiedene Anwendungen benötigen unterschiedliche VAD-Empfindlichkeit. Ein Sprachassistent in einem ruhigen Büro kann relativ empfindlich eingestellt sein, während eine industrielle Gegensprechanlage stärkere Filterung benötigt, um falsche Aktivierungen durch Maschinen zu vermeiden. Die Empfindlichkeitsabstimmung hilft, verpasste Sprache und Fehltrigger auszubalancieren.
Übliche Einstellungen umfassen Audioenergieschwelle, minimale Sprachlänge, maximale Stilledauer, End-of-Speech-Verzögerung, Anpassung an den Rauschboden und Konfidenzwert. Diese Werte sollten nach Mikrofonabstand, Hintergrundgeräusch, Sprechstil und Systemanforderung angepasst werden.
Warum Sprachaktivitätserkennung wichtig ist
Bessere Nutzererfahrung
Bei Sprachinteraktion ist Timing entscheidend. Hört das System zu spät zu, kann es das erste Wort verpassen. Stoppt es zu früh, kann es den Nutzer abschneiden. Wartet es nach dem Ende zu lange, wirkt das System langsam. VAD sorgt für einen flüssigeren Sprecherwechsel zwischen Mensch und Maschine.
Das ist besonders wichtig für KI-Kundendienst, intelligente Assistenten, Sprachsuche, Diktierwerkzeuge und freihändige Steuerung. Nutzer erwarten, dass das System erkennt, wann sie sprechen, ohne dass sie Tasten drücken oder Aufnahmen manuell starten und stoppen müssen.
Geringere Bandbreite und niedrigere Verarbeitungskosten
Audioübertragung und -verarbeitung verbrauchen Netzwerkbandbreite, Serverressourcen und Geräteleistung. Wenn nur sprachaktive Segmente gesendet oder verarbeitet werden, reduziert VAD unnötige Last. Das ist nützlich für große Sprachplattformen, Cloud-ASR-Dienste, Konferenzsysteme und mobile Anwendungen.
In Edge-Geräten kann VAD auch den Stromverbrauch senken. Das Gerät kann aufwendige Verarbeitungsmodule inaktiv halten, bis Sprache erkannt wird. Das ist wertvoll für batteriebetriebene Produkte und eingebettete Sprachterminals.
Sauberere Aufzeichnungen und einfachere Prüfung
In Aufzeichnungssystemen hilft VAD, nützliche Sprache von langen Stillephasen zu trennen. Audioarchive lassen sich leichter prüfen und Speicher wird gespart. In Callcentern, Meetings, Interviews, Leitstellen und Compliance-Aufzeichnungen verbessert Sprachsegmentierung Suche und Wiedergabe.
Manche Systeme verwenden VAD-Markierungen, um aktive Sprachbereiche auf einer Zeitachse hervorzuheben. Prüfer können direkt zu Sprachsegmenten springen, statt lange Stilleintervalle anzuhören.
Typische Anwendungen
Automatische Spracherkennung
ASR-Systeme verwenden VAD, um zu entscheiden, welcher Teil eines Audiostreams als Sprache erkannt werden soll. Ohne VAD erhält die ASR-Engine zu viel Stille oder Rauschen, was Verarbeitungskosten erhöht und die Erkennungsstabilität reduziert.
In dialogorientierter KI wird VAD auch zur Endpunkterkennung eingesetzt. Wenn das System erkennt, dass der Nutzer aufgehört hat zu sprechen, kann es die vollständige Äußerung an das Sprachmodell oder die Dialog-Engine senden. Gutes Endpointing macht die Unterhaltung schneller und natürlicher.
VoIP und Videokonferenzen
VoIP-Telefone, Softphones, Konferenzplattformen und WebRTC-Anwendungen können VAD nutzen, um Audioübertragung zu optimieren. Während Stille kann das System das Senden von Paketen reduzieren oder den Stream als inaktiv markieren. Das senkt die Netzwerknutzung, besonders in großen Meetings oder Umgebungen mit geringer Bandbreite.
VAD kann außerdem die Erkennung des aktiven Sprechers in Videokonferenzen unterstützen. Wenn das System weiß, wer spricht, kann es den Sprecher hervorheben, das Layout anpassen oder die Audiomischung verbessern.
Callcenter und Qualitätsüberwachung
Callcenter nutzen VAD, um Sprachmuster von Agenten und Kunden zu analysieren. Es kann Stillephasen, Unterbrechungen, lange Pausen, Übersprechen und Antwortverzögerungen erkennen. Diese Erkenntnisse unterstützen Qualitätsprüfung, Skriptoptimierung und Mitarbeiterschulung.
In Kombination mit Sprachanalyse kann VAD Gespräche vor Transkription, Schlüsselworterkennung, Stimmungsanalyse oder Compliance-Prüfung segmentieren.
Funk, Gegensprechen und Push-to-Talk-Systeme
In Funk- und Gegensprechkommunikation kann VAD die Audioaktivierung steuern, Kanalrauschen reduzieren und den Freisprechbetrieb verbessern. Es kann in Dispatch-Systemen, industriellen Intercoms, Verkehrskommunikation, Sicherheitsräumen und Notfallnetzen eingesetzt werden.
Diese Umgebungen enthalten jedoch oft starke Hintergrundgeräusche. VAD-Einstellungen müssen sorgfältig abgestimmt werden, damit Sirenen, Motoren, Alarme, Maschinen, Wind oder andere nichtsprachliche Geräusche keine Fehlaktivierung verursachen.
Überlegungen zur Bereitstellung
Mikrofonqualität und Platzierung
Die VAD-Leistung hängt stark von der Qualität des Audioeingangs ab. Selbst ein guter Algorithmus kann schlecht arbeiten, wenn das Mikrofon zu weit vom Sprecher entfernt ist, Wind ausgesetzt ist, nahe an einer Lärmquelle steht oder von Echo beeinflusst wird. Mikrofonwahl und -positionierung sollten Teil des VAD-Designs sein.
Richtmikrofone, akustische Abschirmung, Echokompensation und Rauschunterdrückung können die Erkennungsqualität verbessern. In Konferenzräumen und Industrieanlagen kann das Mikrofonlayout genauso wichtig sein wie die Softwarekonfiguration.
Latenz und Endpunkt-Timing
Niedrige Latenz ist wichtig, aber zu aggressives Abschneiden kann die Nutzererfahrung beschädigen. Systeme müssen schnelle Reaktion und vollständige Spracherfassung ausbalancieren. Ein KI-Assistent braucht vielleicht ein kurzes Stille-Zeitlimit, während Diktiersoftware längere Pausen zulassen muss.
Das Endpunkt-Timing sollte zur Anwendung passen. Ein Sprachbefehl, ein Kundendienstgespräch, ein Meeting-Transkript und eine Funkmeldung im Dispatch können jeweils andere Stilledauern benötigen.
Tests unter realen akustischen Bedingungen
VAD sollte mit realistischem Audio getestet werden, nicht nur mit sauberen Laboraufnahmen. Feldtests sollten verschiedene Sprecher, Akzente, Sprechgeschwindigkeiten, Mikrofonabstände, Hintergrundgeräuschpegel, Echobedingungen und Netzwerkzustände enthalten.
Tests sollten außerdem Randfälle wie kurze Antworten, geflüsterte Sprache, überlappende Sprecher, plötzliche Geräusche, lange Pausen und Sprache nach Stille prüfen. Diese Fälle zeigen oft, ob die VAD-Konfiguration für den Produktivbetrieb geeignet ist.

Fazit
Sprachaktivitätserkennung ist eine grundlegende Technologie moderner Sprachsysteme. Sie erkennt, wann Sprache beginnt, wann sie endet und welche Teile eines Audiostreams übertragen, aufgezeichnet oder verarbeitet werden sollten. Obwohl sie im Hintergrund arbeitet, beeinflusst sie Nutzererfahrung, Bandbreiteneffizienz, ASR-Genauigkeit, Aufzeichnungsqualität und Echtzeitkommunikation direkt.
Eine erfolgreiche VAD-Bereitstellung erfordert mehr als das Aktivieren einer einzelnen Funktion. Sie muss Mikrofonqualität, akustische Umgebung, Empfindlichkeit, Latenzziele, Endpunkt-Timing, Rauschunterdrückung und Anwendungsablauf berücksichtigen. Richtig geplant und getestet macht VAD Sprachsysteme schneller, sauberer, effizienter und natürlicher nutzbar.
FAQ
Ist Sprachaktivitätserkennung dasselbe wie Wake-Word-Erkennung?
Nein. VAD erkennt, ob Sprache vorhanden ist, während Wake-Word-Erkennung nach einer bestimmten Phrase wie einem Gerätenamen oder Aktivierungsbefehl sucht. Ein System kann VAD vor der Wake-Word-Erkennung verwenden, um unnötige Verarbeitung zu reduzieren, aber beide Funktionen sind nicht identisch.
Kann VAD verstehen, was eine Person sagt?
Nein. VAD erkennt keine Wörter und keine Bedeutung. Es entscheidet nur, ob der Ton wahrscheinlich Sprache enthält. Spracherkennung oder natürliche Sprachverarbeitung ist nötig, um gesprochene Wörter in Text umzuwandeln und die Absicht des Nutzers zu verstehen.
Warum stoppt ein VAD-System manchmal, bevor der Nutzer fertig gesprochen hat?
Das passiert meist, wenn das Stille-Zeitlimit zu kurz ist, der Nutzer zwischen Wörtern pausiert, der Mikrofonpegel niedrig ist oder Hintergrundgeräusch die Erkennung instabil macht. Anpassungen von Endpunktverzögerung, Verstärkung und Nachlaufzeit können das Problem reduzieren.
Funktioniert VAD gut, wenn mehrere Personen gleichzeitig sprechen?
VAD kann erkennen, dass Sprache vorhanden ist, trennt Sprecher aber nicht automatisch. In Umgebungen mit mehreren Sprechern können Sprecherdiarisierung, Beamforming oder Audioquellentrennung erforderlich sein, um zu erkennen, wer spricht.
Sollte VAD auf dem Gerät oder in der Cloud laufen?
Beide Optionen sind möglich. Gerätebasierte VAD kann Bandbreite reduzieren, Datenschutz verbessern und Cloud-Verarbeitungskosten senken. Cloudbasierte VAD kann stärkere Modelle und einfachere Updates bieten. Die beste Wahl hängt von Latenz, Datenschutz, Hardwarefähigkeit und Systemarchitektur ab.