

Stellen Sie sich einen entfernten Standort vor, der die Verbindung zur zentralen Plattform verliert, während Bediener weiterhin miteinander telefonieren, Notfallkontakte erreichen und die wesentliche Kommunikation aufrechterhalten müssen.
Genau hier wird lokale Ausfallsicherheit wertvoll. Sie ist nicht für ideale Netzbedingungen gedacht, sondern für den Moment, in dem der Hauptpfad unterbrochen ist, die Weitverkehrsverbindung instabil wird, der zentrale Server nicht erreichbar ist oder der Cloud-Dienst vom Standort aus nicht genutzt werden kann.
Wesentliche Kommunikation während der Netzisolation aktiv halten
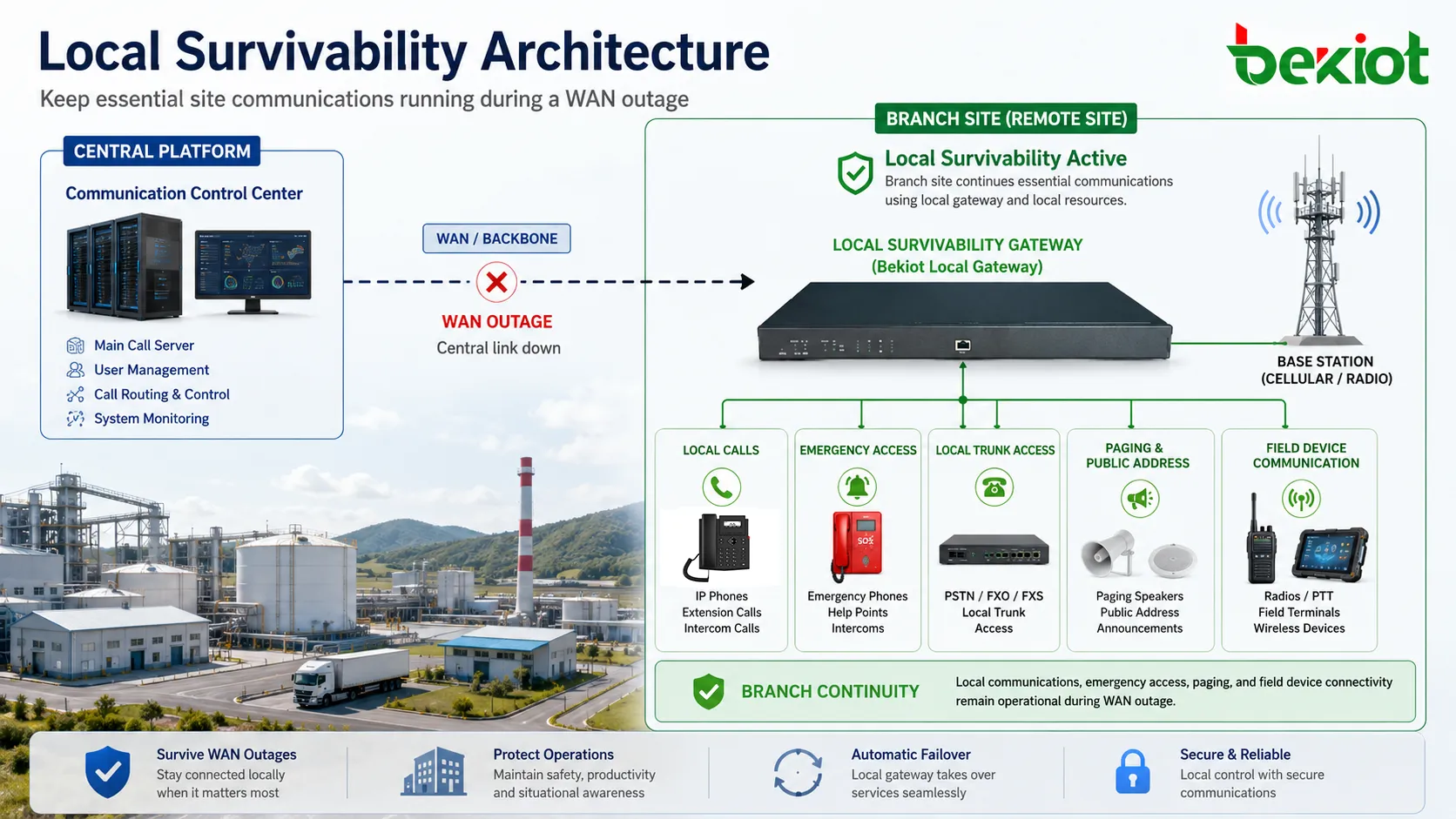
Lokale Ausfallsicherheit bezeichnet die Fähigkeit einer Filiale, Feldstation, Industrieanlage oder eines entfernten Kommunikationsknotens, Kernservices weiterzuführen, auch wenn die Verbindung zum zentralen System unterbrochen ist. In Kommunikationsnetzen bedeutet dies meist, dass lokale Nutzer weiterhin untereinander telefonieren, vordefinierte Notrufnummern erreichen, lokale Amtsleitungen oder Trunks nutzen und kritische Sprachdienste aufrechterhalten können, ohne auf die Wiederherstellung der zentralen Plattform zu warten.
Der praktische Vorteil liegt in der Kontinuität. Viele verteilte Systeme hängen für Registrierung, Routing, Richtliniensteuerung, Aufzeichnung oder Benutzerverwaltung von zentralen Servern ab. Dieses zentrale Modell ist im Normalbetrieb effizient, erzeugt aber auch Abhängigkeit. Fällt die WAN-Verbindung aus, verlieren Geräte am entfernten Standort möglicherweise den Zugriff auf den Haupt-Callserver, die Cloud-PBX, die Dispatch-Plattform oder die Kommunikationsleitstelle. Ohne Ausfallsicherheit kann der Standort betrieblich isoliert werden.
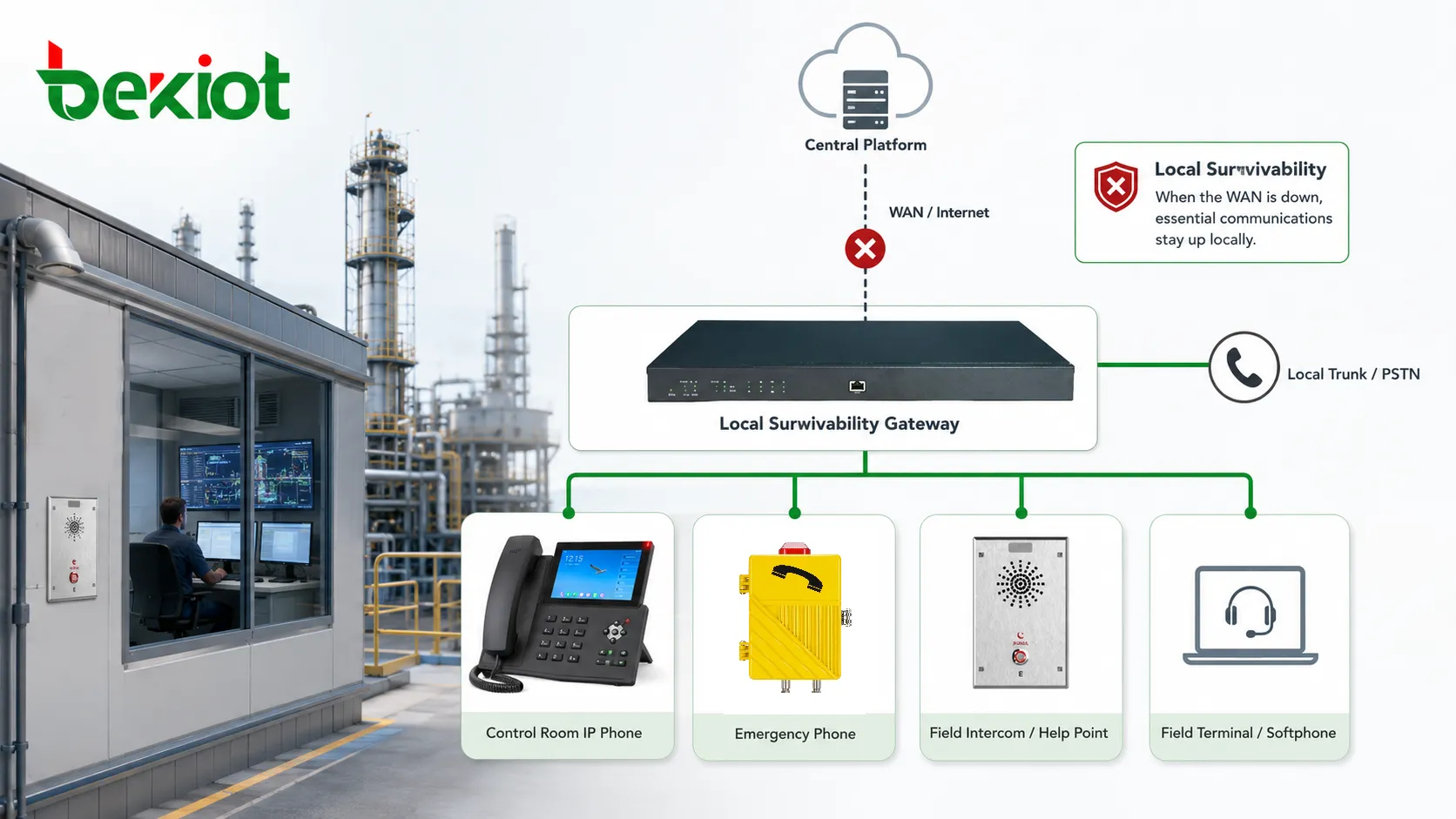
Mit lokaler Ausfallsicherheit kann ein lokales Gateway, ein Server, ein Controller oder ein eingebetteter Dienstknoten vorübergehend ausgewählte Kommunikationsfunktionen übernehmen. Er ersetzt die zentrale Plattform nicht zwingend vollständig. Stattdessen bewahrt er die für den lokalen Betrieb wichtigsten Dienste: interne Anrufe, Notfallkommunikation, lokales Routing, Failover-Trunks, Registrierungsrückfall für Geräte und teilweise eingeschränkte Dispatch- oder Durchsagefunktionen.
Diese Fähigkeit ist besonders wichtig in Industrieanlagen, Verkehrsstationen, Energieeinrichtungen, Campusnetzen, Logistikparks, Minen, Tunneln, Flughäfen und öffentlichen Dienststandorten. Solche Umgebungen können Kommunikation nicht einfach stoppen, weil eine Backbone-Verbindung ausfällt. Lokale Ausfallsicherheit schafft einen kontrollierten Rückfallzustand statt eines vollständigen Dienstausfalls.
Die Abhängigkeit von einer einzigen zentralen Plattform reduzieren
Zentralisierte Kommunikationsplattformen vereinfachen die Verwaltung, können aber zu einem einzigen Abhängigkeitspunkt werden, wenn entfernte Standorte keinen lokalen Rückfall haben. In einer normalen Architektur werden Endgeräteregistrierung, Anrufrouting, Authentifizierung, Nummernumsetzung und Servicerichtlinien häufig zentral verarbeitet. Wenn jede Kommunikationsaktion über diese Plattform laufen muss, kann ein Leitungsfehler sogar einfache lokale Anrufe zwischen zwei Geräten im selben Gebäude verhindern.
Lokale Ausfallsicherheit verändert dieses Abhängigkeitsmodell. Sie ermöglicht, dass ausgewählte lokale Funktionen unter definierten Bedingungen verfügbar bleiben. Lokale Nebenstellen können sich beispielsweise an einem überlebensfähigen Gateway neu registrieren, oder das Gateway kann einen zwischengespeicherten Wählplan für lokale Anrufe behalten. Notrufnummern können über lokale Trunks geroutet werden. Sicherheitsstellen, Wartungsteams, Produktionsleitstände und Feldterminals können innerhalb des Standorts weiter kommunizieren, auch wenn der Hauptserver nicht erreichbar ist.
Das bedeutet nicht, alles zu dezentralisieren. Ein gutes Design nutzt im Normalbetrieb weiterhin zentrale Verwaltung, weil sie einheitliche Konfiguration, Überwachung, Richtlinienkontrolle und einfachere Wartung bietet. Ausfallsicherheit ergänzt einen zweiten Betriebszustand: zentraler Betrieb bei gesundem Netz und lokaler Betrieb nur bei Ausfall des zentralen Pfads.
Der Vorteil ist die Balance. Organisationen erhalten die Effizienz einer zentralen Architektur, ohne während der Netzisolation einen vollständigen Serviceverlust hinnehmen zu müssen. Das ist besonders wertvoll bei Mehrstandortinstallationen, in denen jede Filiale, Station, Anlage oder jeder Feldknoten eigene Betriebsaufgaben hat.
Notrufe aufrechterhalten, wenn die Hauptroute ausfällt
Notrufe sind einer der wichtigsten Gründe für lokale Ausfallsicherheit. In vielen Umgebungen müssen Nutzer gerade während eines Vorfalls, der auch die Netzverbindung stört, Sicherheitsdienst, Feuerwehr, medizinische Hilfe, Leitstellenpersonal oder lokale Notdienste erreichen. Hängt das Kommunikationssystem vollständig von einer zentralen Plattform ab, kann der Notruf im entscheidenden Moment ausfallen.
Ein überlebensfähiger lokaler Knoten kann Notfallrouting über lokale Nummern, analoge Leitungen, SIP-Trunks, Funk-Gateways oder vordefinierte Antwortterminals erhalten. Das konkrete Design hängt vom Standort ab, das Prinzip bleibt gleich: Notfallkommunikation braucht einen lokalen Pfad, der nicht vollständig von entfernter Infrastruktur abhängt. Das gilt besonders für abgelegene Industriestandorte, Verkehrsstationen, unterirdische Anlagen, Offshore-Plattformen und öffentliche Sicherheitsumgebungen.
Lokale Ausfallsicherheit sorgt auch für vorhersehbares Notfallverhalten. Wenn die zentrale Plattform ausgefallen ist, sollten Nutzer nicht raten müssen, welche Nummern noch funktionieren. Das System muss definieren, welche Notrufnummern verfügbar bleiben, wohin sie geleitet werden, wie Bediener alarmiert werden und ob die Rückfallroute automatisch greift. Klares Verhalten im Fehlerfall ist wertvoller als ein komplexes System, das nur im Normalbetrieb funktioniert.
Bei der Planung sollte Notfallrouting getrennt von normalen Anrufen getestet werden. Ingenieure müssen prüfen, ob Notrufe bei simuliertem WAN-Ausfall noch verbunden werden, ob Standort oder Geräteidentität bei Bedarf erhalten bleiben, ob lokale Bediener den Anruf erhalten und ob Backup-Trunks korrekt funktionieren. Ausfallsicherheit ist nur dann sinnvoll, wenn der Rückfallpfad vor einem realen Ereignis verifiziert wurde.
Lokale Abläufe in Industrie- und Außenstandorten unterstützen
Manche Standorte können den Betrieb nicht pausieren, nur weil das zentrale Netz nicht verfügbar ist. Eine Produktionslinie benötigt weiter Abstimmung zwischen Leitstand und Feldpersonal. Ein Bahnhof braucht interne Kommunikation zwischen Bahnsteig, Sicherheit und Wartung. Eine Mine benötigt Sprachkontakt zwischen unterirdischen Punkten und lokaler Aufsicht. Ein Umspannwerk muss Bediener und Techniker verbinden. Das sind lokale Arbeitsabläufe, und viele davon müssen während einer zentralen Trennung verfügbar bleiben.
Lokale Ausfallsicherheit unterstützt dies, indem Kommunikation nahe bei den Menschen und Geräten bleibt, die sie benötigen. Statt jeden Anruf über ein entferntes Rechenzentrum oder eine Cloud-Plattform zu schicken, können ausgewählte lokale Anrufe im Standort verarbeitet werden. Das reduziert die Abhängigkeit von langen Netzpfaden und gibt der Anlage eine Grundbetriebsfähigkeit unter degradierten Bedingungen.
In Industrieumgebungen ist der Wert nicht nur technische Kontinuität. Er unterstützt auch Sicherheit und Produktionsdisziplin. Bediener können Störungen melden, Wartungsteams Reparaturen koordinieren, Sicherheitskräfte mit Toren oder Patrouillen sprechen und Notruftelefone lokale Reaktionsstellen erreichen. Der Standort arbeitet eventuell reduziert, wird aber nicht stumm.
Dies ist besonders nützlich, wenn die WAN-Reparatur Zeit braucht. Abgelegene Standorte, Außenschränke, unterirdische Trassen und gemietete Leitungen werden nicht immer sofort wiederhergestellt. Eine lokale Ausfallsicherheitsschicht verschafft Reparaturteams Zeit und hält die wesentliche interne Koordination aufrecht.
Resilienz verbessern, ohne das gesamte Netz zu verkomplizieren
Resilienz wird häufig mit vollständiger Redundanz verbunden: doppelte Server, doppelte Leitungen, Ersatzrechenzentren, mehrere Carrier und parallele Systeme. Solche Designs können für große oder geschäftskritische Netze notwendig sein, sind aber teuer und komplex. Lokale Ausfallsicherheit bietet eine fokussierte Methode, indem sie die wichtigsten standortbezogenen Kommunikationsfunktionen schützt, ohne die gesamte zentrale Plattform an jedem Standort zu duplizieren.
Das macht sie attraktiv für verteilte Organisationen. Eine Filiale benötigt nicht immer einen vollständigen Kommunikationsserver mit allen erweiterten Funktionen. Eine Station oder Anlage braucht nicht zwingend eine komplette Plattformkopie. Benötigt werden grundlegende Anrufe, Notfallrouting und lokaler Servicezugang während der Trennung. Genau darauf zielt Ausfallsicherheit.
Die Architektur kann dem Risiko angepasst werden. Eine Filiale mit geringem Risiko braucht vielleicht nur lokale Notrufe und internen Nebenstellenrückfall. Eine kritische Industrieanlage kann lokale Registrierung, lokale Trunks, Notruftelefone, Paging-Zugang und Konsolenrückfall benötigen. Ein Verkehrsnetz kann stationsebene Kontinuität und eine kontrollierte Rückkehr zur zentralen Leitstelle erfordern.
Wenn die Tiefe der Ausfallsicherheit an die Bedeutung des Standorts angepasst wird, verbessern Organisationen ihre Resilienz ohne überall überdimensionierte Infrastruktur aufzubauen. Ziel ist nicht vollständige Unabhängigkeit jedes Standorts, sondern der Erhalt der wirklich benötigten Kommunikationsfunktionen unter abnormalen Netzbedingungen.
Die Wiederherstellungszeit nach Unterbrechungen verkürzen
Lokale Ausfallsicherheit kann die betrieblichen Auswirkungen von Ausfällen reduzieren, weil Dienste während des Fehlers nicht vollständig zusammenbrechen. Wenn der zentrale Pfad wiederhergestellt ist, kann das System vom lokalen Rückfall in den zentralisierten Betrieb zurückkehren. Dieser Übergang kann automatisch oder gesteuert erfolgen, abhängig von Plattformdesign und Projektanforderungen.
Ohne Ausfallsicherheit kann ein WAN-Ausfall viele Folgeprobleme auslösen. Nutzer versuchen wiederholt erfolglose Anrufe, Bediener erhalten Beschwerden, Notfallrouting wird unsicher und Wartungsteams müssen erklären, warum lokale Geräte nicht kommunizieren können, obwohl sie physisch nahe beieinander stehen. Wiederherstellung bedeutet nicht nur, den Link zu reparieren, sondern auch Vertrauen und Serviceordnung zurückzubringen.
Mit Ausfallsicherheit arbeitet der Standort in einem begrenzten, aber geordneten Modus weiter. Lokale Nutzer bemerken vielleicht, dass einige zentrale Dienste fehlen, aber wesentliche Kommunikation bleibt möglich. Wenn die Hauptplattform zurückkehrt, können Registrierung, Routing und Richtlinien wieder normal synchronisiert werden. Dadurch wird der Ausfall leichter beherrschbar und weniger störend.
Wiederherstellungsplanung muss auch das Ende des Fehlers berücksichtigen. Das System sollte doppelte Registrierungen, Routing-Verwirrung, inkonsistente Nutzerzustände oder verzögerte Rückkehr vermeiden. Wartungsteams sollten sehen können, wann ein Standort in den überlebensfähigen Modus ging, welche Anrufe lokal verarbeitet wurden und wann Normalbetrieb wieder aufgenommen wurde. Diese Aufzeichnungen bestätigen das korrekte Failover-Verhalten.
Nutzererfahrung unter degradierten Bedingungen bewahren
Nutzer denken normalerweise nicht an Callserver, WAN-Routing, SIP-Registrierung oder Trunk-Fallback. Sie erwarten, dass Telefon, Notfallterminal, Intercom oder Konsole funktionieren, wenn sie gebraucht werden. Lokale Ausfallsicherheit bewahrt diese Erfahrung, indem die vertrautesten Kommunikationsaktionen verfügbar bleiben, auch wenn das größere Netz beeinträchtigt ist.
Ein Nutzer kann zum Beispiel weiterhin eine lokale Nebenstelle wählen, den Sicherheitsplatz erreichen, den Kontrollraum kontaktieren oder einen Notrufpunkt auslösen. Das System befindet sich vielleicht im Rückfallmodus, aber die Erfahrung bleibt für kritische Aufgaben nah genug am Normalzustand. Das reduziert Verwirrung und verhindert, dass Menschen offizielle Verfahren zugunsten informeller Umwege verlassen.
Die Nutzererfahrung zu erhalten reduziert auch Schulungsaufwand. Wenn das Rückfallverhalten vertrauten Wahlmustern und Reaktionswegen folgt, müssen Nutzer keine separate Notkommunikationsmethode für Netzausfälle lernen. Das System sollte sich an den Fehler anpassen, nicht jeden Nutzer im Stressmoment zu anderem Verhalten zwingen.
Nicht alle Funktionen können oder sollten jedoch lokal verfügbar bleiben. Erweiterte Dienste wie zentrale Verzeichnisse, Fernaufzeichnung, standortübergreifende Konferenzen, Cloud-Voicemail oder globales Routing können während der Isolation fehlen. Ein gutes Deployment definiert klar, welche Funktionen lokal garantiert sind und welche vom zentralen System abhängen.
Failover-Regeln entwerfen, denen Bediener vertrauen können
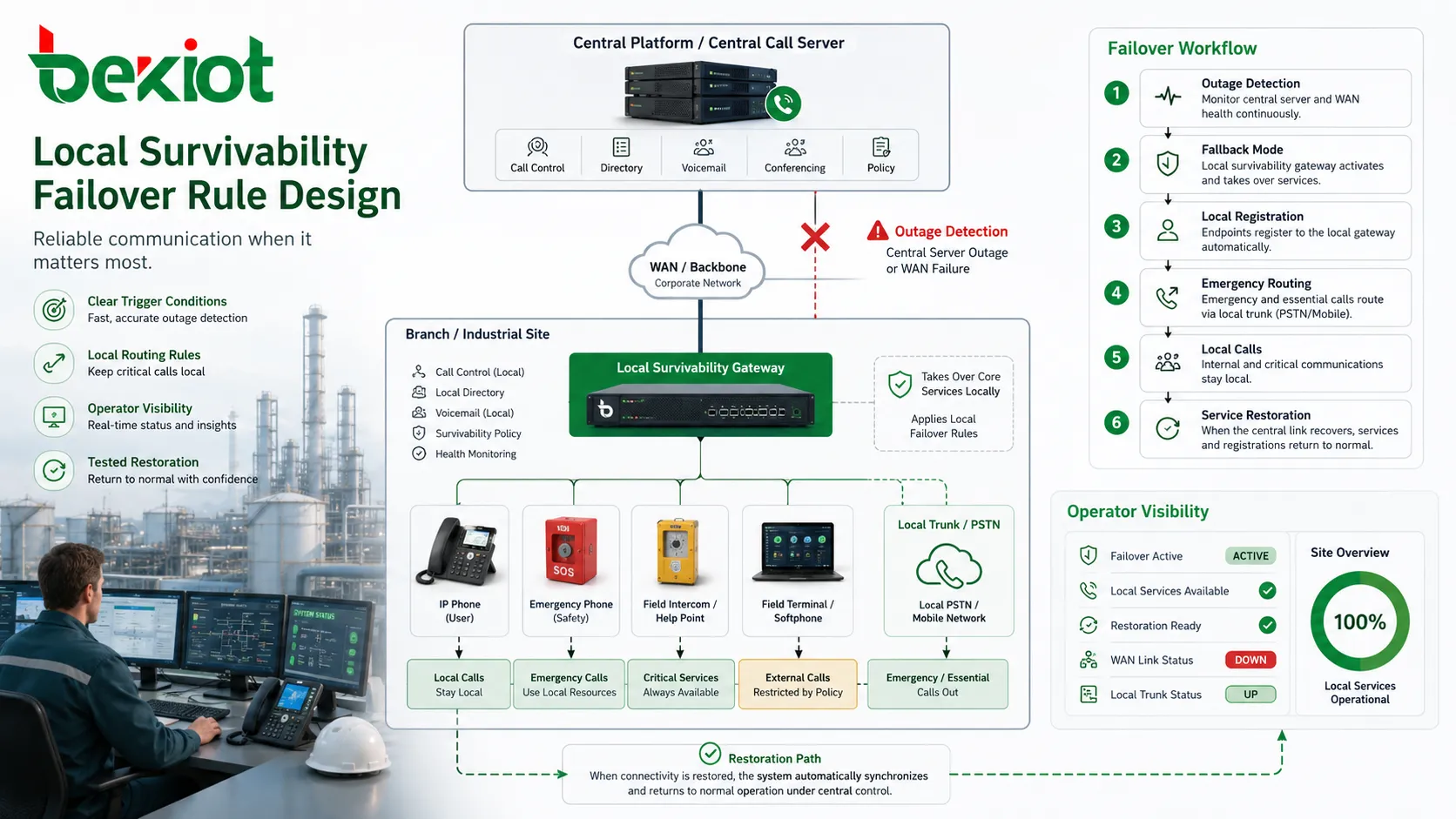
Ausfallsicherheit hängt von Regeln ab. Das System muss wissen, wann es in den Rückfallmodus wechselt, welche Dienste lokal übernommen werden, welche Nummern über lokale Ressourcen geroutet werden und wann Normalbetrieb wieder aufgenommen wird. Sind diese Regeln unklar, kann Ausfallsicherheit Verwirrung statt Stabilität erzeugen.
Auslösebedingungen sind die erste Designfrage. Ein Standort kann in den überlebensfähigen Modus wechseln, wenn er den zentralen Callserver nicht mehr erreicht, wenn SIP-Registrierung fehlschlägt, wenn WAN-Latenz einen Schwellenwert überschreitet oder wenn ein primärer Trunk ausfällt. Der Auslöser muss spezifisch genug sein, um unnötiges Failover zu vermeiden, und empfindlich genug, um vor breit wahrnehmbaren Störungen zu reagieren.
Routingregeln sind ebenso wichtig. Lokale Anrufe sollten lokal bleiben, wenn dies sinnvoll ist. Notrufe können an lokale Bediener oder Backup-Trunks gehen. Externe Anrufe können bei begrenzter lokaler Trunk-Kapazität auf wesentliche Nummern beschränkt werden. Anrufe zu anderen Standorten können blockiert, umgeleitet oder über Alternativpfade behandelt werden. Bediener müssen diese Regeln vor einem Ausfall verstehen.
Vertrauen entsteht durch Tests und Dokumentation. Wenn Mitarbeiter nicht wissen, was der überlebensfähige Modus bedeutet, halten sie das System möglicherweise für defekt, obwohl es korrekt arbeitet. Klare Statusanzeigen, Wartungsprotokolle, Bedienhinweise und regelmäßige Failover-Tests schaffen Vertrauen. Ein Ausfallsicherheitsdesign, das niemand versteht, liefert nicht seinen vollen Betriebswert.
Deployment-Planung für Filial- und Mehrstandortarchitekturen
Lokale Ausfallsicherheit muss nach der Rolle des Standorts geplant werden. Eine kleine Filiale, große Fabrik, öffentliche Verkehrsstation, ein Campusgebäude, entfernte Versorgungsanlage und ein Notfallleitpunkt brauchen nicht dasselbe Design. Der erste Schritt besteht darin zu bestimmen, welche Kommunikationsfunktionen verfügbar bleiben müssen, wenn die zentrale Plattform unerreichbar ist.
Wichtige Fragen lauten: Sollen lokale Nebenstellen weiterhin miteinander telefonieren? Gehen Notrufe an einen lokalen Platz oder an einen externen Trunk? Ist öffentlicher Netzzugang erforderlich? Werden Paging oder Durchsagen lokal benötigt? Müssen Funk- oder Intercom-Verbindungen aktiv bleiben? Wie viele gleichzeitige Anrufe sind zu unterstützen? Wie lange kann der Standort isoliert bleiben? Diese Fragen bestimmen Größe und Funktion des lokalen Ausfallsicherheitsknotens.
Auch das Netzwerkdesign muss geprüft werden. Lokale Geräte müssen den Rückfallknoten erreichen können, auch wenn das WAN ausfällt. Daher sind lokale Switching-Struktur, VLAN-Design, IP-Adressierung, DHCP-Verhalten, DNS-Abhängigkeit, Notstrom und Gateway-Position relevant. Eine Ausfallsicherheitsfunktion kann nicht arbeiten, wenn lokale Endpunkte gleichzeitig Netz oder Strom verlieren.
Bei Mehrstandortinstallationen ist Konfigurationskonsistenz wichtig. Jeder Standort kann eigene lokale Rückfallregeln haben, aber das Gesamtdesign sollte möglichst einem Standardmuster folgen. Standardvorlagen reduzieren Engineering-Fehler und erleichtern Wartung. Standortspezifische Ausnahmen können für Hochrisiko- oder Spezialstandorte ergänzt werden.
Wert für Betriebsüberwachung und Wartung
Lokale Ausfallsicherheit darf nicht als Funktion betrachtet werden, die einmal konfiguriert und dann vergessen wird. Ihr Wert hängt davon ab, dass der lokale Rückfallpfad gesund bleibt. Wartungsteams sollten lokale Gateways, Backup-Trunks, Registrierungsverhalten der Endpunkte, Stromversorgung und Softwarestände überwachen. Ein offline befindlicher oder falsch konfigurierter Ausfallsicherheitsknoten wird sonst möglicherweise erst bei einem realen Ausfall bemerkt.
Regelmäßige Tests sind wesentlich. Ingenieure sollten den Ausfall des zentralen Servers oder die WAN-Trennung kontrolliert simulieren und prüfen, ob lokale Anrufe, Notrufe und Rückfallrouten wie erwartet funktionieren. Diese Tests sollten dokumentiert werden, besonders in Umgebungen, in denen Sicherheit oder Betriebskontinuität wichtig sind.
Die Überwachung sollte auch Ereignisaufzeichnungen enthalten. Wenn ein Standort in den überlebensfähigen Modus wechselt, sollte das System Logs oder Alarme erzeugen, damit Wartungsteams verstehen, was passiert ist. Häufiges Failover kann auf WAN-Instabilität, zentrale Erreichbarkeitsprobleme, falsche Schwellenwerte oder lokale Netzprobleme hinweisen. Ausfallsicherheit schützt den Dienst, aber häufige Aktivierung zeigt ein zugrunde liegendes Problem.
Nach einem realen Ausfall helfen Aufzeichnungen bei der Bewertung. Blieben lokale Anrufe verfügbar? Wurden Notrufe korrekt geroutet? Meldeten Nutzer Verwirrung? Kehrte das System sauber zum Normalmodus zurück? Diese Fragen helfen, das Design zu verbessern und künftige Resilienz zu erhöhen.
Häufige Grenzen, die vor dem Deployment verstanden werden sollten
Lokale Ausfallsicherheit ist wertvoll, aber nicht dasselbe wie vollständige Systemduplizierung. Einige zentrale Dienste können während der Isolation nicht verfügbar sein. Je nach Architektur betrifft dies standortübergreifende Anrufe, zentrale Aufzeichnung, Cloud-Verzeichnissuche, erweiterte Konferenzen, zentrale Voicemail, globale Warteschlangen oder entfernte Administratorsteuerung. Diese Grenzen sollten vor dem Deployment erklärt werden.
Auch Kapazität kann begrenzt sein. Ein lokaler Ausfallsicherheitsknoten unterstützt vielleicht nur eine definierte Zahl von Nutzern, Anrufen, Trunks oder Funktionen. Wenn der Standort erwartet, dass alle Nutzer bei WAN-Ausfall normal arbeiten, muss das Rückfallsystem entsprechend dimensioniert werden. Wenn nur Notfall- und Kernkommunikation benötigt wird, kann ein kleineres Design reichen.
Eine weitere Grenze ist Datenkonsistenz. Während des Rückfalls können einige Anrufdaten, Gerätezustände oder Konfigurationsänderungen lokal gespeichert und später synchronisiert werden, oder sie stehen der zentralen Plattform nicht vollständig zur Verfügung. Das Projekt muss definieren, wie Daten behandelt werden und welche Informationen für Audit oder Reporting erforderlich sind.
Diese Grenzen zu verstehen schwächt den Nutzen der Ausfallsicherheit nicht. Es macht das Deployment realistischer. Die stärksten Designs definieren klar, was lokal überlebt, was vom zentralen System abhängt und wie Nutzer und Bediener im degradierten Betrieb handeln sollen.
Langfristiger Geschäftswert standortbezogener Resilienz
Der langfristige Wert lokaler Ausfallsicherheit entsteht durch geringeres Betriebsrisiko in verteilten Umgebungen. Ein einzelner Ausfall mag selten sein, kann aber hohe Kosten verursachen. Kommunikationsverlust kann Wartung verzögern, Produktion stören, Kundendienst beeinträchtigen, Notfallreaktion schwächen oder Sicherheitsrisiken erzeugen. Ausfallsicherheit verringert die Chance, dass ein Netzfehler zum vollständigen Betriebsausfall wird.
Für Organisationen mit vielen Standorten wächst der Wert weiter. Selbst wenn jeder Standort nur gelegentlich Verbindungsprobleme hat, kann das Gesamtrisiko erheblich sein. Lokale Rückfallfähigkeit schafft ein robusteres Betriebsmodell, besonders bei geografisch verteilten Standorten oder Abhängigkeit von gemieteten WAN-Verbindungen.
Ausfallsicherheit unterstützt auch Modernisierung. Organisationen können zu zentralen oder cloudbasierten Kommunikationsplattformen wechseln und dennoch lokalen Schutz für kritische Standorte behalten. Das verringert Migrationsrisiken, weil die neue Architektur nicht jede lokale Unabhängigkeit entfernt. Sie verbindet zentrale Effizienz mit standortbezogener Kontinuität.
Praktisch betrachtet ist lokale Ausfallsicherheit nicht nur eine technische Funktion. Sie ist eine Maßnahme zur Geschäftskontinuität, eine Sicherheitsebene und ein Weg, verteilte Kommunikationsarchitekturen toleranter gegenüber realen Netzproblemen zu machen.
FAQ
Ist lokale Ausfallsicherheit nur für große Organisationen erforderlich?
Nein. Sie ist für jeden Standort nützlich, an dem Kommunikation bei WAN- oder Zentralserverausfall weiterlaufen muss. Kleine Filialen, entfernte Einrichtungen, Industriestationen, Campusbereiche und Verkehrsanlagen können lokalen Rückfall benötigen, wenn der Ausfall hohe Auswirkungen hat.
Ersetzt lokale Ausfallsicherheit zentrale Redundanz?
Nein. Zentrale Redundanz schützt die Hauptplattform, während lokale Ausfallsicherheit die Kommunikation am Standort schützt, wenn dieser die zentrale Plattform nicht erreichen kann. Beide lösen unterschiedliche Teile des Resilienzproblems und können gemeinsam eingesetzt werden.
Welche Dienste bleiben im überlebensfähigen Modus normalerweise verfügbar?
Typische Dienste sind lokale Nebenstellenanrufe, Notfallrouting, Zugang zu lokalen Trunks, begrenzter Registrierungsrückfall und vordefinierte wesentliche Kommunikationspfade. Erweiterte zentrale Dienste bleiben nur verfügbar, wenn sie ausdrücklich für lokalen Betrieb ausgelegt sind.
Wie oft sollte das Survivability-Failover getestet werden?
Die Häufigkeit hängt vom Risiko ab, aber kritische Standorte sollten regelmäßig und nach größeren Netzwerk- oder Konfigurationsänderungen testen. Tests sollten lokale Anrufe, Notfallrouten, Trunkzugang, Wiederherstellung und Bedienersichtbarkeit prüfen.
Was ist der häufigste Bereitstellungsfehler?
Der häufigste Fehler ist, die Funktion zu aktivieren, ohne den vollständigen Rückfallworkflow zu entwerfen. Das Projekt muss Auslöser, lokales Routing, Notfallverhalten, Kapazität, Nutzererwartungen, Überwachung und Wiederherstellungsverfahren definieren, bevor es sich darauf verlässt.







