Disaster-Recovery-Technologie ist eine Kombination aus Backup-Systemen, replizierter Infrastruktur, Bereitschaftsumgebungen, Wiederherstellungsverfahren, Überwachungstools und Betriebsplänen, mit denen Geschäftsdienste nach einem schweren Ausfall wiederhergestellt werden. Sie hilft Organisationen bei Ereignissen wie Hardwarefehlern, Datenkorruption, Ransomware, Brand, Überschwemmung, Stromausfall, Cloud-Service-Unterbrechung, Netzwerkausfall, versehentlichem Löschen oder einer Störung auf Standortebene.
Der Zweck besteht nicht nur darin, „Daten zu speichern“. Ein vollständiges Recovery-Design muss Anwendungen, Datenbanken, Server, Identitätssysteme, Kommunikationsplattformen, Netzwerkrouten, Benutzerzugriff, Sicherheitsrichtlinien und betriebliche Abläufe wieder in einen nutzbaren Zustand bringen. Deshalb ist Disaster Recovery sowohl technische Architektur als auch Disziplin der Business Continuity.
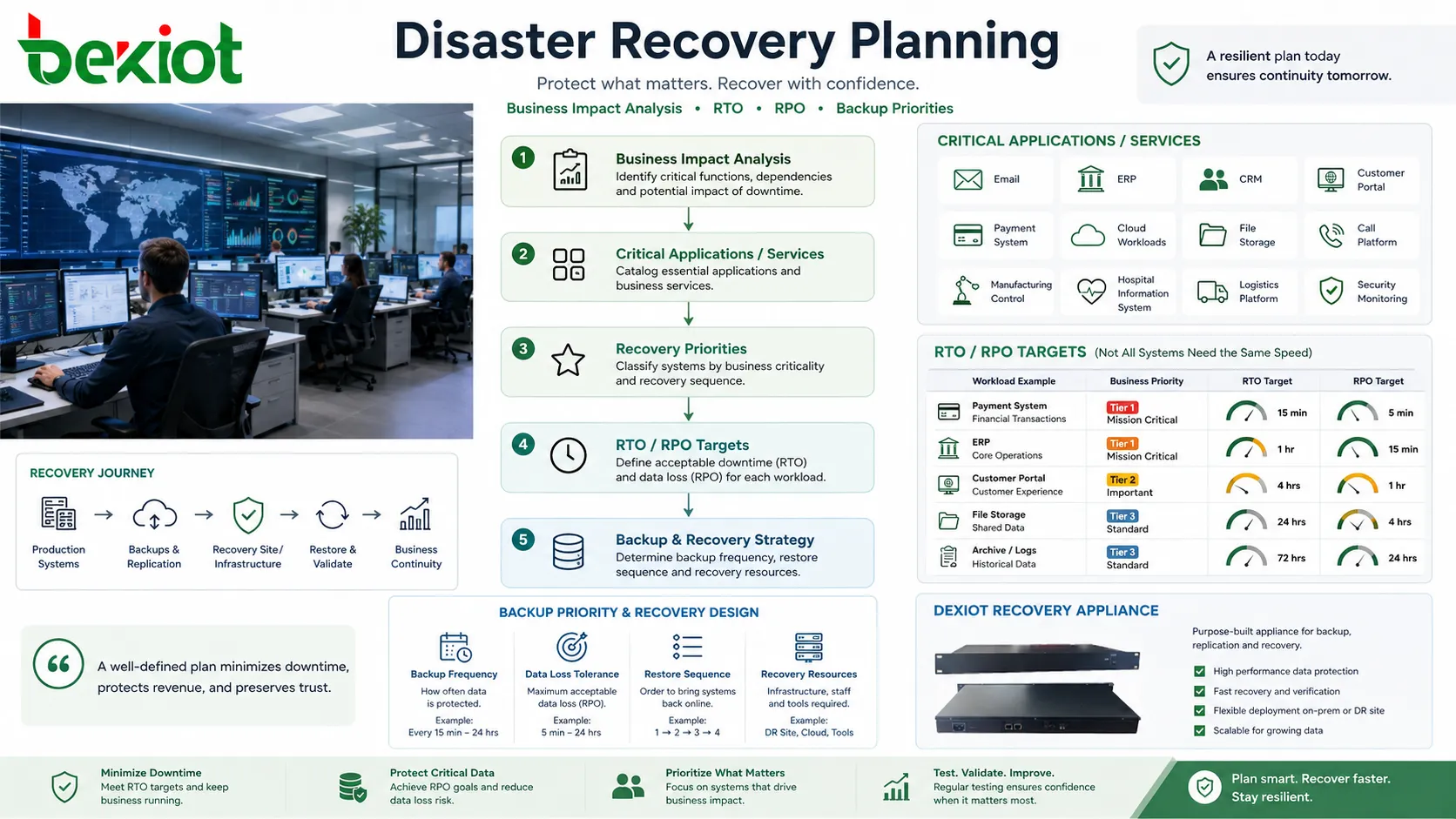
Beim geschäftlichen Einfluss beginnen
Ein zuverlässiger Wiederherstellungsplan beginnt damit, zu verstehen, welche Dienste wirklich kritisch sind. E-Mail, ERP, CRM, Kundenportale, Zahlungssysteme, Cloud-Workloads, Dateispeicher, Call-Plattformen, Fertigungssteuerungen, Krankenhausinformationssysteme, Logistikplattformen und Sicherheitsüberwachung können sehr unterschiedliche Recovery-Prioritäten haben.
Nicht jedes System benötigt dieselbe Wiederherstellungsgeschwindigkeit. Ein öffentliches Transaktionssystem muss vielleicht innerhalb weniger Minuten zurückkehren, während ein Archivsystem mehrere Stunden tolerieren kann. Alle Workloads als gleich dringend zu behandeln, erhöht Kosten und Komplexität. Wichtige Workloads zu locker zu behandeln, erhöht das Geschäftsrisiko.
Zwei Konzepte werden in der Planung häufig verwendet. Das Recovery Time Objective, kurz RTO, definiert, wie schnell ein Dienst wiederhergestellt werden soll. Das Recovery Point Objective, kurz RPO, definiert, wie viel Datenverlust akzeptabel ist, gemessen als Zeit. Ein RPO von 15 Minuten bedeutet zum Beispiel, dass die Organisation Daten bis zu einem Punkt wiederherstellen können sollte, der höchstens 15 Minuten vor dem Ausfall liegt.
Kernschichten hinter der Technologie
Datenschutzschicht
Die erste technische Schicht schützt Daten. Dazu gehören vollständige Backups, inkrementelle Backups, differentielle Backups, Snapshots, kontinuierlicher Datenschutz, unveränderliche Backups, Datenbank-Dumps, Objekt-Storage-Versionierung und externe Replikation.
Guter Datenschutz sollte mehrere Wiederherstellungspunkte enthalten. Wenn das neueste Backup beschädigte oder verschlüsselte Daten enthält, muss die Organisation möglicherweise eine ältere, saubere Version wiederherstellen. Das ist besonders wichtig bei Ransomware oder versehentlichem Löschen.
Compute-Recovery-Schicht
Daten allein reichen nicht aus. Anwendungen benötigen Server, virtuelle Maschinen, Container, Betriebssysteme, Laufzeitumgebungen, Middleware, Lizenzen und Konfigurationsdateien. Die Compute-Schicht legt fest, wo Workloads laufen, wenn die primäre Umgebung ausfällt.
Recovery-Compute kann in einem anderen Rechenzentrum, einer Cloud-Region, einem Standby-Cluster, einer virtualisierten Plattform oder einer verwalteten Recovery-Umgebung vorbereitet werden. Je besser die Umgebung vorbereitet ist, desto schneller kann die Wiederherstellung erfolgen.
Schicht für Netzwerkkontinuität
Nach der Wiederherstellung der Systeme müssen Benutzer und andere Systeme sie erreichen können. Dafür braucht es Netzwerkrouten, DNS-Updates, VPN-Zugriff, Firewall-Regeln, Load Balancer, IP-Adresspläne, Zertifikate, NAT-Richtlinien und sicheren Fernzugriff.
Netzwerk-Recovery wird oft unterschätzt. Eine Anwendung kann im Recovery-Standort laufen, aber Benutzer können sie dennoch nicht erreichen, weil DNS-Einträge, Routingtabellen, Identitätspfade oder Firewall-Regeln nicht aktualisiert wurden.
Identitäts- und Zugriffsschicht
Benutzer, Administratoren, Anwendungen und Dienstkonten benötigen nach einem Ausfall Authentifizierung und Autorisierung. Wenn Identitätsdienste nicht verfügbar sind, bleiben viele wiederhergestellte Anwendungen weiterhin unbrauchbar.
Verzeichnisdienste, MFA-Systeme, Zertifizierungsstellen, Privileged-Access-Tools, Passwort-Tresore und SSO-Plattformen sollten in die Recovery-Planung einbezogen werden. Ein Recovery-Standort ohne funktionierende Identitätskontrolle kann zu einem Sicherheits- und Betriebsproblem werden.
Schicht für operative Orchestrierung
Wiederherstellung erfordert Aktionen in der richtigen Reihenfolge. Datenbanken müssen eventuell vor Anwendungen starten. Netzwerkregeln müssen möglicherweise geändert werden, bevor Benutzer sich verbinden. Speicher muss eingehängt werden, bevor Dienste laufen. Monitoring muss bestätigen, dass das wiederhergestellte System gesund ist.
Orchestrierungstools automatisieren diese Schritte. Sie können Workloads starten, Skripte anwenden, Konfigurationen aktualisieren, Failover auslösen, Abhängigkeiten validieren und Recovery-Berichte erzeugen. Automatisierung reduziert menschliche Fehler während belastender Vorfälle.
Wie der Recovery-Prozess normalerweise abläuft
Erkennung und Bestätigung des Vorfalls
Der Prozess beginnt, wenn Monitoring-Tools, Benutzer, Administratoren oder Sicherheitssysteme ein abnormales Ereignis erkennen. Das kann ein Serverausfall, Datenbankfehler, Speicherausfall, Ransomware-Alarm, Anwendungsabsturz, Stromausfall am Standort oder ein Cloud-Regionsproblem sein.
Das Team muss bestätigen, ob das Ereignis vollständige Wiederherstellung, teilweise Restaurierung oder lokale Reparatur erfordert. Nicht jeder Fehler sollte ein vollständiges Failover auslösen. Ein kleiner Anwendungsfehler kann schneller behoben werden als die Aktivierung einer sekundären Umgebung.
Entscheidung und Aktivierung
Nach Bestätigung des Vorfalls entscheiden autorisierte Personen, ob der Recovery-Plan aktiviert wird. Die Entscheidung sollte auf Geschäftsauswirkung, erwarteter Ausfalldauer, Sicherheitsrisiko, Kundenauswirkung, Datenintegrität und der Frage beruhen, ob der primäre Standort schnell wiederhergestellt werden kann.
Klare Entscheidungsbefugnis ist wichtig. Wenn niemand weiß, wer Failover genehmigen darf, kann die Organisation während eines schweren Vorfalls wertvolle Zeit verlieren.
Datenwiederherstellung oder Replikationsumschaltung
Die Recovery-Umgebung benötigt nutzbare Daten. Wenn das Design Backups verwendet, stellt das Team Daten aus einem ausgewählten Wiederherstellungspunkt wieder her. Wenn es Replikation verwendet, kann die Standby-Kopie für den aktiven Betrieb hochgestuft werden.
Die Datenauswahl ist kritisch. Die neueste Kopie wiederherzustellen ist nicht immer richtig, wenn Korruption oder Malware diese Kopie bereits erreicht hat. Teams müssen möglicherweise den letzten sauberen Recovery-Punkt finden.
Neustart der Dienste und Reihenfolge der Abhängigkeiten
Anwendungen werden entsprechend ihren Abhängigkeiten neu gestartet. Datenbanken, Speicher, Identitätsdienste, Middleware, Anwendungsserver, Web-Frontends, APIs und Integrationen benötigen möglicherweise eine definierte Reihenfolge.
Wird diese Reihenfolge übersprungen, entstehen verwirrende Fehler. Eine wiederhergestellte Anwendung kann defekt wirken, obwohl nur die Datenbank, der Lizenzserver, die Nachrichtenwarteschlange oder der DNS-Eintrag noch nicht bereit ist.
Validierung vor der Übergabe
Bevor Benutzer zum Dienst zurückkehren, sollte das Team prüfen, ob die Recovery-Umgebung funktioniert. Dazu gehören Login-Tests, Datenkonsistenzprüfungen, Transaktionstests, Anruftests, API-Prüfungen, Berichtserstellung, Sicherheitsprüfung und Monitoring-Bestätigung.
Erst nach der Validierung sollte die Recovery-Umgebung als aktiver Produktionsdienst gelten. Eine schnelle, aber ungeprüfte Wiederherstellung kann Datenverlust, Sicherheitslücken oder Verwirrung bei Benutzern verursachen.
Disaster Recovery funktioniert am besten, wenn es nicht als einzelner Backup-Job behandelt wird, sondern als koordinierter Neustart von Daten, Systemen, Netzwerken, Identitäten, Benutzern und Geschäftsprozessen.
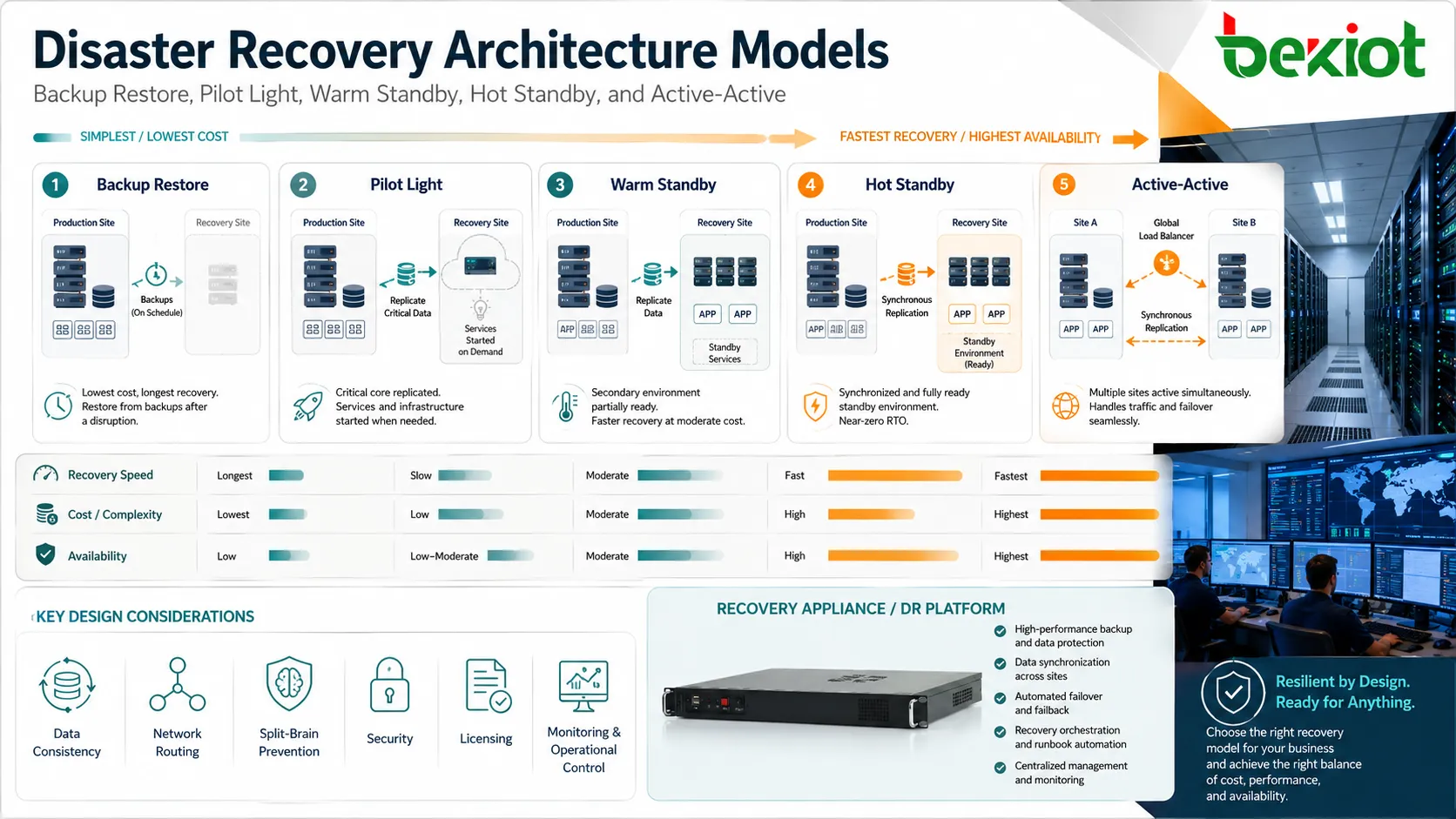
Wichtige Architekturmodelle
Backup und Wiederherstellung
Das einfachste Modell speichert Backups und stellt sie bei Bedarf wieder her. Es ist meist kostengünstiger, aber langsamer, weil Server, Anwendungen, Daten und Konfigurationen manuell neu aufgebaut oder wiederhergestellt werden müssen.
Dieses Modell eignet sich für nicht kritische Systeme, kleine Unternehmen, Archiv-Workloads oder Anwendungen mit längerer tolerierbarer Ausfallzeit. Es sollte dennoch getestet werden, weil ungetestete Backups bei einer echten Wiederherstellung scheitern können.
Pilot-Light-Umgebung
Ein Pilot-Light-Design hält eine minimale Recovery-Umgebung am Laufen. Kernkomponenten wie Datenbanken, Netzwerkbasis, Identitätsdienste oder Konfigurationsvorlagen können bereits vorhanden sein, während Anwendungsserver erst während der Wiederherstellung skaliert werden.
Dieser Ansatz balanciert Kosten und Geschwindigkeit. Er ist schneller als ein Aufbau von Grund auf, aber günstiger als der dauerhafte Betrieb einer vollständigen Duplikatumgebung.
Warm Standby
Eine Warm-Standby-Umgebung hält mehr Systeme im Voraus aktiv. Daten können regelmäßig repliziert werden, und Anwendungsdienste können installiert sowie teilweise aktiv sein. Während eines Vorfalls wird die Umgebung skaliert, hochgestuft oder neu konfiguriert, um Produktionsverkehr zu übernehmen.
Dieses Modell ist nützlich, wenn Ausfallzeit reduziert werden muss, ein vollständig aktiver zweiter Standort aber zu teuer ist.
Hot Standby oder Active-Active
Die schnellsten Designs halten eine sekundäre Umgebung kontinuierlich synchronisiert und bereit, Benutzer zu bedienen. In Active-Active-Designs können mehrere Standorte gleichzeitig Live-Traffic verarbeiten, mit Lastverteilung und Replikation über Standorte hinweg.
Diese Modelle verkürzen Ausfallzeiten, erfordern aber sorgfältige Planung. Datenkonsistenz, Netzwerk-Routing, Split-Brain-Vermeidung, Lizenzierung, Sicherheit, Monitoring und Betriebskontrolle werden komplexer.
Wichtige technische Funktionen
Automatisierte Backup-Planung
Automatische Zeitpläne reduzieren die Abhängigkeit von manuellen Backup-Vorgängen. Systeme können je nach erforderlichem RPO stündlich, täglich, wöchentlich oder kontinuierlich Backups erstellen.
Zeitpläne sollten zum Verhalten des Workloads passen. Eine Datenbank, die sich jede Minute ändert, braucht eine andere Schutzstrategie als ein statisches Dokumentenarchiv.
Unveränderliche und Offline-Kopien
Unveränderliche Backups können während eines festgelegten Zeitraums nicht geändert oder gelöscht werden. Offline- oder Air-Gap-Kopien sind von der Live-Umgebung getrennt. Diese Schutzmaßnahmen sind wichtig gegen Ransomware, Insider-Bedrohungen, versehentliches Löschen und kompromittierte Administratorkonten.
Ein Recovery-Plan, der alle Backups in derselben kompromittierten Umgebung speichert, kann genau dann scheitern, wenn er am dringendsten gebraucht wird.
Replikation und Synchronisierung
Replikation kopiert Daten aus der primären Umgebung an einen anderen Ort. Sie kann synchron sein, wenn Schreibvorgänge auf beiden Seiten bestätigt werden, bevor sie abgeschlossen sind, oder asynchron, wenn Änderungen kurz nach ihrem Auftreten kopiert werden.
Synchrone Replikation kann Datenverlust reduzieren, erfordert aber Verbindungen mit niedriger Latenz und kann die Leistung beeinflussen. Asynchrone Replikation ist über Entfernungen flexibler, kann aber jüngste Änderungen verlieren, wenn der primäre Standort plötzlich ausfällt.
Anwendungsbewusster Schutz
Anwendungsbewusster Schutz versteht den zu sichernden Workload. Datenbanken, Mail-Systeme, virtuelle Maschinen, Dateiserver und Unternehmensanwendungen können besondere Schritte benötigen, um konsistente Backups sicherzustellen.
Das einfache Kopieren von Datenbankdateien während sie sich ändern, erzeugt zum Beispiel möglicherweise keinen sauberen Wiederherstellungspunkt. Anwendungsbewusste Snapshots und Transaktionslog-Verarbeitung können die Recovery-Qualität verbessern.
Recovery-Automatisierung
Automatisierung kann virtuelle Maschinen starten, Speicher anhängen, Netzwerkregeln aktualisieren, Skripte ausführen, DNS anpassen, Dienste prüfen und Vorfallaufzeichnungen erzeugen. Sie reduziert manuelle Arbeit und macht Recovery wiederholbarer.
Manuelle Wiederherstellung kann in kleinen Umgebungen funktionieren, komplexe Systeme benötigen jedoch meist dokumentierte und automatisierte Abläufe, um Fehler unter Druck zu reduzieren.
Anwendungen in unterschiedlichen Umgebungen
Unternehmens-IT-Systeme
Unternehmen nutzen Recovery-Technologie zum Schutz von ERP, CRM, E-Mail, Identitätssystemen, Dateifreigaben, Datenbanken, Intranet-Plattformen und Geschäftsanwendungen. Ziel ist es, Kernabläufe nach schweren Vorfällen verfügbar zu halten.
Solche Umgebungen benötigen oft abgestufte Wiederherstellung. Missionskritische Anwendungen erhalten schnellere Ziele, weniger dringende Systeme verwenden kostengünstigere Schutzmethoden.
Cloud- und Hybridinfrastruktur
Cloud-Umgebungen unterstützen Snapshots, regionsübergreifende Replikation, Infrastructure as Code, verwaltete Datenbanken, Objekt-Storage-Versionierung und automatisierte Failover-Muster. Hybride Systeme können lokale Rechenzentren mit Cloud-Recovery-Ressourcen kombinieren.
Cloud-basierte Wiederherstellung kann den Bedarf an einem vollständigen zweiten Rechenzentrum reduzieren, erfordert aber weiterhin Netzwerkplanung, Sicherheitsdesign, Kostenkontrolle und regelmäßige Tests.
Industrie- und Versorgungsbetrieb
Fabriken, Kraftwerke, Wasseraufbereitungsanlagen, Öl- und Gasstandorte sowie Logistikzentren benötigen möglicherweise Recovery-Pläne für Steuerungssysteme, Historian-Systeme, Monitoring-Server, Kommunikationsplattformen und Bedienarbeitsplätze.
Diese Umgebungen müssen Sicherheit, Echtzeit-Prozesssteuerung, Legacy-Protokolle, Feldgerätezugriff und strenge Änderungssteuerung berücksichtigen. Recovery darf keine unsicheren Betriebszustände erzeugen.
Gesundheitswesen und öffentliche Dienste
Krankenhäuser, Notfallzentren, staatliche Dienste und öffentliche Einrichtungen benötigen während Störungen Zugriff auf Akten, Kommunikation, Terminplanung, Sicherheitssysteme und Betriebsdaten.
Die Planung sollte Datenschutz, Audit-Trails, Auswirkungen auf Patienten oder Bürger, Notfallverfahren und Mitarbeiterzugriff unter abnormalen Bedingungen umfassen.
Telekommunikation und Kommunikationsdienste
Kommunikationsplattformen benötigen Recovery für Anrufsteuerung, Routing, Mediendienste, Aufzeichnung, Voicemail, SIP-Trunks, Gateways, Contact-Center-Plattformen und Benutzerregistrierungsdaten.
Da Kommunikationssysteme häufig Notfallreaktion und Kundeninteraktion unterstützen, sollten Recovery-Tests echte Anrufflüsse einschließen und nicht nur den Serverstart.
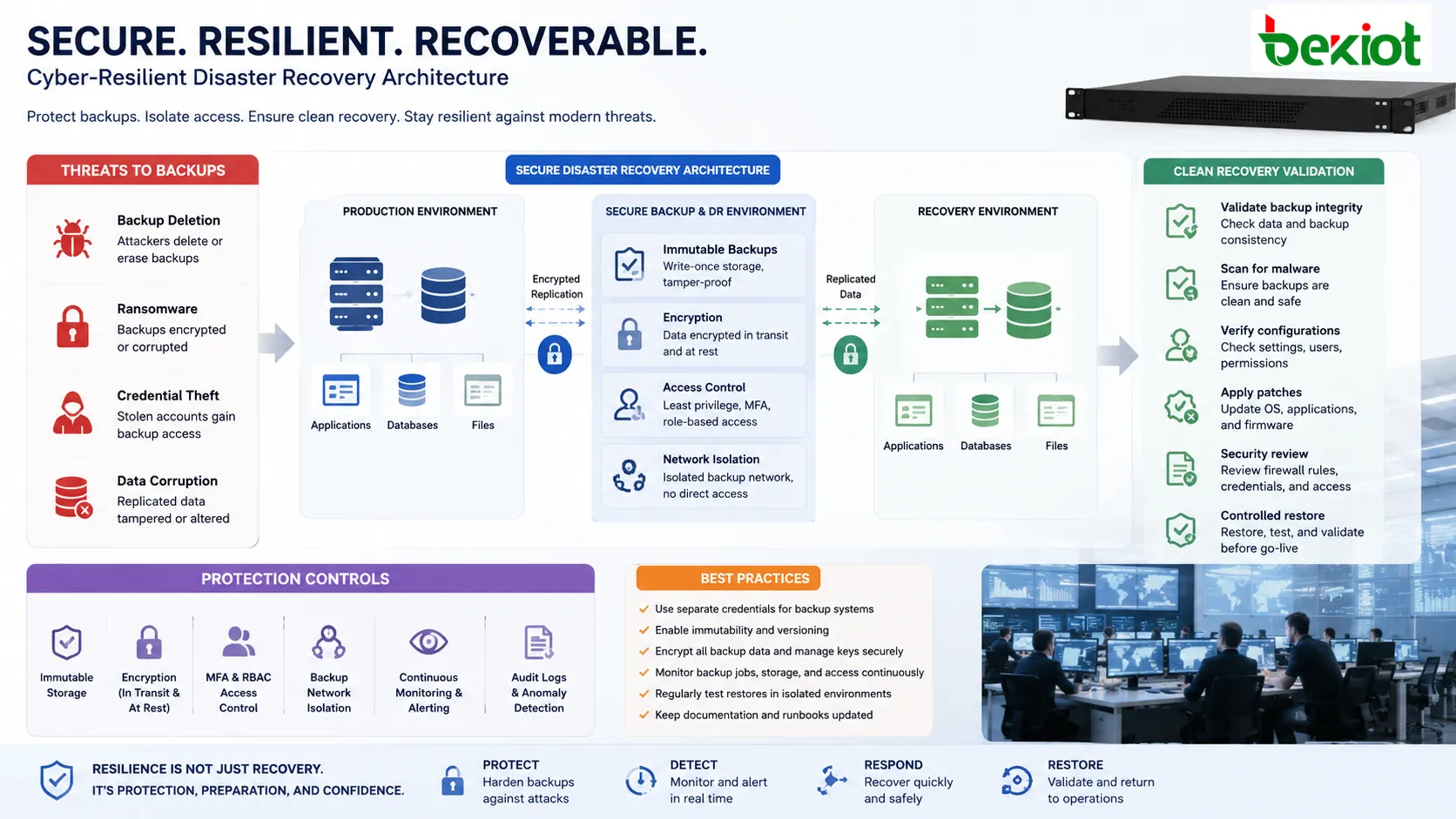
Datenintegrität und Cybersicherheit
Moderne Recovery-Planung muss annehmen, dass Cyberangriffe Backups ebenso wie Produktionssysteme angreifen können. Angreifer können Backups löschen, Backup-Repositories verschlüsseln, Zugangsdaten stehlen oder replizierte Daten beschädigen. Deshalb sind Backup-Isolierung, Zugriffskontrolle, Unveränderlichkeit, Verschlüsselung und Monitoring unverzichtbar.
Recovery-Daten sollten bei Übertragung und Speicherung geschützt werden. Verschlüsselungsschlüssel müssen sorgfältig verwaltet werden, denn ein verlorener Schlüssel kann die Wiederherstellung unmöglich machen. Backup-Repositories sollten nicht dieselben Zugangsdaten und Rechte wie normale Produktionskonten verwenden.
Sicherheitsvalidierung nach der Wiederherstellung ist ebenfalls wichtig. Die Wiederherstellung eines Systems aus einem Backup kann veraltete Software, anfällige Konfigurationen oder kompromittierte Konten zurückbringen. Teams sollten Patches, Zugangsdaten, Firewall-Regeln und Endpoint-Sicherheit prüfen, bevor Dienste wieder an Benutzer übergeben werden.
Tests und Bereitschaftsübungen
Ein nie getesteter Recovery-Plan ist nur eine Annahme. Tests bestätigen, ob Backups wiederherstellbar sind, Anwendungen korrekt starten, Benutzer sich anmelden können, Daten konsistent sind, Netzwerkrouten funktionieren und Mitarbeiter wissen, was zu tun ist.
Tests können auf verschiedenen Ebenen stattfinden. Ein Datei-Restore-Test prüft, ob einzelne Daten wiederhergestellt werden können. Ein Anwendungstest prüft, ob ein Dienst wiederhergestellt werden kann. Eine vollständige Simulation testet einen gesamten Standortausfall und den Failover-Prozess.
Übungen sollten dokumentiert werden. Das Team sollte Wiederherstellungszeit, gefundene Probleme, fehlende Zugriffe, fehlgeschlagene Skripte, veraltete Dokumentation und Korrekturmaßnahmen erfassen. Jeder Test sollte den Plan verbessern.
Häufige Schwachstellen
Backups, die nie wiederhergestellt wurden
Viele Organisationen stellen zu spät fest, dass ihre Backup-Jobs erfolgreich abgeschlossen wurden, die Daten aber nicht korrekt wiederhergestellt werden können. Ursachen können beschädigte Dateien, fehlende Abhängigkeiten, falsche Zugangsdaten, nicht unterstützte Versionen oder unvollständige Anwendungsdaten sein.
Restore-Tests sind der einzige verlässliche Weg, um zu beweisen, dass Backup-Daten nutzbar sind.
Fehlende Konfigurationsdateien
Anwendungen können von Konfigurationsdateien, Zertifikaten, Umgebungsvariablen, Routingtabellen, Firewall-Regeln, Lizenzen und Dienstkonten abhängen. Wenn diese Elemente nicht geschützt werden, können Daten wiederhergestellt sein, aber die Anwendung läuft trotzdem nicht.
Konfigurations-Backup sollte als Teil des Recovery-Umfangs behandelt werden.
Unklare Verantwortung
Während eines Vorfalls kann Unklarheit darüber, wer Entscheidungen trifft, die Wiederherstellung verlangsamen. IT, Sicherheit, Betrieb, Geschäftsleitung, Cloud-Teams und Anbieter können alle beteiligt sein.
Der Plan sollte Rollen, Genehmigungsbefugnis, Eskalationskontakte und Kommunikationskanäle definieren, bevor eine Krise entsteht.
Replikation schlechter Daten
Replikation ist nützlich, kann aber Korruption, Löschungen oder verschlüsselte Dateien an den sekundären Standort kopieren. Deshalb bleiben Point-in-Time-Recovery und unveränderliche Backups wichtig, auch wenn Replikation vorhanden ist.
Replikation verbessert die Kontinuität; sie ersetzt keine sauberen historischen Wiederherstellungspunkte.
Nicht vorbereiteter Netzwerkzugriff
Eine wiederhergestellte Anwendung ist nutzlos, wenn Benutzer sie nicht erreichen können. DNS, VPN, Firewall, Load Balancer, Zertifikat, Routing und Identitätsabhängigkeiten sollten in Recovery-Tests einbezogen werden.
Netzwerkbereitschaft entscheidet oft darüber, ob aus einer technischen Wiederherstellung ein nutzbarer Dienst wird.
Der echte Maßstab für Recovery-Technologie ist nicht, ob Daten irgendwo existieren. Entscheidend ist, ob die richtigen Personen den richtigen Dienst innerhalb des erforderlichen Zeitfensters sicher wieder aufnehmen können.
Implementierungs-Checkliste
Klassifizieren Sie Systeme nach geschäftlicher Priorität. Definieren Sie RTO und RPO für jeden Dienst, statt ein generisches Ziel für alles zu verwenden.
Wählen Sie die passende Schutzmethode. Backup-Restore, Snapshots, Replikation, Standby-Umgebungen und Active-Active-Designs erfüllen unterschiedliche Anforderungen und Kostenstufen.
Schützen Sie Kopien vor Cyberrisiken. Nutzen Sie Unveränderlichkeit, getrennte Zugangsdaten, Verschlüsselung, geringste Rechte, Backup-Monitoring und offline oder isolierte Kopien, wo es sinnvoll ist.
Dokumentieren Sie Recovery-Schritte. Enthalten sein sollten Systemabhängigkeiten, Startreihenfolge, Netzwerkänderungen, Login-Methoden, Lieferantenkontakte, Lizenzanforderungen und Validierungstests.
Testen Sie regelmäßig. Ein Recovery-Prozess sollte vor einem echten Vorfall geübt werden. Aktualisieren Sie den Plan nach Infrastrukturänderungen, Cloud-Migrationen, Anwendungsupgrades und Änderungen an Sicherheitsrichtlinien.
FAQ
Bietet Cloud-Hosting automatisch Disaster Recovery?
Nein. Cloud-Plattformen stellen nützliche Tools bereit, aber der Kunde muss Backups, Replikation, Regionen, Berechtigungen, Monitoring, Recovery-Verfahren und Tests weiterhin konfigurieren.
Wie oft sollten Recovery-Pläne getestet werden?
Die Häufigkeit hängt vom Geschäftsrisiko und der Kritikalität des Systems ab. Kritische Systeme können regelmäßige Übungen benötigen, während weniger wichtige Systeme während geplanter Reviews oder nach größeren Änderungen getestet werden können.
Kann Ransomware Backup-Systeme betreffen?
Ja. Angreifer können Backup-Repositories und Administratorzugangsdaten ins Visier nehmen. Unveränderliche Kopien, Offline-Kopien, getrennte Rechte und Monitoring helfen, dieses Risiko zu reduzieren.
Was ist der Unterschied zwischen Hochverfügbarkeit und Disaster Recovery?
Hochverfügbarkeit konzentriert sich darauf, Dienste während kleinerer Ausfälle am Laufen zu halten. Disaster Recovery konzentriert sich auf die Wiederherstellung nach größeren Störungen, einschließlich Standortausfall, Cyberangriff oder großem Datenverlust.
Was sollte nach einem echten Recovery-Ereignis überprüft werden?
Überprüfen Sie Wiederherstellungszeit, Datenverlust, fehlgeschlagene Schritte, Kommunikationslücken, Benutzerauswirkungen, Sicherheitsbefunde, Anbieterreaktion, Dokumentationsgenauigkeit und Verbesserungen, die vor dem nächsten Vorfall nötig sind.