

Dienste weiter betreiben, wenn etwas ausfällt
Failover ist ein Zuverlässigkeitsmechanismus, der den Betrieb automatisch oder manuell von einer ausgefallenen Primärkomponente auf eine Ersatzkomponente umschaltet. Es wird eingesetzt, um Anwendungen, Netzwerke, Server, Datenbanken, Kommunikationssysteme, Cloud-Dienste und industrielle Plattformen verfügbar zu halten, wenn Hardware, Software, Verbindungen oder Dienste nicht mehr funktionieren.
Einfach gesagt beantwortet Failover eine zentrale Frage: Wenn das Hauptsystem ausfällt, was übernimmt dann? Eine gut geplante Failover-Architektur reduziert Ausfallzeiten, schützt die Dienstkontinuität und hilft Organisationen, sich schneller von Fehlern, Überlastungen, Wartungsereignissen oder unerwarteten Störungen zu erholen.
Failover verhindert nicht jeden Ausfall. Sein Wert liegt darin, dem System im Fehlerfall einen vorbereiteten Wiederherstellungspfad bereitzustellen.
Grundbedeutung und Rolle im System
Failover wird häufig in Hochverfügbarkeitskonzepten eingesetzt. Eine primäre Ressource übernimmt den normalen Betrieb, während eine oder mehrere Standby-Ressourcen bereitstehen, um zu übernehmen, wenn die primäre Ressource nicht mehr verfügbar ist. Die Ersatzressource kann ein weiterer Server, Router, Datenbankknoten, Netzwerklink, ein Rechenzentrum, eine Cloud-Region, ein Speichersystem oder eine Anwendungsinstanz sein.
Ziel ist es, Serviceunterbrechungen zu verringern. Statt darauf zu warten, dass Techniker die ausgefallene Komponente reparieren, leitet das System Datenverkehr, Workloads, Sitzungen oder Anfragen an eine andere verfügbare Ressource weiter.
Primäre und Standby-Ressourcen
Die primäre Ressource ist die aktive Komponente, die den Dienst normalerweise bereitstellt. Die Standby-Ressource ist vorbereitet, den Dienst zu übernehmen, wenn die primäre Ressource ausfällt. In manchen Systemen bleibt sie passiv, bis Failover ausgelöst wird. In anderen Systemen teilen mehrere Ressourcen den Datenverkehr gleichzeitig aktiv untereinander auf.
Beispielsweise kann eine Website auf zwei Anwendungsservern laufen. Fällt der erste Server aus, kann der Datenverkehr an den zweiten gesendet werden. Ein Router kann eine Backup-WAN-Verbindung nutzen, wenn die Hauptinternetverbindung ausfällt. Eine Datenbank kann eine Replik zum neuen Primärknoten hochstufen, wenn der ursprüngliche Primärknoten ausfällt.
Fehlererkennung
Failover hängt von der Fehlererkennung ab. Das System muss wissen, wann die Primärkomponente nicht gesund ist. Die Erkennung kann Heartbeat-Signale, Health Checks, Link-Überwachung, Dienstsonden, den Replikationsstatus einer Datenbank, Anwendungsantwortprüfungen oder Erreichbarkeitstests im Netzwerk verwenden.
Gute Erkennung muss schnell genug sein, um Ausfallzeiten zu reduzieren, darf aber nicht so empfindlich sein, dass sie bei kurzer Verzögerung oder vorübergehendem Paketverlust unnötiges Failover auslöst. Dieses Gleichgewicht ist in realen Netzwerk- und Anwendungsdesigns wichtig.
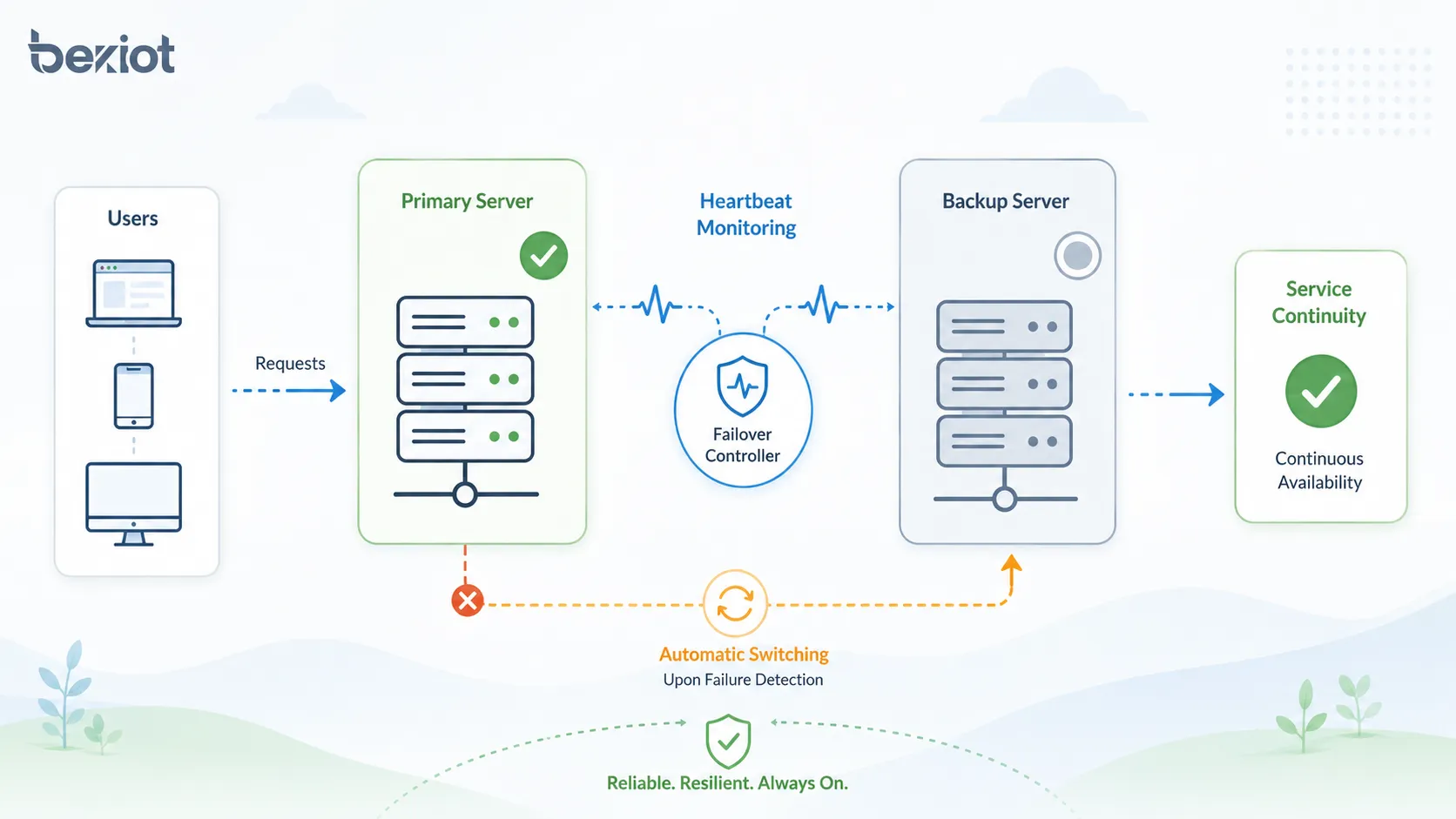
Wie der Failover-Prozess funktioniert
Der Failover-Prozess umfasst in der Regel Überwachung, Fehlererkennung, Entscheidungslogik, Dienstumschaltung, Umleitung des Datenverkehrs, Wiederherstellungsprüfung und Ereignisprotokollierung. Die Details unterscheiden sich je nach Systemtyp, die Grundlogik bleibt jedoch ähnlich.
Wenn die Überwachung erkennt, dass das Primärsystem nicht verfügbar oder nicht gesund ist, aktiviert der Failover-Controller den Ersatzpfad. Benutzer können eine kurze Unterbrechung bemerken, doch der Dienst sollte über die Ersatzkomponente weiterlaufen.
Überwachung und Health Checks
Health Checks werden verwendet, um zu bestätigen, ob ein Dienst korrekt arbeitet. Ein einfacher Check prüft vielleicht nur, ob ein Server auf Ping antwortet. Ein erweiterter Check kann prüfen, ob die Anwendung Anfragen verarbeitet, die Datenbank erreicht und gültige Antworten zurückgibt.
Prüfungen auf Anwendungsebene sind meist zuverlässiger als einfache Netzwerkprüfungen. Ein Server kann weiterhin auf Ping antworten, obwohl die darauf laufende Anwendung eingefroren, überlastet oder vom benötigten Backend getrennt ist.
Umschalten auf Ersatzressourcen
Nach bestätigtem Fehler schaltet das System den Betrieb auf die Ersatzressource um. Dies kann das Ändern von Routingtabellen, Aktualisieren von DNS-Einträgen, Verschieben einer virtuellen IP-Adresse, Hochstufen einer Datenbankreplik, Aktivieren eines Standby-Servers oder Umleiten von Datenverkehr über einen Load Balancer umfassen.
Die Umschaltmethode sollte zur Geschäftsanforderung passen. Manche Systeme können einige Minuten Unterbrechung tolerieren, während kritische Systeme nahezu sofortiges Failover mit minimaler Benutzerwirkung erfordern.
Dienstprüfung nach der Umschaltung
Nach dem Failover sollte der Ersatzdienst geprüft werden. Das System muss bestätigen, dass Benutzer sich verbinden können, Transaktionen fortgesetzt werden, Daten verfügbar sind und abhängige Dienste korrekt funktionieren.
Diese Prüfung ist wichtig, weil die Umleitung von Datenverkehr auf eine Ersatzkomponente nicht automatisch normalen Betrieb garantiert. Die Ersatzressource muss korrekt synchronisiert, richtig konfiguriert und für die Workload ausreichend leistungsfähig sein.
Wichtige Failover-Arten
Failover kann je nach Systemkritikalität, Budget, Leistungsanforderungen und Wiederherstellungszielen unterschiedlich gestaltet werden. Zu den häufigsten Modellen gehören Active-Passive, Active-Active, manuelles Failover, automatisches Failover, lokales Failover und geografisches Failover.
Active-Passive-Failover
Beim Active-Passive-Failover verarbeitet ein System aktiv den Produktionsverkehr, während ein anderes im Standby-Modus wartet. Fällt das aktive System aus, wird das passive System aktiv und übernimmt den Dienst.
Dieses Modell ist relativ einfach und wird häufig für Server, Firewalls, Datenbanken, PBX-Systeme, Storage-Controller und Netzwerk-Gateways genutzt. Sein Hauptvorteil ist die klare Rollentrennung. Die Einschränkung besteht darin, dass Standby-Ressourcen im Normalbetrieb möglicherweise wenig genutzt werden.
Active-Active-Failover
Beim Active-Active-Failover verarbeiten zwei oder mehr Systeme gleichzeitig Datenverkehr. Fällt ein System aus, bedienen die übrigen Systeme die Benutzer weiter und übernehmen die zusätzliche Last.
Dieses Modell verbessert Ressourcennutzung und Skalierbarkeit, erfordert aber sorgfältige Planung. Load Balancing, Datensynchronisierung, Sitzungsbehandlung, Konfliktkontrolle und Kapazitätsplanung werden komplexer.
Manuelles und automatisches Failover
Manuelles Failover erfordert, dass ein Operator oder Administrator die Umschaltung auslöst. Es bietet menschliche Kontrolle und kann bei Wartung, geplanter Migration oder sensiblen Systemänderungen sinnvoll sein.
Automatisches Failover wird durch Systemregeln ausgelöst. Es ist schneller und besser für Hochverfügbarkeitsumgebungen geeignet, muss aber sorgfältig konfiguriert werden, um falsches Failover, Split-Brain-Zustände oder wiederholtes Hin- und Herschalten zwischen Knoten zu vermeiden.
Lokales und geografisches Failover
Lokales Failover findet innerhalb derselben Site, desselben Racks, Rechenzentrums oder Netzwerkbereichs statt. Es schützt gegen lokale Server-, Link-, Strommodul- oder Gerätefehler.
Geografisches Failover verlagert den Dienst in ein anderes Rechenzentrum, eine andere Cloud-Region oder einen entfernten Standort. Es schützt vor größeren Ausfällen wie Rechenzentrumsausfall, regionaler Netzwerkstörung, Stromverlust, Brand, Überschwemmung oder schwerem Infrastrukturereignis.
Schlüsselfunktionen eines zuverlässigen Designs
Ein gutes Failover-System sollte nicht nur schnell umschalten. Es sollte sicher, konsistent und vorhersehbar umschalten. Zu den wichtigsten Funktionen gehören Überwachung, Redundanz, Synchronisierung, Traffic-Steuerung, Protokollierung und Wiederherstellungsplanung.
Redundante Komponenten
Redundanz bedeutet, dass Ersatzkomponenten verfügbar sind, bevor ein Fehler auftritt. Dazu können Server, Netzteile, Netzwerklinks, Router, Switches, Speicherpfade, Datenbanken, Anwendungsinstanzen und Cloud-Regionen gehören.
Redundanz muss sinnvoll sein. Ein Backup-Server, der an dieselbe ausgefallene Stromquelle oder denselben einzelnen Switch angeschlossen ist, bietet möglicherweise keine echte Resilienz. Designer sollten versteckte Single Points of Failure vermeiden.
Heartbeat und Statusüberwachung
Heartbeat-Signale helfen Systemen zu prüfen, ob der Primärknoten lebt. Wenn der Standby-Knoten innerhalb eines definierten Zeitraums keine Heartbeat-Nachrichten mehr erhält, kann er annehmen, dass der Primärknoten ausgefallen ist.
Das Heartbeat-Design muss Netzwerkverzögerung, Paketverlust und Zuverlässigkeit des Managementlinks berücksichtigen. Schlechte Konfiguration kann Split-Brain-Probleme verursachen, bei denen zwei Knoten glauben, aktiv sein zu müssen.
Datensynchronisierung
Viele Failover-Systeme benötigen Datensynchronisierung zwischen Primär- und Ersatzknoten. Dies kann Datenbankreplikation, Dateisynchronisierung, Storage-Mirroring, Konfigurationssicherung oder State Sharing umfassen.
Synchronisierung beeinflusst die Qualität der Wiederherstellung. Hat der Ersatz alte Daten, kann Failover den Dienst wiederherstellen, aber aktuelle Transaktionen verlieren. Ist die Synchronisierung zu langsam, werden Recovery Point Objectives möglicherweise nicht erfüllt.
Automatische Traffic-Umleitung
Traffic-Umleitung ermöglicht Benutzern oder Systemen, nach dem Failover den Ersatzdienst zu erreichen. Dies kann über Load Balancer, virtuelle IP-Adressen, Routingprotokolle, DNS-Failover, SD-WAN-Richtlinien oder Application Gateways erfolgen.
Die Umleitungsmethode sollte zur erwarteten Wiederherstellungszeit passen. DNS-basiertes Failover kann einfach sein, aber wegen Caching langsamer reagieren. Load-Balancer- oder virtuelle-IP-Failover kann in lokalen Hochverfügbarkeitsumgebungen schneller sein.
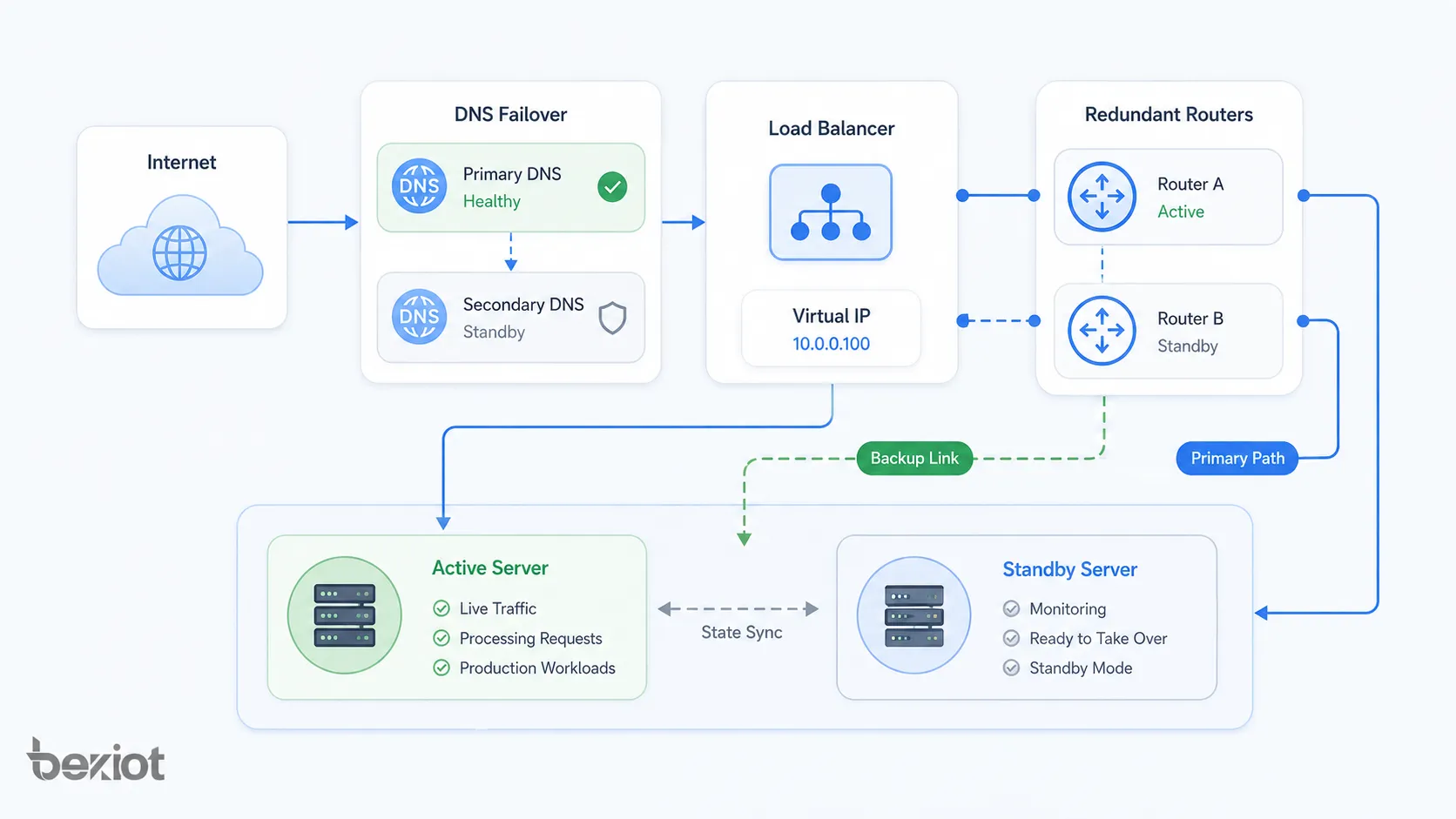
Muster der Netzwerkarchitektur
Failover-Architektur kann auf verschiedenen Ebenen eines Netzwerks und Systemstapels angewendet werden. Sie kann physische Links, Routingpfade, Servercluster, Datenbanken, Cloud-Regionen oder Anwendungsdienste schützen.
Server-Level-Failover
Server-Level-Failover verwendet zwei oder mehr Server, um denselben Dienst bereitzustellen. Fällt ein Server aus, übernimmt ein anderer. Dies ist üblich bei Anwendungsservern, Webservern, Dateiservern, Kommunikationsservern und Managementplattformen.
Server-Level-Failover kann Clustering-Software, Virtualisierungsplattformen, Load Balancer, Container-Orchestrierung oder Hochverfügbarkeitsdienste nutzen. Konfigurationskonsistenz zwischen Servern ist entscheidend.
Netzwerklink-Failover
Netzwerklink-Failover nutzt Ersatznetzwerkpfade, wenn die primäre Verbindung ausfällt. Beispiele sind Dual-WAN, Backup-Glasfaser, LTE- oder 5G-Backup, redundante ISP-Verbindungen und SD-WAN-Linkumschaltung.
Dies ist wichtig für Niederlassungen, entfernte Standorte, Einzelhandelsketten, Industrieanlagen und cloudverbundene Systeme. Fällt der Hauptlink aus, hält der Ersatzlink die Kommunikation verfügbar, auch wenn sich Bandbreite oder Latenz ändern.
Router- und Firewall-Failover
Router und Firewalls unterstützen häufig Hochverfügbarkeitspaare. Ein Gerät kann aktiv und ein anderes im Standby sein, oder beide teilen Last je nach Design. Oft wird eine virtuelle Gateway-Adresse verwendet, damit Clients nicht wissen müssen, welches physische Gerät aktiv ist.
Firewall-Failover sollte den Sitzungszustand nach Möglichkeit synchronisieren. Ohne Sitzungssynchronisierung können bestehende Verbindungen während des Failovers abbrechen, selbst wenn neue Verbindungen normal funktionieren.
Datenbank-Failover
Datenbank-Failover schützt Datendienste, indem von einer ausgefallenen Primärdatenbank auf eine Replik oder Standby-Datenbank umgeschaltet wird. Es wird in Unternehmensanwendungen, E-Commerce-Plattformen, Finanzsystemen, Cloud-Diensten und kritischen Betriebsplattformen genutzt.
Datenbank-Failover erfordert sorgfältigen Umgang mit Replikationsverzögerung, Transaktionskonsistenz, Schreibkonflikten und Anwendungs-Reconnect. Schlecht geplantes Datenbank-Failover kann Datenverlust oder Anwendungsfehler verursachen.
Cloud- und Multi-Region-Failover
Cloud-Failover kann Dienste zwischen Zonen, Regionen oder Cloud-Anbietern umschalten. Es schützt vor lokalen Infrastrukturausfällen und unterstützt Disaster-Recovery-Strategien.
Multi-Region-Failover kann globales Traffic Management, replizierte Datenbanken, Objektspeichersynchronisierung, Verfügbarkeit von Identitätsdiensten und getestete Wiederherstellungsverfahren erfordern. Das Design muss zu Recovery Time und Recovery Point Objectives passen.
Failover-Metriken und Planungsziele
Failover-Planung wird häufig durch Verfügbarkeits- und Wiederherstellungsmetriken gesteuert. Diese Metriken helfen Organisationen zu entscheiden, wie viel Redundanz nötig ist und wie viel Ausfallzeit oder Datenverlust akzeptabel ist.
| Metrik | Bedeutung | Warum sie wichtig ist |
|---|---|---|
| RTO | Recovery Time Objective | Maximal akzeptable Zeit zur Wiederherstellung des Dienstes nach einem Fehler |
| RPO | Recovery Point Objective | Maximal akzeptabler Datenverlust, gemessen als Zeitspanne |
| MTTR | Mean Time to Repair | Durchschnittliche Zeit zur Wiederherstellung einer ausgefallenen Komponente |
| MTBF | Mean Time Between Failures | Durchschnittliche Betriebszeit zwischen Ausfällen |
| Verfügbarkeit | Prozentsatz der Zeit, in der ein Dienst betriebsbereit ist | Zeigt die gesamte Uptime-Leistung des Dienstes |
Recovery Time Objective
Das Recovery Time Objective definiert, wie schnell ein Dienst nach einem Fehler wiederhergestellt werden muss. Ein nicht kritisches internes Reporting-Tool toleriert möglicherweise Stunden Ausfallzeit, während ein Zahlungssystem, eine Notfallplattform oder ein Produktionskontrollsystem Wiederherstellung in Sekunden oder Minuten benötigt.
Ein niedrigeres RTO erfordert meist mehr Investitionen in Automatisierung, Redundanz, Überwachung und Infrastruktur. Das Design sollte zur geschäftlichen Auswirkung passen und nicht annehmen, dass jedes System denselben Schutz benötigt.
Recovery Point Objective
Das Recovery Point Objective definiert, wie viel Datenverlust akzeptabel ist. Wenn eine Organisation nur wenige Sekunden Datenverlust tolerieren kann, braucht sie möglicherweise nahezu Echtzeit-Replikation. Wenn mehrere Stunden tolerierbar sind, kann geplante Sicherung ausreichen.
RPO ist besonders wichtig für Datenbanken, Dateisysteme, Transaktionsplattformen, Kundendatensätze und Betriebsprotokolle. Failover ohne Datenplanung kann den Dienst wiederherstellen, aber dennoch inakzeptable Geschäftsverluste verursachen.
Vorteile für Geschäft und Betrieb
Failover schafft Wert, weil Ausfallzeiten Umsatz, Sicherheit, Produktivität, Kundenvertrauen und Betriebskontinuität beeinflussen. Eine gut geplante Strategie hilft Organisationen, Dienste bei unerwarteten Fehlern und geplanter Wartung aufrechtzuerhalten.
Höhere Dienstverfügbarkeit
Der Hauptnutzen ist verbesserte Verfügbarkeit. Wenn eine Primärkomponente ausfällt, setzt die Ersatzkomponente den Dienst fort. Das reduziert Ausfallzeiten und hilft Benutzern, weiterzuarbeiten.
Hochverfügbarkeit ist wichtig für Online-Dienste, Kommunikationssysteme, Gesundheitsplattformen, Verkehrsnetze, industrielle Automatisierung, Finanzsysteme und öffentlich zugängliche Anwendungen.
Geringeres Betriebsrisiko
Failover reduziert das Risiko, dass der Ausfall einer einzelnen Komponente das gesamte System stoppt. Das ist besonders wichtig für Systeme mit Single Points of Failure, etwa eine einzelne Internetverbindung, ein Server, eine Datenbank oder ein Gateway.
Durch Ersatzpfade und automatisierte Wiederherstellungslogik können Organisationen die Auswirkungen von Hardwarefehlern, Netzwerkausfällen, Softwareabstürzen und Wartungsunterbrechungen verringern.
Mehr Wartungsflexibilität
Failover kann geplante Wartung unterstützen. Administratoren können Dienste von einem Knoten auf einen anderen verschieben, das Primärsystem aktualisieren, Änderungen testen und nach Abschluss zurückschalten.
Dadurch werden lange Wartungsfenster weniger nötig. Auch Upgrades werden sicherer, weil der Dienst über Ersatzressourcen verfügbar bleiben kann.
Stärkeres Benutzervertrauen
Benutzer sehen den Failover-Prozess vielleicht nicht direkt, bemerken aber, wenn Dienste verfügbar bleiben. Zuverlässige Systeme verbessern Kundenvertrauen, Mitarbeiterproduktivität und Vertrauen in digitale Infrastruktur.
Für kritische Kommunikations-, Industrie- und Geschäftsplattformen ist Verfügbarkeit nicht nur eine technische Kennzahl. Sie ist Teil der Serviceerfahrung.
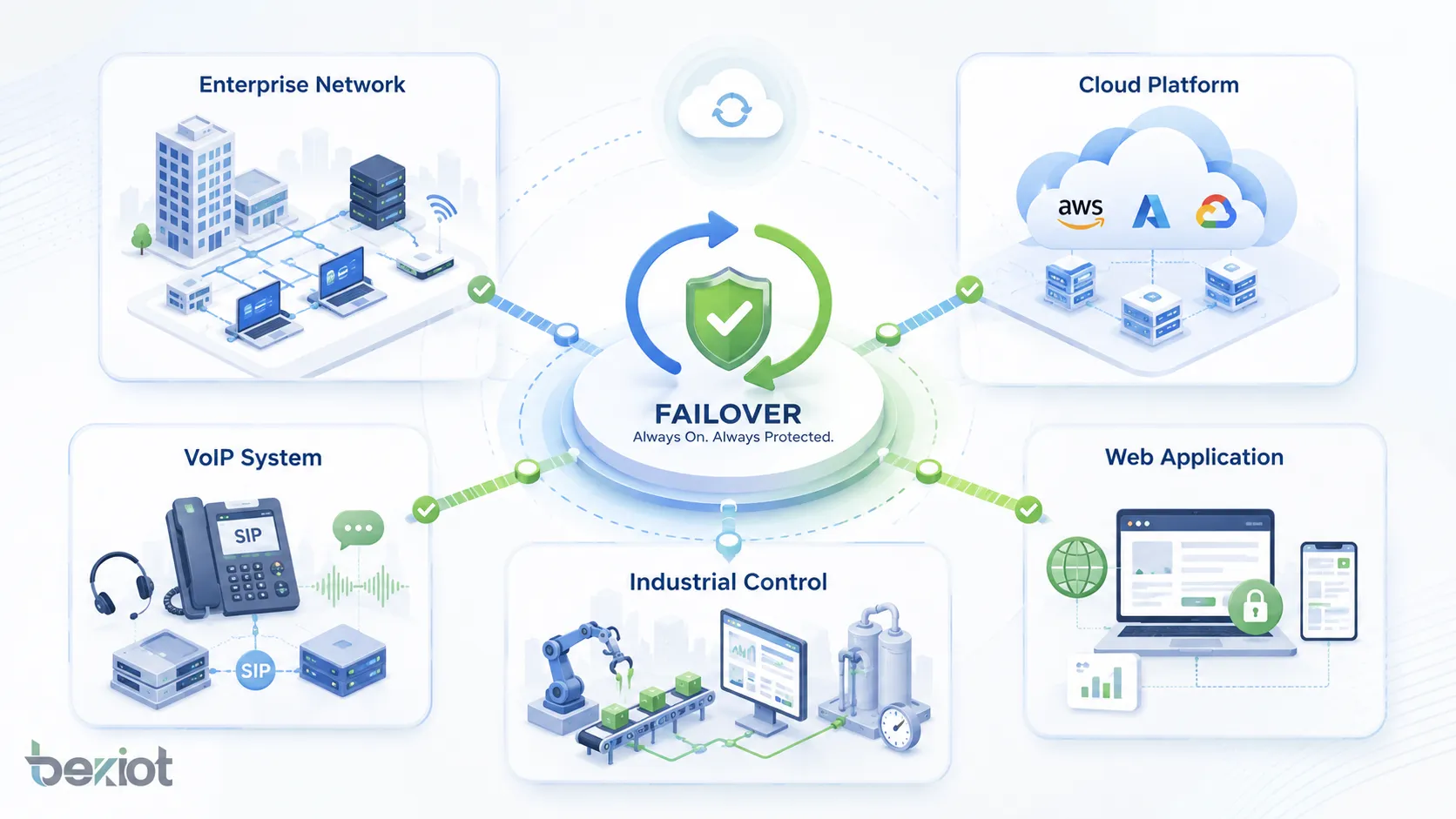
Anwendungen in verschiedenen Systemen
Failover wird überall eingesetzt, wo Kontinuität wichtig ist. Das genaue Design hängt vom Systemtyp ab, doch das Ziel bleibt gleich: Serviceunterbrechungen vermeiden, wenn etwas ausfällt.
Unternehmensnetzwerke
Unternehmensnetzwerke nutzen Failover für Internetlinks, Firewalls, Router, Switches, VPN-Tunnel, Wireless Controller und Niederlassungsverbindungen. Fällt ein Pfad aus, kann der Verkehr auf einen anderen wechseln.
In Organisationen mit mehreren Niederlassungen hilft Failover, entfernte Büros mit Cloud-Diensten, Rechenzentren, Kommunikationssystemen und Geschäftsanwendungen verbunden zu halten.
Rechenzentren und Cloud-Plattformen
Rechenzentren nutzen Failover für Server, Speicher, Datenbanken, Virtualisierungscluster, Stromsysteme, Kühlsysteme und Netzwerkfabrics. Cloud-Plattformen verwenden Availability Zones, Region-Failover, Load Balancer, Auto-Scaling-Gruppen und verwaltete Datenbankrepliken.
Diese Designs helfen Anwendungen, Hardwarefehler, Hostfehler, Rackfehler oder sogar regionale Dienststörungen zu überstehen, wenn sie richtig geplant sind.
VoIP- und Kommunikationssysteme
VoIP- und SIP-Systeme können Failover für SIP-Server, PBX-Plattformen, Gateways, SBCs, SIP-Trunks, DNS-SRV-Einträge, Medienserver und Netzwerklinks nutzen. Fällt ein Server oder Trunk aus, können Anrufe über einen Ersatzpfad geroutet werden.
Das ist für Unternehmenskommunikation wichtig, weil ausgefallene Sprachdienste Kundenkontakt, interne Koordination, Notrufe und Servicebetrieb beeinträchtigen können.
Industrie- und Betriebstechnik
Industrielle Umgebungen können Failover für SCADA-Server, Steuerungsnetze, Monitoringplattformen, HMI-Stationen, Historian-Systeme, industrielle Gateways und Kommunikationslinks nutzen. Ziel ist, Produktion, Überwachung und sicherheitsbezogene Abläufe verfügbar zu halten.
Industrielles Failover-Design muss deterministische Kommunikation, Gerätekompatibilität, Umgebungsbedingungen und sichere Betriebsabläufe berücksichtigen. Automatische Umschaltung darf kein unsicheres Maschinenverhalten erzeugen.
Webanwendungen und Online-Dienste
Webanwendungen nutzen Failover über Load Balancer, replizierte Anwendungsserver, Datenbankrepliken, CDN-Dienste, DNS-Failover und Multi-Region-Bereitstellung. Diese Methoden helfen Websites und APIs, bei Server- oder Netzwerkfehlern verfügbar zu bleiben.
Für E-Commerce, Banking, SaaS, Streaming und Kundenportale kann Failover Umsatz und Benutzererfahrung bei unerwarteten Störungen schützen.
Häufige Herausforderungen und Risiken
Failover verbessert Resilienz, aber schlechtes Design kann neue Probleme schaffen. Das Ersatzsystem muss getestet, aktualisiert, synchronisiert und richtig dimensioniert sein. Andernfalls kann Failover genau dann scheitern, wenn es am dringendsten benötigt wird.
Falsches Failover
Falsches Failover tritt auf, wenn das System auf den Ersatz umschaltet, obwohl der Primärdienst nicht wirklich ausgefallen ist. Ursachen können vorübergehender Paketverlust, langsame Antwort, überlastete Überwachung oder zu aggressive Schwellenwerte sein.
Falsches Failover kann Benutzer unnötig unterbrechen. Health Checks sollten echte Dienstfehler bestätigen, bevor umgeschaltet wird.
Split-Brain-Zustand
Ein Split-Brain-Zustand entsteht, wenn zwei Knoten beide glauben, der aktive Primärknoten zu sein. Das kann passieren, wenn die Heartbeat-Kommunikation ausfällt, aber beide Systeme weiterlaufen.
Split-Brain ist in Datenbank-, Speicher- und Clustersystemen gefährlich, weil es Datenkorruption oder konkurrierende Schreibvorgänge verursachen kann. Quorum-Mechanismen, Fencing und gutes Clusterdesign reduzieren dieses Risiko.
Kapazitätsprobleme des Ersatzsystems
Eine Ersatzressource muss genug Kapazität haben, um die Workload nach dem Failover zu tragen. Ist sie zu klein, kann der Dienst technisch online bleiben, aber schlecht funktionieren.
Kapazitätsplanung sollte Spitzenlast, Wachstum, Betrieb im Degraded Mode und die Möglichkeit mehrerer gleichzeitiger Fehler berücksichtigen.
Ungetestete Wiederherstellungspläne
Ein Failover-Design, das nie getestet wurde, ist nicht zuverlässig. Konfigurationsdrift, abgelaufene Zertifikate, veraltete Backups, Firewall-Änderungen, DNS-Caching, fehlende Lizenzen oder alte Softwareversionen können erfolgreiche Wiederherstellung verhindern.
Regelmäßige Failover-Übungen sind notwendig. Tests sollten nach Möglichkeit sowohl geplantes Failover als auch ungeplante Fehlerszenarien umfassen.
Best Practices für zuverlässige Bereitstellung
Failover sollte als Teil einer umfassenderen Hochverfügbarkeits- und Disaster-Recovery-Strategie geplant werden. Dazu gehören Architekturplanung, Überwachung, Dokumentation, Tests und kontinuierliche Verbesserung.
Kritische Dienste zuerst identifizieren
Nicht jedes System benötigt dasselbe Failover-Niveau. Organisationen sollten bestimmen, welche Dienste kritisch sind, wie Ausfallzeiten den Betrieb beeinflussen und welche Wiederherstellungsziele nötig sind.
Das hilft, Investitionen zu priorisieren. Kritische Systeme benötigen möglicherweise automatisches Failover und geografische Redundanz, während weniger kritische Systeme nur Backup und manuelle Wiederherstellung benötigen.
Versteckte Single Points of Failure beseitigen
Failover kann durch versteckte Abhängigkeiten geschwächt werden. Ein Backup-Server kann denselben Speicher, dieselbe Stromversorgung, denselben Netzwerkswitch, DNS-Dienst oder dasselbe Authentifizierungssystem wie der Primärserver nutzen.
Eine Architekturprüfung sollte diese Abhängigkeiten erkennen. Echte Resilienz erfordert Redundanz über den gesamten Dienstpfad, nicht nur auf der sichtbaren Anwendungsebene.
Konfiguration synchron halten
Primär- und Ersatzsysteme sollten konsistente Konfigurationen verwenden. Unterschiede bei Softwareversion, Firewall-Regeln, Zertifikaten, Routingrichtlinien, Benutzerdaten oder Anwendungseinstellungen können Failover verhindern.
Konfigurationsmanagement-Tools, Vorlagen, Backups und Change Control helfen, Systeme ausgerichtet zu halten. Nach jeder größeren Änderung sollte die Failover-Bereitschaft erneut geprüft werden.
Failover regelmäßig testen
Regelmäßige Tests bestätigen, ob Failover unter realen Bedingungen funktioniert. Sie sollten Erkennungszeit, Umschaltzeit, Datenkonsistenz, Anwendungsverhalten, Benutzerzugriff, Protokollierung und Failback-Verfahren prüfen.
Tests sollten dokumentiert werden. Jeder Test sollte festhalten, was getestet wurde, was geschah, was fehlschlug und welche Verbesserungen nötig sind.
Failback und Wiederherstellung nach Failover
Failover ist nur ein Teil des Wiederherstellungsprozesses. Nachdem das Primärsystem repariert wurde, muss die Organisation entscheiden, ob und wie der Dienst zurückverlagert wird. Dieser Prozess heißt Failback.
Wann zurückgeschaltet werden sollte
Failback sollte nicht zu schnell erfolgen. Das ursprüngliche Primärsystem sollte vollständig repariert, getestet, synchronisiert und verifiziert sein, bevor der Datenverkehr zurückgeführt wird. Ein überstürztes Failback kann zu erneutem Ausfall und weiterer Unterbrechung führen.
Manche Organisationen lassen das Ersatzsystem bis zum nächsten Wartungsfenster aktiv. So wird eine kontrollierte Rückkehr statt einer sofortigen Umschaltung möglich.
Daten- und Zustandssynchronisierung
Vor dem Failback müssen die während des Ersatzbetriebs entstandenen Daten zurück zum ursprünglichen Primärsystem synchronisiert werden. Das ist besonders wichtig für Datenbanken, Dateien, Transaktionen, Benutzersitzungen und Konfigurationsänderungen.
Ohne richtige Synchronisierung kann Failback Datenverlust, veraltete Datensätze oder inkonsistentes Dienstverhalten verursachen.
Überprüfung nach dem Vorfall
Nach einem Failover-Ereignis sollten Teams überprüfen, was passiert ist. Die Überprüfung sollte Fehlerursache, Erkennungszeit, Umschaltergebnis, Benutzerwirkung, Ersatzleistung, Kommunikationsablauf und Verbesserungsmaßnahmen umfassen.
Dadurch wird Failover von einem einmaligen Wiederherstellungsereignis zu einem kontinuierlichen Prozess zur Verbesserung der Zuverlässigkeit.
FAQ
Was ist Failover?
Failover ist ein Zuverlässigkeitsmechanismus, der Dienste, Datenverkehr, Workloads oder Abläufe von einer ausgefallenen Primärkomponente auf eine Ersatzkomponente umschaltet. Es dient dazu, Ausfallzeiten zu reduzieren und Dienstkontinuität zu erhalten.
Was ist der Unterschied zwischen Failover und Backup?
Backup speichert Daten oder Konfigurationen für die Wiederherstellung. Failover schaltet den aktiven Dienst bei einem Fehler auf eine andere Ressource um. Backup hilft, Informationen wiederherzustellen, während Failover den Dienst am Laufen hält.
Was ist Active-Passive-Failover?
Active-Passive-Failover nutzt ein aktives System und ein Standby-System. Das Standby-System übernimmt nur, wenn das aktive System ausfällt oder für Wartung offline genommen wird.
Was ist Active-Active-Failover?
Active-Active-Failover nutzt mehrere Systeme, die gleichzeitig Datenverkehr verarbeiten. Fällt eines aus, bedienen die übrigen weiterhin die Benutzer und übernehmen die zusätzliche Workload.
Wo wird Failover häufig eingesetzt?
Failover wird häufig in Unternehmensnetzwerken, Cloud-Plattformen, Rechenzentren, Datenbanken, Webanwendungen, VoIP-Systemen, Firewalls, Routern, Speichersystemen und industriellen Steuerungsplattformen eingesetzt.
Wie kann Failover getestet werden?
Failover kann getestet werden, indem ein Primärsystemausfall simuliert wird, Netzwerkpfade kontrolliert getrennt werden, Testknoten heruntergefahren werden, Wartungs-Failover ausgelöst wird, die Dienstumschaltung geprüft wird, Datenkonsistenz verifiziert und Protokolle nach der Wiederherstellung ausgewertet werden.







