

Mean Time to Repair, meist als MTTR abgekürzt, ist eine Kennzahl für Wartung und Zuverlässigkeit. Sie misst die durchschnittliche Zeit, die erforderlich ist, um eine ausgefallene Anlage, ein Gerät, eine Maschine, einen Softwaredienst, eine Netzwerkkomponente oder ein Produktionssystem wieder in den normalen Betrieb zu bringen. Der Schwerpunkt liegt auf dem Reparaturprozess nach einem Ausfall und damit auf Stillstandsbegrenzung, Serviceeffizienz, operativer Resilienz und Wartungsplanung.
In Fabriken, Rechenzentren, Telekommunikationsnetzen, Verkehrssystemen, Energieanlagen, Krankenhäusern, Gebäuden und IT-Umgebungen lassen sich Ausfälle nicht immer vermeiden. Entscheidend ist, wie schnell eine Organisation den Fehler erkennt, die Ursache diagnostiziert, die Reparatur abschließt, das Ergebnis prüft und den Dienst wiederherstellt. MTTR macht diese Wiederherstellungsleistung messbar.
Grundbedeutung im Zuverlässigkeitsmanagement
Mean Time to Repair beschreibt die durchschnittliche Reparaturdauer über mehrere Ausfallereignisse hinweg. Sie ist nicht die Zeit zwischen Ausfällen und nicht die gesamte Systemausfallzeit über einen langen Zeitraum. Die Kennzahl beantwortet die praktische Frage: Wenn etwas ausfällt, wie lange dauert die Behebung normalerweise?
Sie wird von Wartungsingenieuren, Facility-Managern, IT-Serviceteams, Reliability Engineers, Herstellern und Betriebsleitern genutzt. Eine niedrigere MTTR bedeutet meist schnellere Wiederherstellung, bessere Wartungsreaktion, höhere Ersatzteilbereitschaft, klarere Abläufe und wirksameres Troubleshooting.
Was MTTR tatsächlich misst
MTTR umfasst in der Regel die aktive Reparaturzeit, die benötigt wird, um einen Vermögenswert wieder funktionsfähig zu machen. Je nach Definition kann sie Fehlerbestätigung, Diagnose, Ersatzteiltausch, Konfigurationswiederherstellung, Funktionstest und endgültige Servicewiederherstellung einschließen.
Wenn etwa eine Produktionsmaschine wegen eines defekten Sensors stoppt, kann die Reparaturzeit Technikereinsatz, Sensorprüfung, Austausch, Kalibrierung und Neustartprüfung enthalten. Bei einem Serverausfall können Incident-Analyse, Komponententausch, Datenwiederherstellung, Neustart und Servicevalidierung dazugehören.
Warum die Definition klar sein muss
Organisationen berechnen MTTR teilweise unterschiedlich. Manche zählen ab der Fehlermeldung, andere ab Beginn der Reparaturarbeit. Einige berücksichtigen Wartezeit auf Ersatzteile, andere nur die praktische technische Reparaturzeit.
Deshalb muss MTTR vor Leistungsvergleichen klar definiert werden. Ohne einheitliche Definition kann die Kennzahl irreführend sein. Ein Team wirkt möglicherweise langsam, weil Warte-, Freigabe- oder Reisezeit enthalten ist, während ein anderes nur die eigentliche Reparaturaktivität misst.
Wie die Berechnung funktioniert
Die Standardformel ist einfach. Alle Reparaturzeiten in einem bestimmten Zeitraum werden addiert und durch die Anzahl der Reparaturereignisse geteilt. Das Ergebnis zeigt die durchschnittliche Zeit, die zur Wiederherstellung des ausgefallenen Assets oder Systems benötigt wird.
Dauern fünf Reparaturen 2 Stunden, 3 Stunden, 1 Stunde, 4 Stunden und 5 Stunden, beträgt die gesamte Reparaturzeit 15 Stunden. 15 Stunden geteilt durch fünf Ereignisse ergeben eine MTTR von 3 Stunden. Jede Reparatur dauert also durchschnittlich 3 Stunden.
Erfassung der Reparaturzeit
Eine genaue MTTR hängt von genauen Reparaturdaten ab. Teams müssen erfassen, wann der Fehler erkannt wurde, wann die Reparatur begann, welche Maßnahmen erfolgten, wann der Service wiederhergestellt war und ob die Reparatur geprüft wurde. Wartungsmanagementsysteme, Ticketsysteme, SCADA-Protokolle, Service Desks und CMMS können diese Daten liefern.
Manuelle Aufzeichnungen können ebenfalls funktionieren, müssen aber konsistent sein. Wenn Arbeitsaufträge nicht geschlossen, Zeiten unvollständig erfasst oder Vorfälle unterschiedlich klassifiziert werden, spiegelt die MTTR die reale Betriebsleistung nicht zuverlässig wider.
Einfaches Beispiel für Gerätereparatur
Eine Lüftungseinheit fällt innerhalb eines Monats dreimal aus. Die erste Reparatur dauert 90 Minuten, die zweite 120 Minuten und die dritte 60 Minuten. Die gesamte Reparaturzeit beträgt 270 Minuten.
Nach der MTTR-Formel ergeben 270 Minuten geteilt durch 3 Reparaturereignisse 90 Minuten. Die MTTR dieser Lüftungseinheit beträgt somit 90 Minuten. Facility-Manager können damit Reaktionsleistung, Technikerbelastung, Ersatzteilverfügbarkeit und Bedarf an vorbeugender Wartung bewerten.
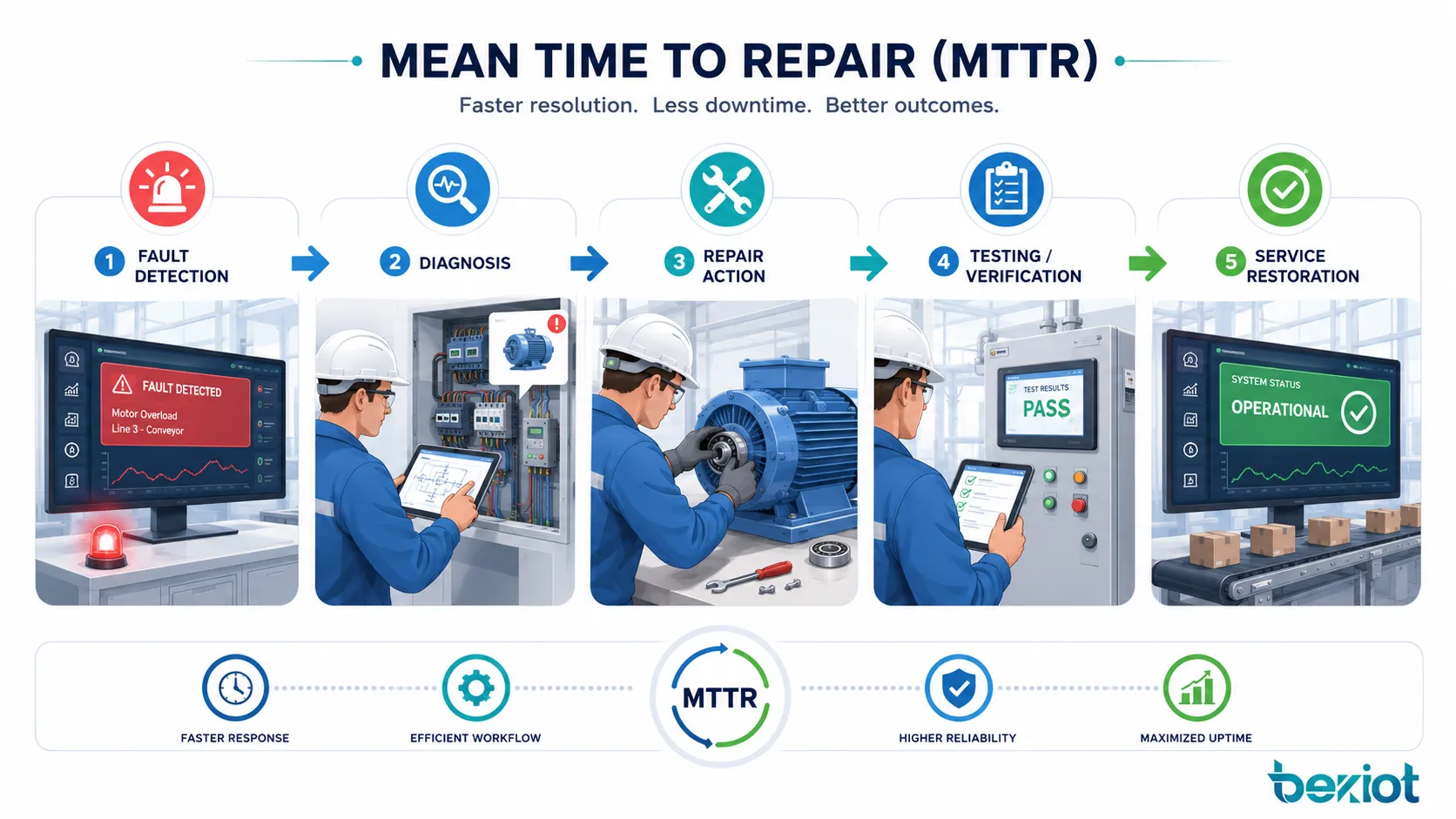
Was während eines Reparaturzyklus geschieht
MTTR ist nicht nur ein mathematischer Durchschnitt. Sie spiegelt den vollständigen Reparaturablauf hinter jedem Ausfall wider. Lange Reparaturzeiten können durch langsame Fehlererkennung, unklare Diagnoseschritte, fehlende Ersatzteile, schlechte Dokumentation, schwierigen Zugang oder fehlend geschultes Personal entstehen.
Das Verständnis des Reparaturzyklus hilft Teams, die tatsächlichen Ursachen von Stillstand zu verbessern, anstatt nur auf die Endzahl zu schauen.
Fehlererkennung und Meldung
Der Reparaturzyklus beginnt mit der Erkennung des Fehlers. In manchen Systemen geschieht dies automatisch durch Alarme, Sensoren, Monitoring-Dashboards, Selbstdiagnose oder Fehlercodes. In anderen Fällen bemerkt ein Bediener, Nutzer oder Techniker das Problem und meldet es manuell.
Schnelle Erkennung reduziert die Gesamtauswirkung eines Ausfalls. Wird ein Maschinenfehler sofort entdeckt, kann die Reparatur beginnen, bevor Qualität, Sicherheit oder nachgelagerte Anlagen betroffen sind. In IT- und Netzwerkbetrieben verkürzen automatische Alarme die Incident-Reaktionszeit deutlich.
Diagnose und Ursachenidentifikation
Nach der Erkennung müssen Techniker oder Ingenieure die Ursache finden. Die Diagnose kann Sichtprüfung, Log-Analyse, elektrische Tests, mechanische Prüfung, Softwareprüfung, Netzwerk-Trace oder Vergleich mit früheren Fehlerdaten umfassen.
Die Diagnose ist oft einer der wichtigsten MTTR-Faktoren. Ein Team mit guter Dokumentation, klaren Fehlercodes, Remote-Monitoring und erfahrenen Technikern findet Probleme schneller als ein Team, das nur durch Versuch und Irrtum arbeitet.
Reparatur, Austausch und Verifizierung
Die eigentliche Reparatur kann Komponententausch, Software-Neustart, Konfigurationskorrektur, Kabelreparatur, mechanische Einstellung, Firmware-Wiederherstellung, Reinigung, Schmierung, Neukalibrierung oder vollständigen Gerätetausch umfassen.
Nach Abschluss der Reparatur sollte das System vor der normalen Nutzung getestet werden. Dazu gehören Starttests, Sicherheitsprüfungen, Produktionsprobeläufe, Netzwerkverbindungstests, Alarm-Reset oder Benutzerabnahme. Ohne Verifizierung kann ein System scheinbar repariert sein und kurz darauf wieder ausfallen.
Warum diese Kennzahl wichtig ist
MTTR ist wichtig, weil Stillstand reale Folgen hat. Er kann Produktion stoppen, Servicebereitstellung verzögern, Kundenzufriedenheit senken, Betriebskosten erhöhen, Sicherheitsrisiken schaffen und Geschäftskontinuität stören. Durch das Verfolgen der Reparaturzeit erkennt eine Organisation Schwachstellen und verbessert die Wiederherstellung.
MTTR ist am wertvollsten, wenn sie zu Maßnahmen führt. Ziel ist nicht nur die Berechnung einer Durchschnittszeit, sondern das Verständnis, warum Reparaturen so lange dauern und wie der Prozess verbessert werden kann.
Auswirkungen von Stillstand reduzieren
Eine niedrigere MTTR bedeutet, dass Anlagen oder Systeme nach einem Ausfall schneller wieder arbeiten. In der Fertigung reduziert dies Produktionsverluste. In Telekommunikation und IT verringert es Serviceunterbrechungen. In Gebäuden und Infrastruktur verbessert es Komfort, Sicherheit und Verfügbarkeit.
Besonders kritisch ist dies bei missionskritischen Systemen. Notfallkommunikation, Energieverteilung, Medizintechnik, Verkehrssteuerung, Sicherheitssysteme und Produktionslinien benötigen schnelle Wiederherstellung, weil Unterbrechungen erhebliche betriebliche Folgen haben können.
Wartungseffizienz verbessern
MTTR hilft Wartungsteams zu bewerten, wie effizient sie auf Probleme reagieren. Steigt die durchschnittliche Reparaturzeit, können Manager untersuchen, ob Ersatzteilverzögerungen, fehlende Schulung, schwieriger Zugang, langsame Eskalation oder unklare Anweisungen die Ursache sind.
Durch Vergleich nach Gerätetyp, Standort, Schicht oder Serviceteam erkennt die Organisation, wo Verbesserungen am dringendsten sind. Dies unterstützt bessere Personalplanung, gezielte Schulungen, bessere Dokumentation und intelligentere Ersatzteilplanung.
Zuverlässigkeits- und Verfügbarkeitsziele unterstützen
Systemverfügbarkeit hängt sowohl von Ausfallhäufigkeit als auch von Wiederherstellungsgeschwindigkeit ab. Selbst gelegentliche Ausfälle können akzeptabel bleiben, wenn Reparaturen schnell erfolgen. Deshalb wird MTTR oft mit MTBF, Uptime-Prozent, Service-Level-Zielen und Zuverlässigkeitszielen kombiniert.
Ein System mit häufigen Ausfällen und langen Reparaturen hat schlechte Verfügbarkeit. Ein System mit seltenen Ausfällen und kurzen Reparaturen schneidet hinsichtlich Betriebskontinuität deutlich besser ab.
Vorteile für Betriebs- und Wartungsteams
MTTR verbindet technische Wartungsleistung mit geschäftlichen Ergebnissen. Sie hilft Teams, von reaktiver Reparatur zu strukturierter Verbesserung überzugehen. Anstatt Stillstand allgemein zu diskutieren, können Manager Entscheidungen auf Reparaturzeitdaten stützen.
Bessere Ersatzteilplanung
Wenn Reparaturen wegen fehlender Ersatzteile zu lange dauern, zeigen MTTR-Daten das Problem. Wartungsteams können kritische Komponenten identifizieren, Mindestbestände festlegen, Lieferantenvereinbarungen verbessern oder Austauschmodule für schnellere Wiederherstellung nutzen.
Bei hochwertigen oder sicherheitsrelevanten Assets können Lagerkosten für Ersatzteile deutlich niedriger sein als Kosten langer Ausfälle. MTTR-Analysen liefern messbare Belege für diese Entscheidung.
Klareres Service-Level-Management
In ausgelagerter Wartung, IT-Support, Telekomservices und Facility Operations kann MTTR Service-Level-Vereinbarungen unterstützen. Sie gibt Dienstleister und Kunden einen messbaren Indikator für Reparaturleistung.
Zielwerte müssen realistisch sein. Ein einfacher Zutrittsleser ist nicht mit einer komplexen Produktionslinie, einem großen HVAC-System oder einem standortübergreifenden Netzwerkausfall vergleichbar. Komplexität, Standort, Risiko und Zugang müssen berücksichtigt werden.
Wirksamere Schulung und Dokumentation
Eine hohe MTTR kann zeigen, dass Techniker bessere Schulung oder klarere Anweisungen benötigen. Dauert derselbe Fehlertyp wiederholt lange, kann die Organisation Standardleitfäden, visuelle Arbeitsanweisungen, Diagnoselisten oder Remote-Support-Prozesse erstellen.
Gute Dokumentation verringert Abhängigkeit von individueller Erfahrung, hilft neuen Technikern sicherer zu arbeiten und reduziert wiederholte Fehler.
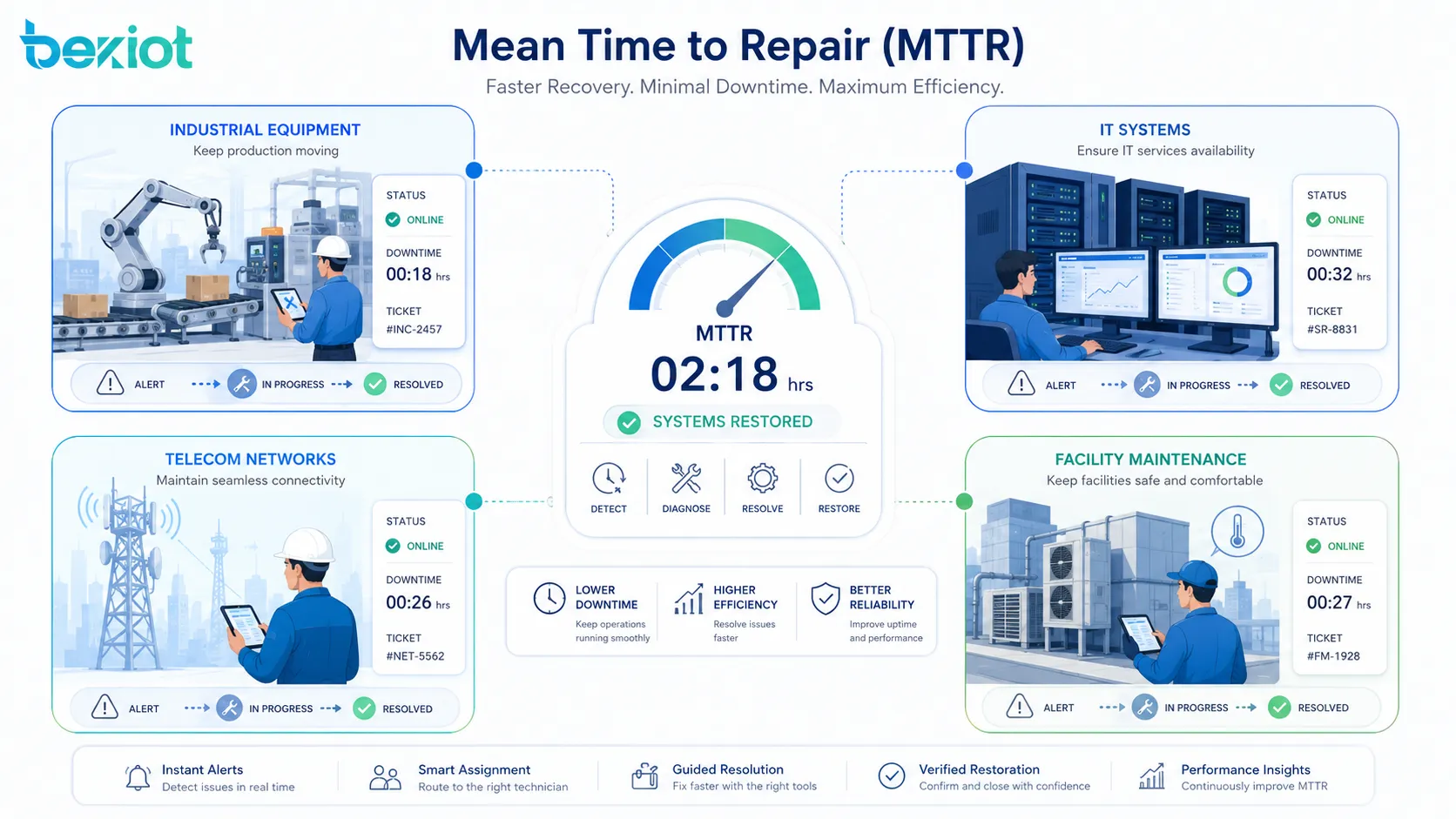
Typische Anwendungen in verschiedenen Branchen
Mean Time to Repair wird in vielen Branchen genutzt, weil fast jede Organisation von Assets, Systemen, Geräten oder Diensten abhängt, die ausfallen können. Der konkrete Prozess unterscheidet sich, doch der Bedarf, Wiederherstellungszeit zu messen und zu verbessern, ist universell.
Fertigung und Industrieanlagen
In Fertigungsbetrieben misst MTTR die Reparaturleistung von Produktionslinien, Motoren, Pumpen, Förderanlagen, Robotern, CNC-Maschinen, Verpackungsanlagen, Sensoren, Schaltschränken und Versorgungssystemen.
Eine niedrigere MTTR verbessert Produktionskontinuität, reduziert Überstunden, erhöht Asset-Auslastung und unterstützt Lean-Maintenance-Programme. Sie zeigt auch, welche Maschinen die größte Reparaturlast verursachen.
IT-Systeme und Rechenzentren
In IT-Betrieben kann MTTR auf Server, Storage, Anwendungen, Datenbanken, Cloud-Dienste, Firewalls, Switches, Router und Benutzerplattformen angewendet werden. Sie wird häufig im Incident Management und Site Reliability Engineering genutzt.
Bei digitalen Diensten bedeutet Reparatur oft Wiederherstellung von Softwarefunktionen statt Austausch physischer Teile. Der Prozess kann Logprüfung, Rollback, Patch, Failover, Konfigurationskorrektur, Neustart oder Recovery aus Backups enthalten.
Telekommunikation und Netzwerkinfrastruktur
Telekommunikationsbetreiber und Unternehmensnetzwerkteams nutzen MTTR für Basisstationen, Glasfaserverbindungen, Übertragungstechnik, IP-Netze, Kommunikationsgateways, Router, Switches und Serviceplattformen.
Netzwerkausfälle können viele Nutzer gleichzeitig betreffen. Schnelle Reparatur und genaue Fehlerlokalisierung sind wesentlich für Servicequalität. Remote-Monitoring, redundante Links, klare Eskalation und Außendienstkoordination helfen, MTTR zu senken.
Gebäude, Anlagen und Versorgungssysteme
Facility-Manager nutzen MTTR für HVAC-Systeme, Aufzüge, Pumpen, Lichtsteuerung, Zutrittskontrolle, Brandmeldeschnittstellen, Sicherheitstechnik, Stromverteilung, Wassersysteme und Gebäudeautomation.
In Gebäuden und Versorgungsumgebungen ist MTTR eng mit Komfort, Sicherheit, Compliance und Servicekontinuität verbunden. Lange Reparaturen können Mieter, Besucher, Produktionsbereiche oder öffentliche Infrastrukturnutzer betreffen.
MTTR im Vergleich mit verwandten Kennzahlen
MTTR wird häufig zusammen mit anderen Zuverlässigkeits- und Wartungskennzahlen betrachtet. Das Verständnis der Unterschiede hilft, den passenden Indikator zu wählen. MTTR konzentriert sich auf Reparaturgeschwindigkeit; andere Kennzahlen fokussieren Ausfallhäufigkeit, Verfügbarkeit oder Incident-Reaktionszeit.
| Kennzahl | Bedeutung | Hauptzweck |
|---|---|---|
| MTTR | Mean Time to Repair | Misst die durchschnittliche Zeit zur Wiederherstellung eines ausgefallenen Assets oder Systems |
| MTBF | Mean Time Between Failures | Misst die durchschnittliche Betriebszeit zwischen Ausfällen |
| MTTF | Mean Time to Failure | Schätzt die erwartete Lebensdauer nicht reparierbarer Elemente bis zum Ausfall |
| MTTA | Mean Time to Acknowledge | Misst, wie lange es dauert, einen Vorfall zu bemerken und zu bestätigen |
| Availability | Betriebliche Verfügbarkeitsrate | Zeigt, wie häufig ein System nutzbar ist |
MTTR und MTBF
MTBF misst, wie häufig Ausfälle auftreten, während MTTR misst, wie schnell sie repariert werden. Beides ist wichtig. Ein System kann eine hohe MTBF haben und dennoch starke Störungen verursachen, wenn jede Reparatur lange dauert.
Eine Maschine, die nur zweimal jährlich ausfällt, kann problematisch sein, wenn jede Reparatur drei Tage dauert. Ein weniger kritisches Gerät kann häufiger ausfallen, aber in Minuten repariert werden. MTBF und MTTR sollten gemeinsam betrachtet werden.
MTTR und Verfügbarkeit
Verfügbarkeit wird stark von MTTR beeinflusst. Sinkt die Reparaturzeit bei gleicher Ausfallrate, kann die Verfügbarkeit steigen. Deshalb ist die Senkung der MTTR eine übliche Strategie für Systeme, die nicht sofort ausfallsicherer konstruiert werden können.
Praktisch verbessern Teams Verfügbarkeit durch Fehlervermeidung, schnellere Reparatur, Redundanz, besseres Monitoring oder Systeme, die während der Reparatur in reduziertem Modus weiterlaufen.
Wie Reparaturzeit reduziert werden kann
MTTR zu senken bedeutet mehr als Techniker zu schnellerer Arbeit anzuhalten. Nachhaltige Verbesserung kommt durch besseres Systemdesign, bessere Informationen, bessere Vorbereitung und bessere Koordination. Ziel ist es, Verzögerungen aus dem Reparaturprozess zu entfernen.
Monitoring und frühe Fehlererkennung nutzen
Automatisches Monitoring erkennt abnorme Zustände, bevor sie zu großen Ausfällen werden. Sensoren, Logs, Alarme, Dashboards, Zustandsüberwachung und Predictive-Maintenance-Tools helfen, früher zu reagieren und schneller zu diagnostizieren.
Frühwarnung ist besonders nützlich bei Vibration, Temperaturanstieg, Druckänderung, Spannungsschwankung, Fehlercodes oder Kommunikationsinstabilität. Handeln auf solche Signale reduziert Reparaturzeit und Ausfallwirkung.
Troubleshooting-Verfahren standardisieren
Reparaturgeschwindigkeit verbessert sich, wenn Techniker klare Verfahren befolgen. Checklisten, Fehlerbäume, Wartungshandbücher, Schaltpläne, Ersatzteillisten, Software-Recovery-Schritte und Eskalationsregeln reduzieren Unsicherheit.
Standardverfahren machen Leistung über Techniker und Schichten hinweg konsistenter und stellen sicher, dass dasselbe Problem jedes Mal zuverlässig behandelt wird.
Zugang zu Ersatzteilen und Werkzeugen verbessern
Viele Reparaturen verzögern sich nicht wegen schwieriger Fehler, sondern weil Teil, Werkzeug, Passwort, Softwareimage, Kabel oder Prüfgerät fehlen. Reparaturkits und kritische Ersatzteile verkürzen die Wiederherstellung deutlich.
Für verteilte Standorte helfen lokale Ersatzteile, regionale Servicezentren oder modulare Austauschstrategien gegen Reise- und Versandverzug. In digitalen Systemen erfüllen fertige Backups und Konfigurationsvorlagen eine ähnliche Funktion.
Grenzen und Fehlgebrauch von MTTR
Obwohl MTTR nützlich ist, sollte sie nicht der einzige Wartungsindikator sein. Eine niedrige MTTR bedeutet nicht immer ein zuverlässiges System; vielleicht ist das Team nur gut darin, wiederkehrende Fehler zu reparieren. Wenn dasselbe Asset weiter ausfällt, bleibt die Grundursache relevant.
MTTR kann auch Streuung verbergen. Ein Durchschnitt kann akzeptabel wirken, obwohl wenige kritische Vorfälle deutlich länger dauern. Wichtige Systeme sollten nach Zeitverteilung, schlimmsten Fällen, Wiederholfehlern und Hochrisikoanlagen getrennt geprüft werden.
Fehlervermeidung nicht ignorieren
Reparaturgeschwindigkeit ist wichtig, aber vermeidbare Ausfälle zu verhindern ist meist besser. Vorbeugende Wartung, Zustandsüberwachung, Designverbesserung, richtige Installation, Bedienerschulung und Umweltschutz reduzieren Ausfallhäufigkeit.
Eine starke Wartungsstrategie balanciert schnelle Reparatur und langfristige Zuverlässigkeit. MTTR zeigt, wie schnell Teams sich erholen, erklärt aber ohne Ursachenanalyse nicht, warum Ausfälle entstehen.
Nicht ohne Kontext vergleichen
MTTR-Vergleiche zwischen sehr unterschiedlichen Systemen können irreführen. Ein einfacher Sensortausch ist nicht mit Turbinenreparatur, Netzwerkausfall, Aufzugsstörung oder Datenbankwiederherstellung vergleichbar. Jeder Asset-Typ hat eigene Komplexität, Risiken, Zugangsbedingungen und Anforderungen.
Sinnvolle Vergleiche erfolgen innerhalb ähnlicher Gerätegruppen, ähnlicher Servicebedingungen oder desselben Assets über die Zeit. So erkennt man echte Verbesserungen statt unfairer Leistungsurteile.
Best Practices für die praktische Nutzung
Um MTTR wirksam zu nutzen, sollten Organisationen die Kennzahl klar definieren, zuverlässige Daten sammeln, Ursachen langer Reparaturen analysieren und Ergebnisse in Verbesserungsmaßnahmen überführen. Die Kennzahl soll Entscheidungen unterstützen, nicht nur Berichte füllen.
Start- und Endpunkte definieren
Jede Organisation muss festlegen, wann Reparaturzeit beginnt und endet. Sie kann mit Fehlermeldung, Ticketöffnung, Technikerankunft oder Start der aktiven Reparatur beginnen und mit Neustart, abgeschlossenen Tests oder Benutzerbestätigung enden.
Die gewählte Definition muss zum Messziel passen. Für Kundenserviceverbesserung ist gesamte Stillstandszeit relevanter; für technische Effizienz ist aktive Reparaturzeit geeigneter.
Daten segmentieren
Statt eine breite MTTR für alle Assets zu berechnen, sollten Teams nach Gerätetyp, Standort, Fehlerkategorie, Schweregrad, Team, Schicht, Lieferant oder Systemfunktion segmentieren. Dadurch wird die Kennzahl nützlicher und handlungsorientierter.
Ein Standort kann feststellen, dass Pumpen schnell repariert werden, Aufzüge aber wegen ausgelagerter Ersatzteile langsam sind. Ein IT-Team kann sehen, dass Anwendungsfehler schnell, Netzwerkvorfälle aber langsamer gelöst werden. Segmentierung zeigt den richtigen Startpunkt.
MTTR mit Ursachenanalyse verbinden
Bei hohen Reparaturzeiten sollten Teams die Gründe untersuchen. War der Fehler schwer zu diagnostizieren? Fehlte Dokumentation? War das Ersatzteil nicht verfügbar? Verzögerte sich die Freigabe? Gab es keinen Remote-Zugang? War die Anlage schwer erreichbar?
Ursachenanalyse macht MTTR von einer passiven Messung zu einem aktiven Verbesserungswerkzeug. Langfristig reduziert dies Stillstand, erhöht Zuverlässigkeit und macht Wartungsplanung vorhersehbarer.
FAQ
Was bedeutet Mean Time to Repair?
Mean Time to Repair ist die durchschnittliche Zeit, die benötigt wird, um ein ausgefallenes Asset, System, Gerät oder einen Dienst wieder in normalen Betrieb zu bringen. Sie wird berechnet, indem die gesamte Reparaturzeit durch die Anzahl der Reparaturereignisse geteilt wird.
Ist MTTR dasselbe wie Stillstandszeit?
Nicht immer. MTTR konzentriert sich meist auf Reparaturdauer, während Stillstandszeit auch Erkennung, Meldeverzug, Wartezeit, Ersatzteilverzug, Freigabe und Neustart umfassen kann. Die Organisation muss genau definieren, was enthalten ist.
Was ist ein guter MTTR-Wert?
Ein guter Wert hängt von Gerät, Branche, Serviceanforderung und Schwere des Fehlers ab. Für einen digitalen Neustart können Minuten erwartet werden, bei komplexen Industrieanlagen können Stunden angemessen sein. Der beste Vergleich erfolgt oft mit ähnlichen Assets oder früherer Leistung.
Wie kann ein Unternehmen MTTR senken?
Ein Unternehmen kann MTTR senken durch besseres Monitoring, schnellere Fehlererkennung, standardisiertes Troubleshooting, Technikerschulung, verfügbare kritische Ersatzteile, Ferndiagnose, bessere Dokumentation und einfacheren Anlagenzugang.
Warum ist MTTR für Zuverlässigkeit wichtig?
MTTR ist wichtig, weil Reparaturgeschwindigkeit Stillstand und Verfügbarkeit direkt beeinflusst. Auch zuverlässige Systeme können ausfallen; schnelle Wiederherstellung reduziert betriebliche Auswirkungen, Serviceunterbrechung, Produktionsverlust und Kundenunzufriedenheit.
Was ist der Unterschied zwischen MTTR und MTBF?
MTTR misst, wie lange Reparaturen nach einem Ausfall dauern. MTBF misst die durchschnittliche Zeit zwischen Ausfällen. MTTR fokussiert Wiederherstellungsgeschwindigkeit, MTBF Ausfallhäufigkeit. Beide Kennzahlen helfen, Zuverlässigkeit und Verfügbarkeit zu verstehen.







